[CL]《Language Model Behavioral Phases are Consistent Across Architecture, Training Data, and Scale》J A. Michaelov, R P. Levy, B K. Bergen [MIT & UCSD] (2025)
论文系统性地分析了自回归语言模型在训练过程中的行为演变,发现其行为变化呈现出高度一致的阶段性特征,这些特征跨越了模型架构(Transformer、Mamba、RWKV)、训练数据(OpenWebText、The Pile)和规模(从1400万到120亿参数)均保持稳定。
核心发现包括:
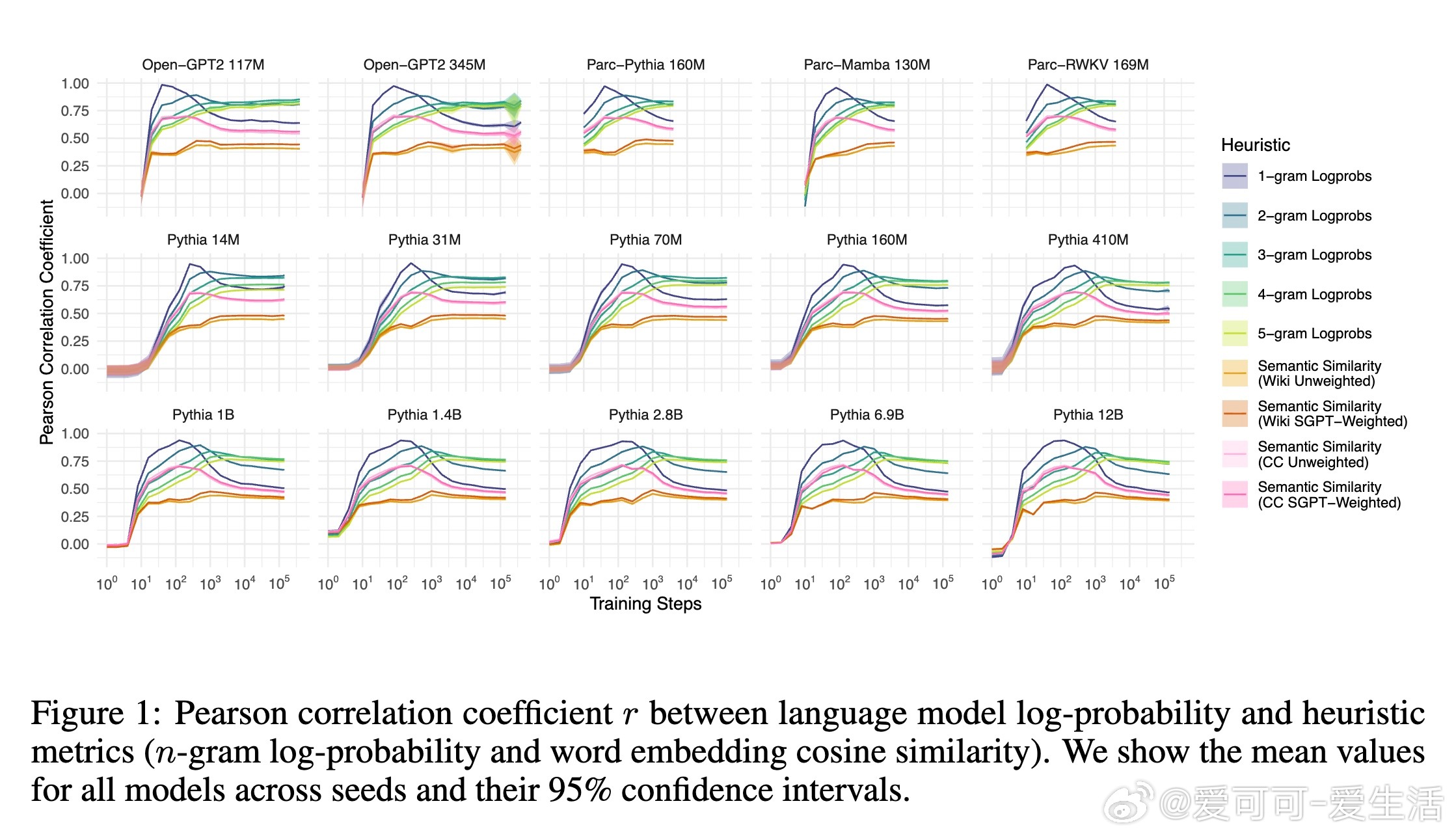
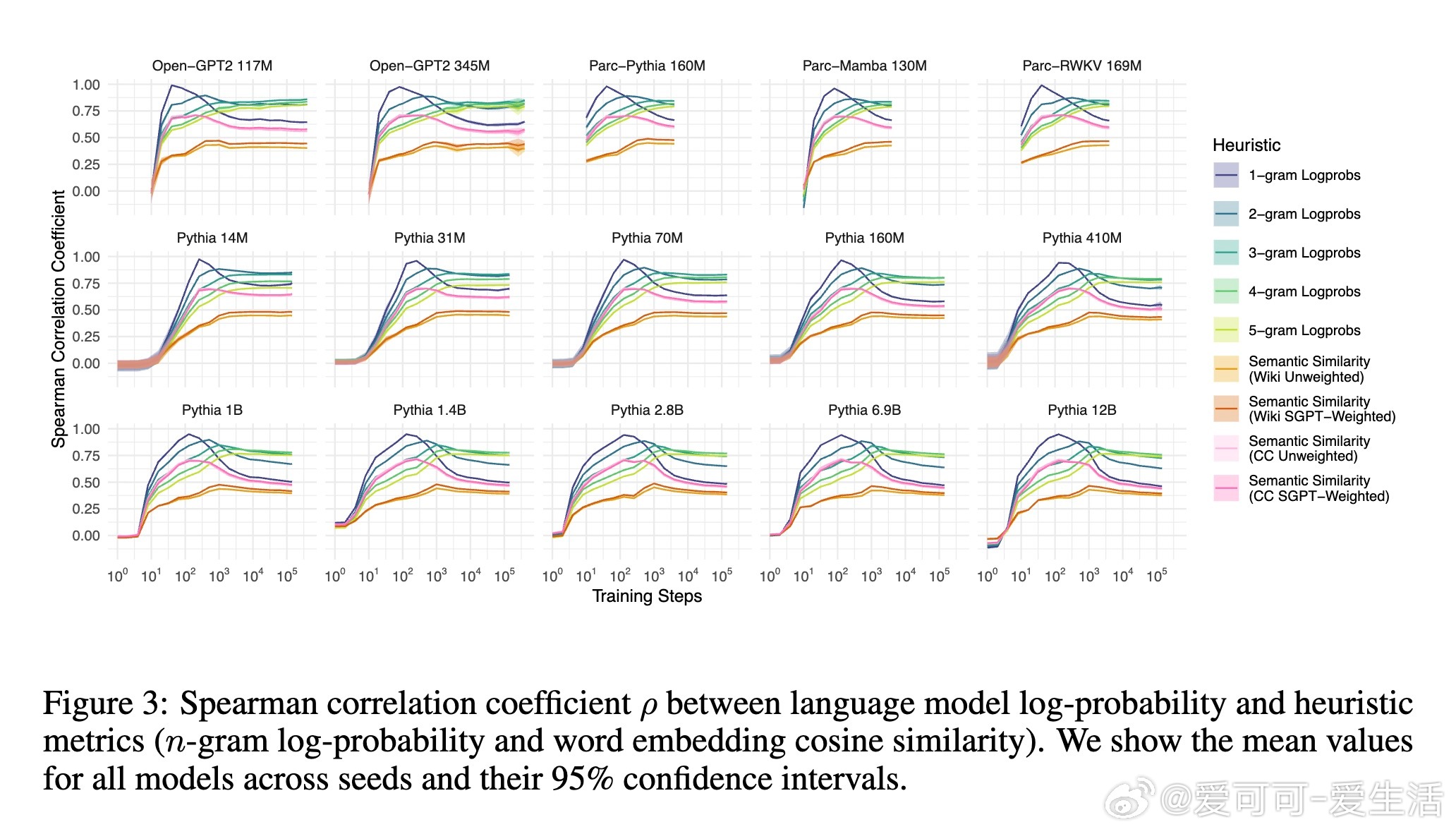
