[LG]《GPTOpt: Towards Efficient LLM-Based Black-Box Optimization》J Meindl, Y Tian, T Cui, V Thost... [MIT] (2025)
GPTOpt:基于大语言模型的高效黑盒优化新范式
优化昂贵且无梯度信息的黑盒函数,样本效率至关重要。传统贝叶斯优化(BO)虽有效,但需针对不同问题调参,限制了实用性。大语言模型(LLMs)虽能力广泛,却尚未能胜任连续黑盒优化任务。
本文提出GPTOpt,一种通过大规模合成数据微调LLM的黑盒优化方法。GPTOpt训练于多样的贝叶斯优化轨迹,覆盖多种参数设定与函数空间,借助LLM预训练的强大泛化能力,实现无需调参的通用全局优化。实验证明,GPTOpt在多种基准测试上均超越传统优化器,显示LLM具备高级数值推理与优化潜力。
核心贡献:
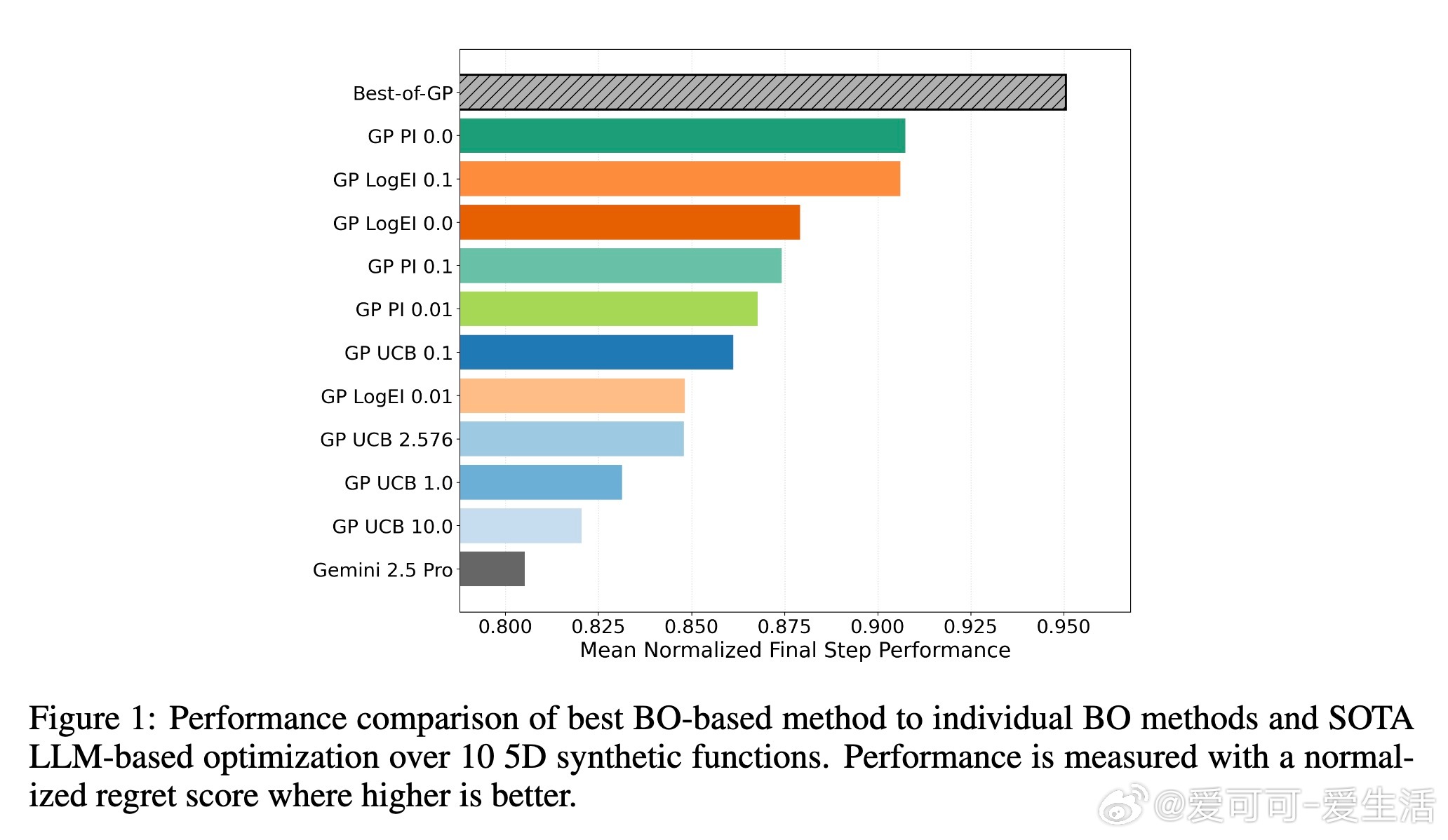
1. 设计多样合成函数生成器(包括高斯过程、随机神经网络、ODE、表达式树及傅里叶表达式)并采集千万级BO专家轨迹。
