[LG]《Can Aha Moments Be Fake? Identifying True and Decorative Thinking Steps in Chain-of-Thought》J Zhao, Y Sun, W Shi, D Song [Northeastern University & UC Berkeley] (2025)
近期大型语言模型(LLMs)在推理时常用“思维链”(Chain-of-Thought, CoT)生成长推理步骤,传统上认为这些步骤忠实反映了模型的内在思考过程。然而,论文《Can Aha Moments Be Fake? Identifying True and Decorative Thinking Steps in Chain-of-Thought》指出,很多CoT步骤实际上并未真正影响模型最终预测,存在大量“装饰性思考”步骤,只是表面上的“假装推理”。
核心贡献:
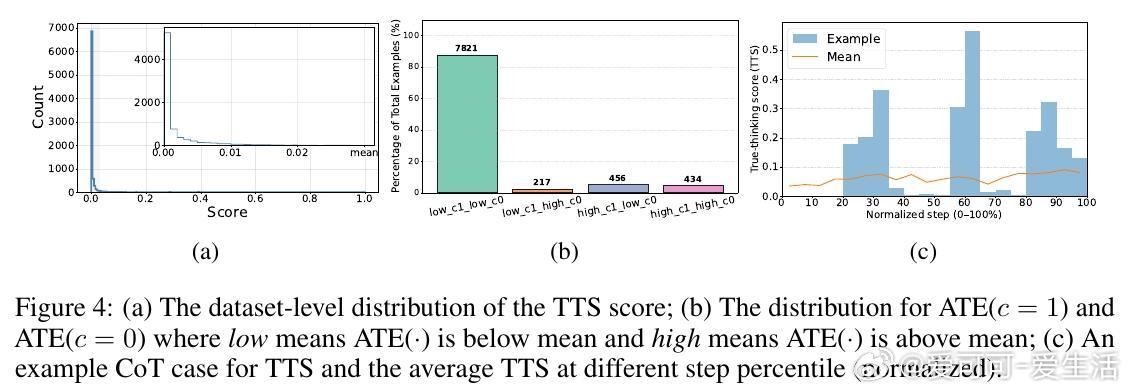
