仔细看了DeepSeek-OCR论文,二维信息优势。在大模型时代,汉字强于英文又多了个证据
1. OCR图片文字识别,本身意思不大。DeepSeek-OCR就是识别率高,但也不是高到不可复制,主要还是用少得多的视觉token,就实现了很高识别率。100个token,就能基本代表一个1000个token的文字图片页面,还原出97%,10倍压缩率几乎没有丢失信息。
2. 有些专家认为,应该把我们日常输入给大模型的较长的提示词,用图片编码,需要的token数量就少多了,推理训练效率会高得多。这是因为token数量在大模型内部是平方关系,要对所有token相互建立关联。这里就有个很有意思的问题,为什么用图像来放文字,居然能比文本有更好的压缩率?
3. 先要理解基础知识:文本压缩率。一种是无损压缩,基于香农信息熵的结论。英文字母出现概率各有不同,纯文本无损压缩的理论极限是0.7–0.8 bit/字符,经常出现的用少数bit代表,出现多的单词组合可以进一步优化。汉字纯文本压缩的理论极限是4.2 bit/汉字(或者0.53 byte/汉字)。如“的”的出现概率最高,有4%,可以用“100”这3bit来代表它;“一”的概率有2%也很高,用“1010”4个bit代表;“龘”概率极低,用1111111010来代表,10个bit。这种只考虑单字出现概率的,汉字编码大约是9.6比特每字。考虑更多词语组合,极限就是4.2比特。
4. 可见,如果搞纯文本无损压缩,单个汉字需要的bit数量比英文要高多了。这是自然的,汉字数量本来就是比英文字符多得多。实践中,英文纯文本的无损压缩率远高于中文;若统一用“每原始字节”做分母,英文纯文本压缩可轻松到 8–10倍,中文通常在 2–5倍区间。现在最厉害的纯文本压缩算法zpaq,对英文可到0.9 bit/字符,有9倍压缩率,同样算法对中文是约4.5 bit/汉字,压缩率5倍。
5. 但这是无损压缩,英文相对汉字有优势。如果有损压缩,中文就比英文有优势了。一个常见应用是对一段文字生成“摘要”。如果删30%字数,中文新闻摘要的“召回率”下降约 8 %,英文下降 15–20%;中文用70%字数就能有95%的关键信息召回,而英文 用70%字数只有85%召回,15%丢了。理论上,中文是语素文字,一个字就能承载完整语素;英文是音素拼写,一个词由多个字母组成,删掉字母就会丢信息。在高删率场景下,中文优势明显,删字不删义。
6. 个人经常干这种事,先写一段中文,但发现表述太啰嗦,删掉很多文字意思表达完全没少。而对英文干这种事,就不容易了。再深入思考,显然是因为中文是二维的,英文字母是一维的。而这,在大模型token压缩里,就能转成二维信息优势,说明用图片去理解信息,会有更高的压缩比。
7. DeepSeek-OCR的理论成果是,把文本token信息转成图片后,token数量可以有10倍的压缩,1000个文本token变100个视觉token,维持97%的高信息还原。一种想法是,把1000个文本token,用更少的文本token来压缩代表,在大模型里推理,会是什么效果?这就是DeepSeek-OCR成果震撼的地方。之前Q-VAE/VQ-GAN这么干了,文本token数量减成十份之一,只有60–75%的信息能还原!这两种都是把token离散理解的,在文本任务里,常把1000 个字符压成100个离散索引,但解码时仅用decoder自回归,字符级准确率约60–75%。而DeepSeek-OCR做10倍token压缩能有97%!
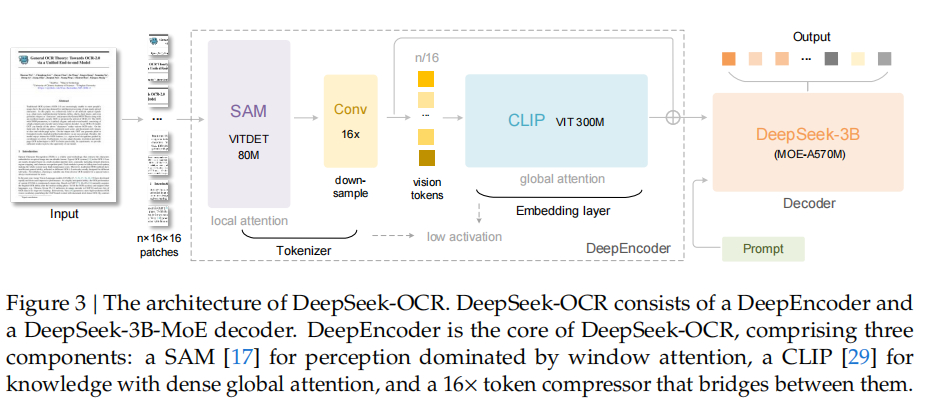
8. 这个哲学意思是什么?文字转成图片,就是文字信息从一维变二维了,类似英文变中文了。DeepSeek-OCR会把图片切成16*16的小方块,一个个扫过去处理。这就类似于在看二维汉字,但方块里的信息要复杂多了。对这种二维信息,进行压缩,就能有很好的压缩比例。
9. DeepSeek-OCR能对图片二维文字信息能进行10倍的“高保真”压缩,因为它有个大招:只保留关键信息。其中的DeepEncoder不是把整页文字全编码,而是把高频细节、生僻符号、行列对齐这些“高熵”的关键残差信息放进 token;而低熵背景、重复样式被简单地处理掉了,因为负责解码的是个很强的有30亿个参数的大语言模型(LLM),这个LLM靠着对语言的熟悉能把这些常见信息全都猜出来!LLM猜不出的,才让DeepEncoder花很多token编码。简单类比理解,就是二维的中文,用少数文字猜意思,比一维的英文要厉害多了。
评论列表