2. 采用Llama 3.2 3B模型,结合LoRA高效微调,形成优化决策序列化文本输入,利用LLM强大数值表示能力。
3. 推出基于多次前向采样和期望改进的采集函数策略,提升模型推断质量。
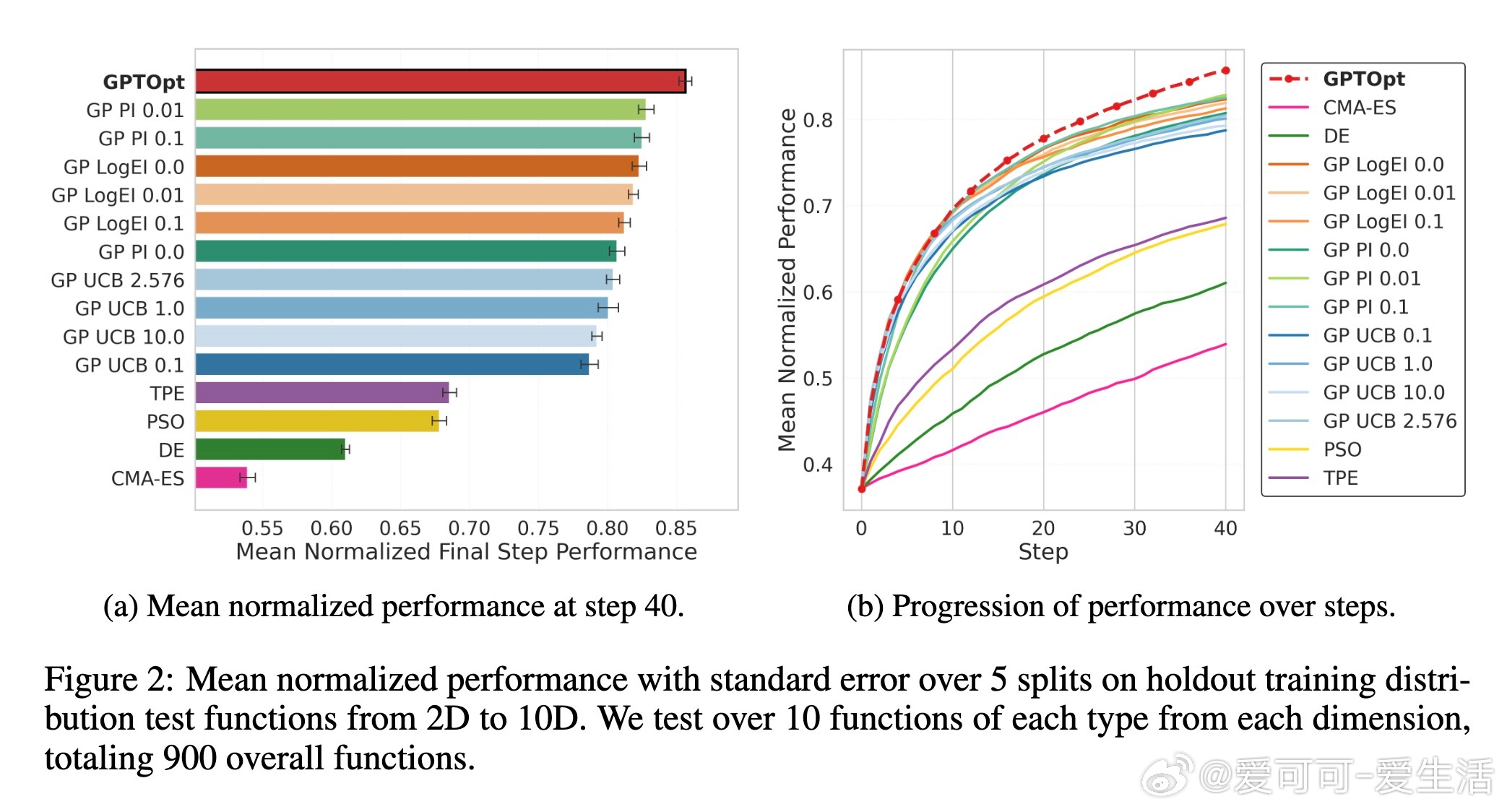
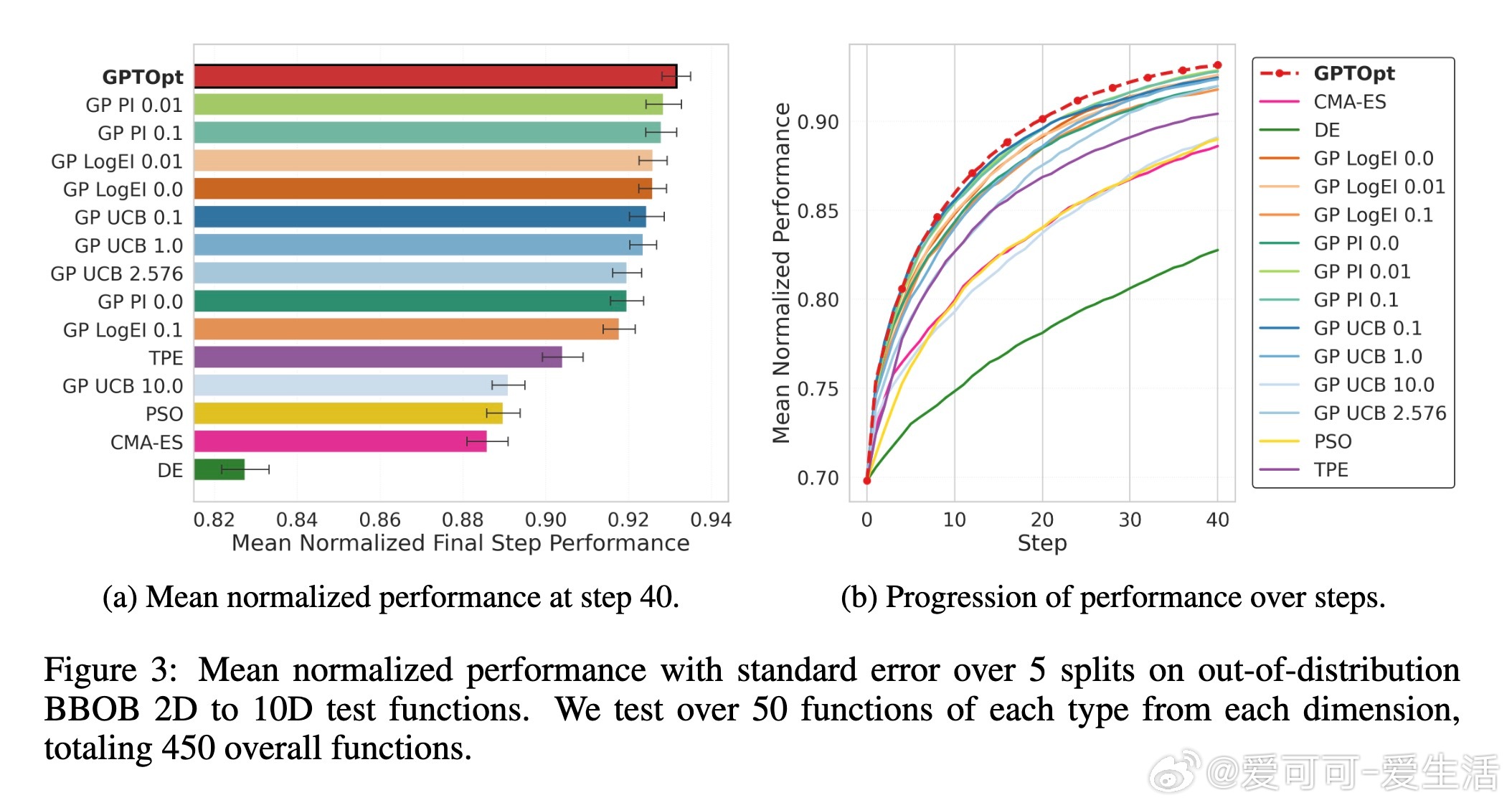
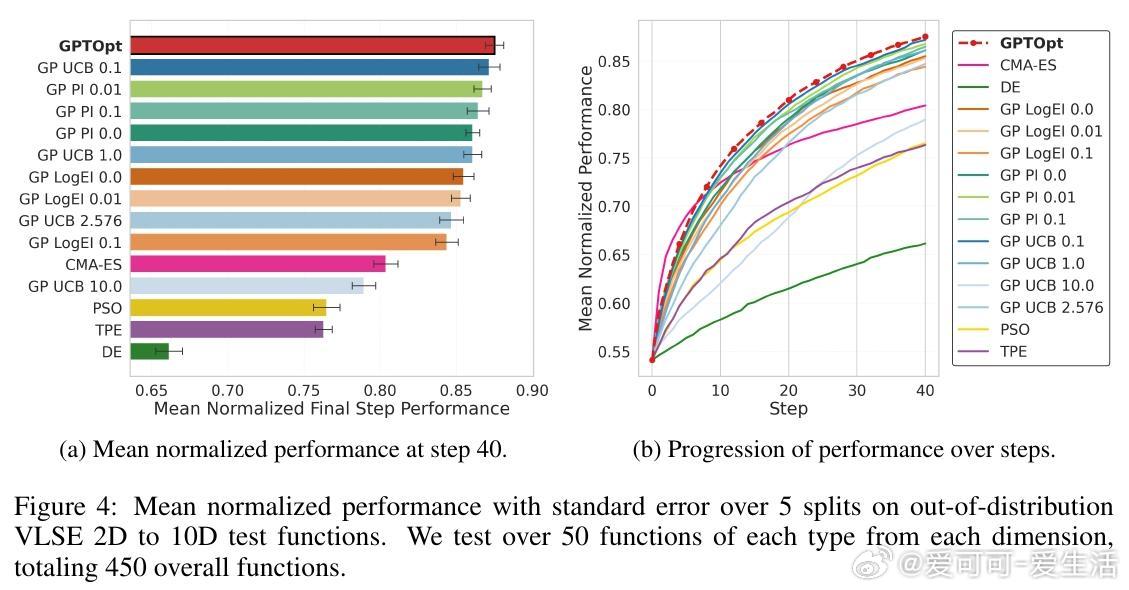
4. 跨多维度(2D-10D)及真实世界基准(如BBOB、VLSE)验证,GPTOpt表现稳健优异,具备强零样本泛化能力。
优势与未来方向:
- 无需手工调参,易用性大幅提升。
- 可扩展至多目标、组合及混合整数优化。
- 可融合语义信息及历史数据,挖掘LLM语义理解优势。
- 期待通过更大规模训练与更大模型进一步提升性能。
总结:GPTOpt为全局黑盒优化注入LLM新活力,开启无需调参的灵活高效优化新时代。
详细论文链接:arxiv.org/abs/2510.25404
黑盒优化 贝叶斯优化 大语言模型 GPTOpt 连续优化 机器学习 人工智能