1. 提出True Thinking Score(TTS):利用因果推断方法,衡量每一步推理对最终答案的因果影响。TTS结合了“必要性”(在完整上下文中,去掉该步骤是否影响答案)和“充分性”(在扰动上下文中,该步骤是否单独能驱动正确答案)的双重测试,更全面判断步骤是否真实参与思考。
2. 发现推理步骤交错存在真思考与装饰思考:
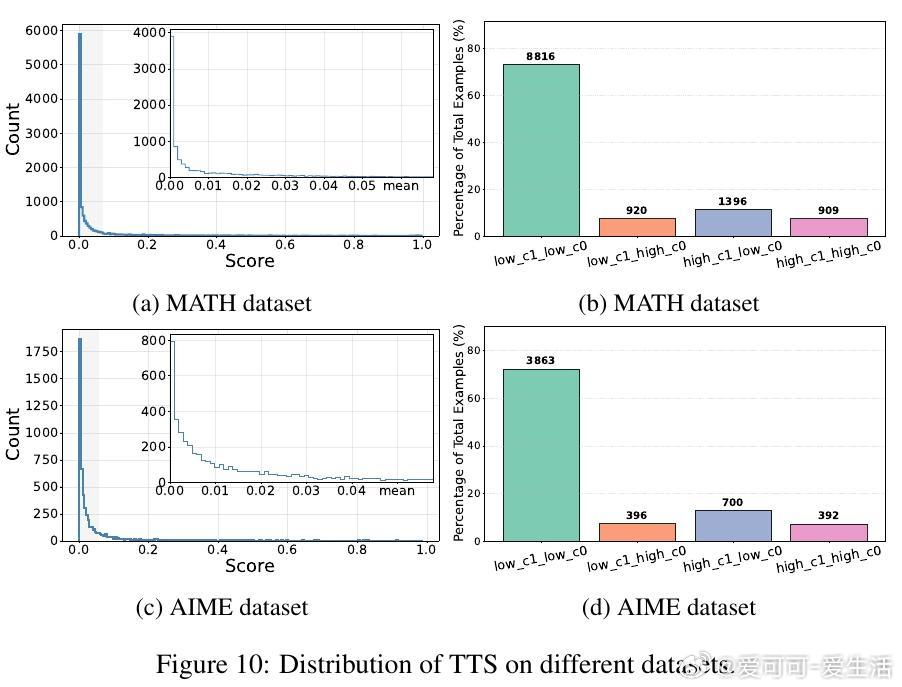
- 绝大多数CoT步骤TTS极低,仅少数(例如AIME数据集下Qwen-2.5模型仅约2.3%步骤TTS≥0.7)是真正影响预测的步骤。
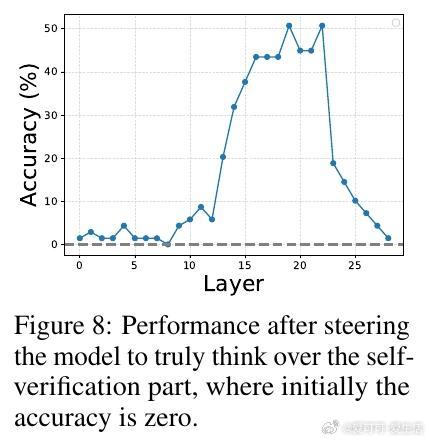
- 即便是“自我验证”或“顿悟”步骤(即俗称的“aha moments”),也可能完全是装饰性步骤,模型并未真正执行这些验证。
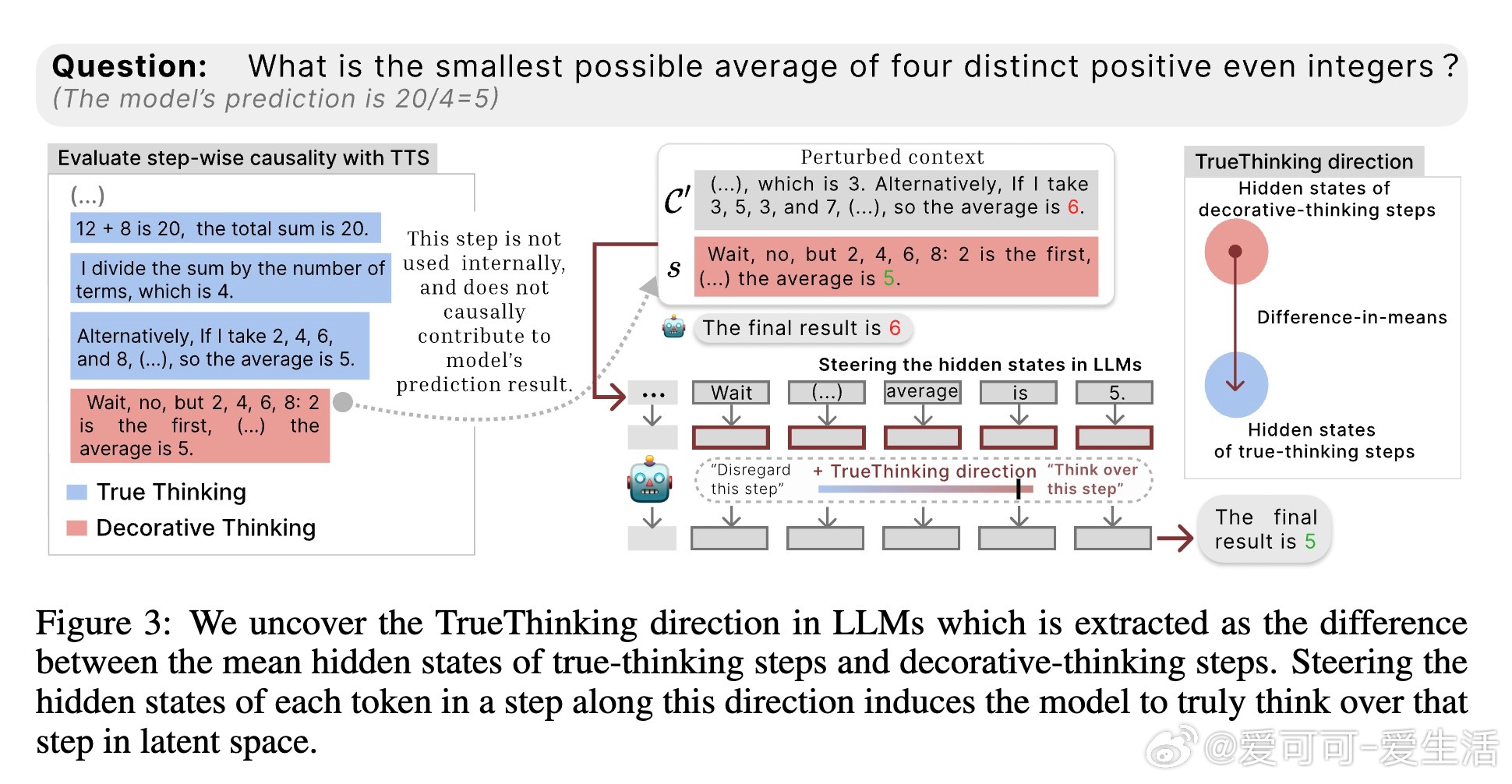
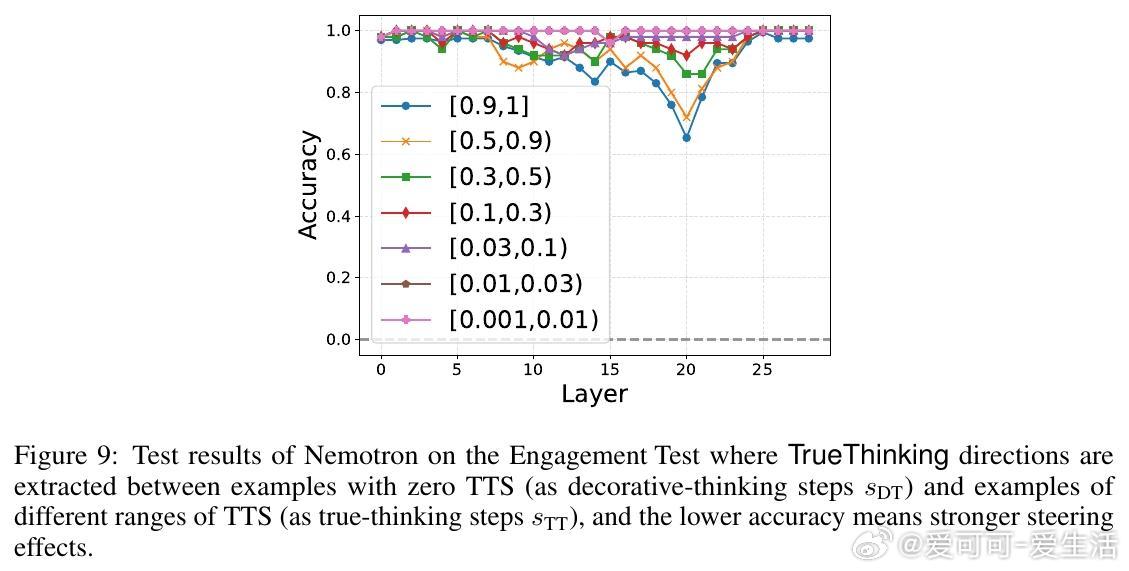
3. 揭示真思考方向(TrueThinking direction):
- 在模型的隐空间中,存在一条线性方向区分真思考步骤和装饰思考步骤。
- 通过沿该方向“操控”隐状态,可以强制模型真正执行或忽略某一步推理,验证了该方向的因果效应和意义。
4. 方法与实验设计:
- 采用三款开源推理模型(Qwen-2.5-7B、Llama-3.1-8B、Nemotron-1.5B),在AMC、AIME、MATH数学推理数据集上评估。
- 利用微小数值扰动制造对比,结合早期退出答题机制,量化单步推理对答案的影响。
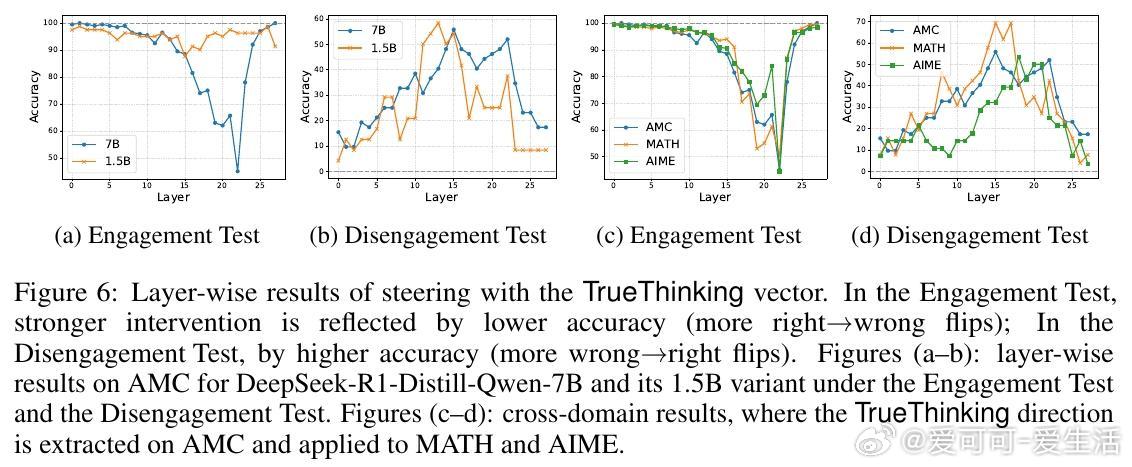
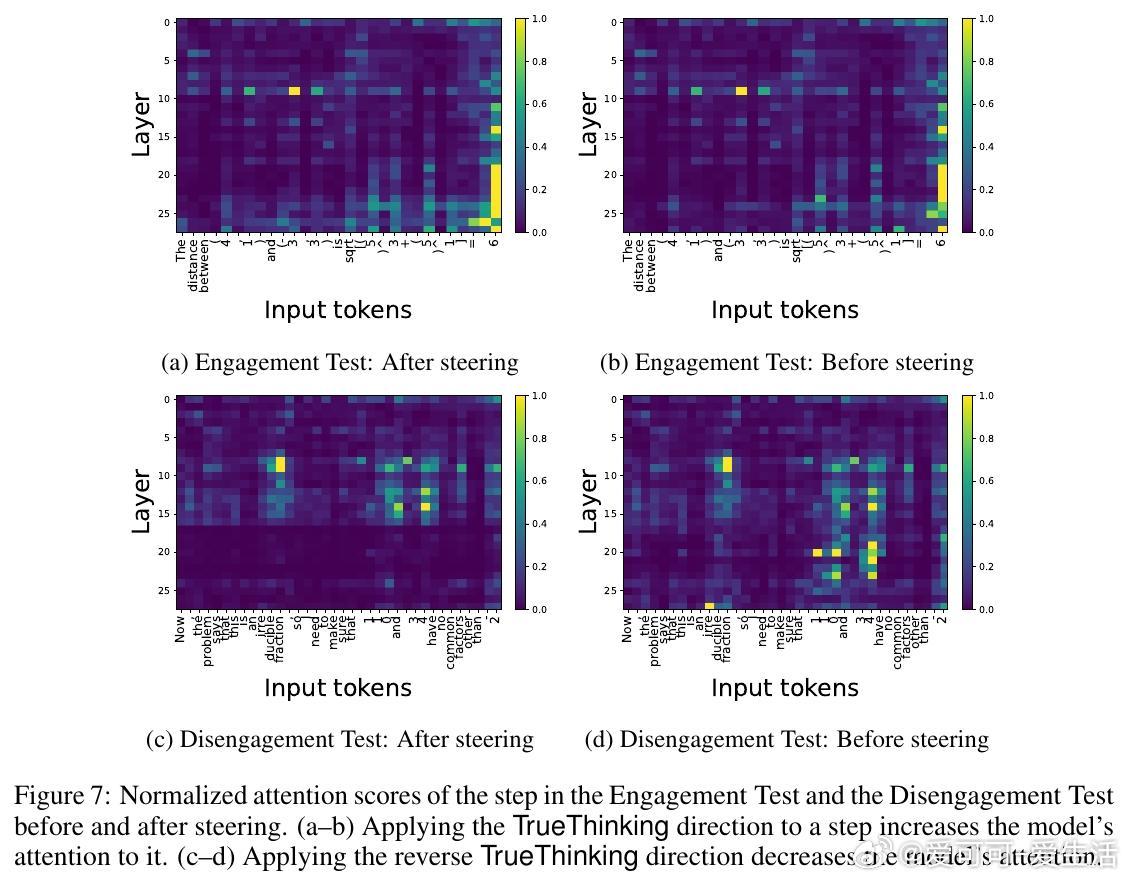
- 设计“参与测试”(Engagement Test)和“放弃测试”(Disengagement Test)通过隐空间操控方向验证推理步骤的真实性。
5. 重要发现与意义:
- CoT中大部分步骤为“装饰性思考”,模型只是“说”而未“做”,这挑战了CoT作为模型内在推理透明窗口的假设。
- 这影响模型推理效率,也带来安全监控风险,因为监控CoT无法确保捕捉真实思考过程。
- 通过操控真思考方向,可提升模型对自我验证步骤的真实执行,未来可用于优化推理效率和可信度。
6. 局限与未来方向:
- 因果框架为近似探测,非完美还原全部思考路径。
- 真思考方向非最优,需进一步研究其几何结构和更有效的操控方法。
- 受限于计算资源,未能测试更大规模模型,未来可扩展验证。
总结:本文创新性地从因果视角细粒度分析了LLM推理中的“真假思考”,揭示了CoT推理的内在复杂性和不完全可信性,提出了可操控的真思考隐空间方向,为提升模型推理透明度、效率和安全性提供了新的理论工具和实践路径。
论文链接:arxiv.org/abs/2510.24941
代码开源:github.com/andotalao24/Identify_true_decorative_thinking
欢迎关注与讨论,共同推动对大模型推理机制的深入理解!