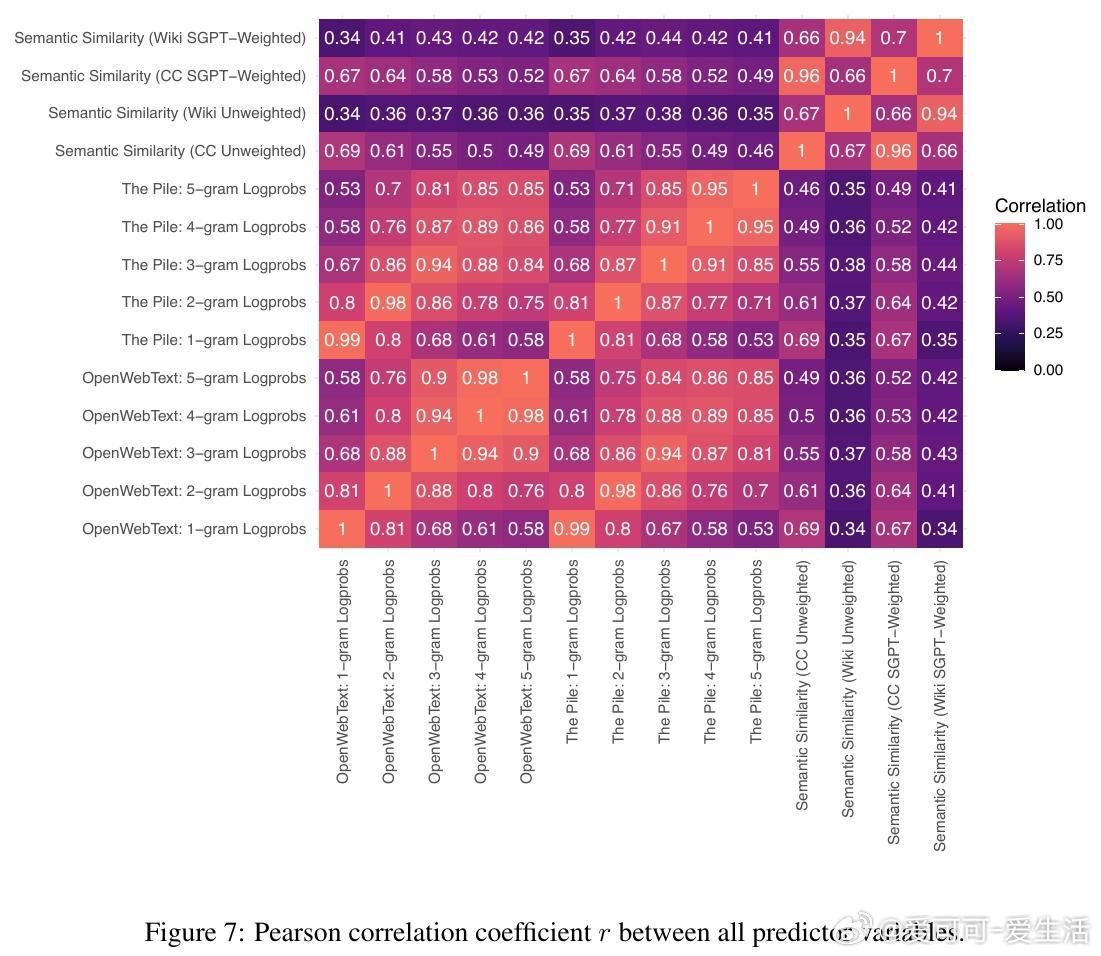
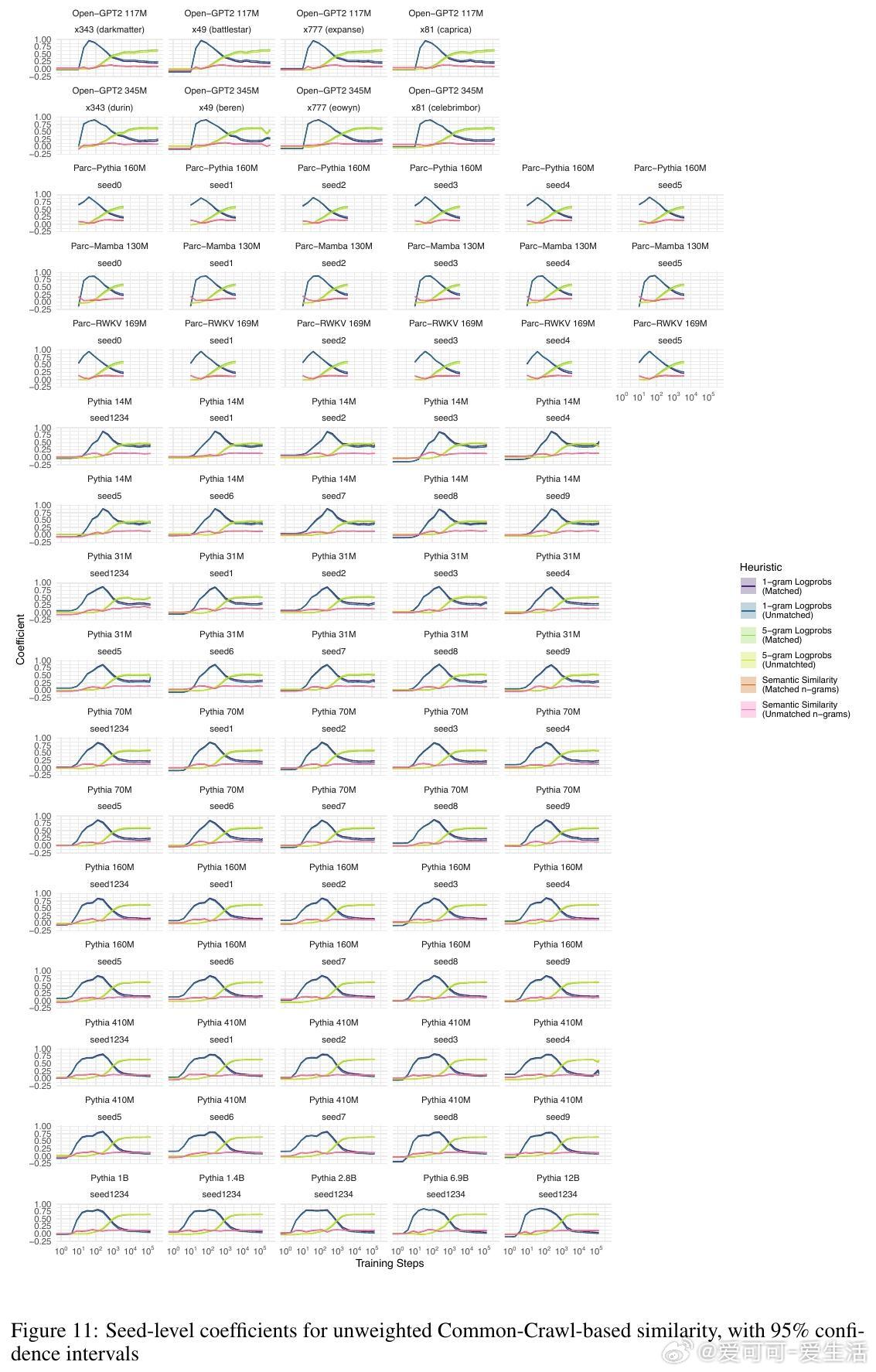
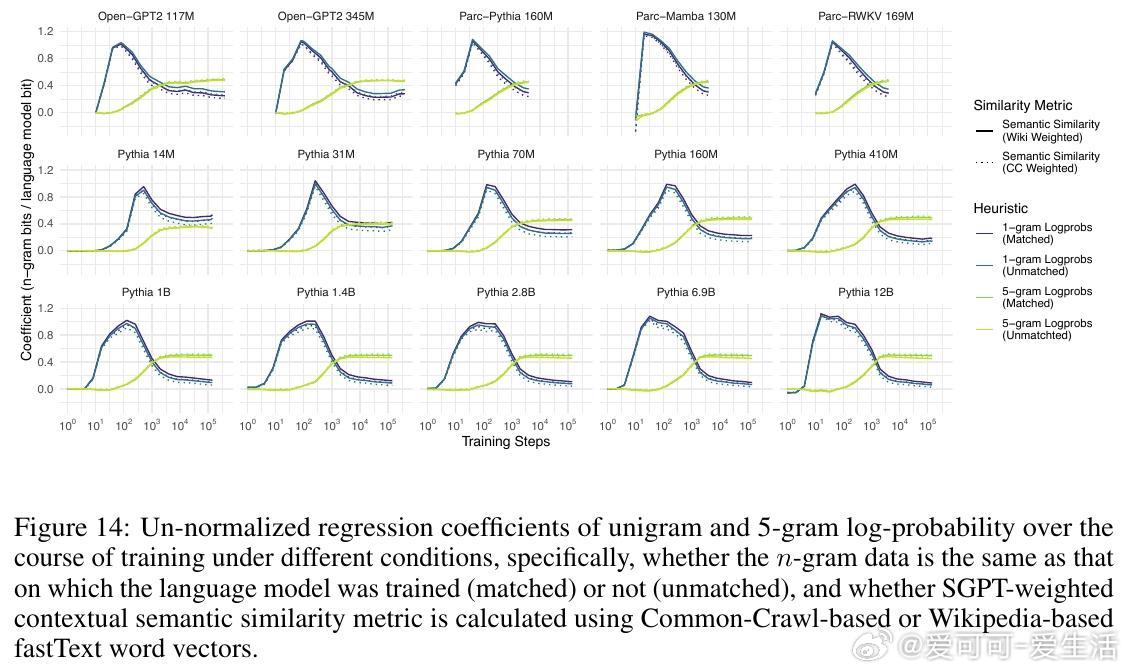
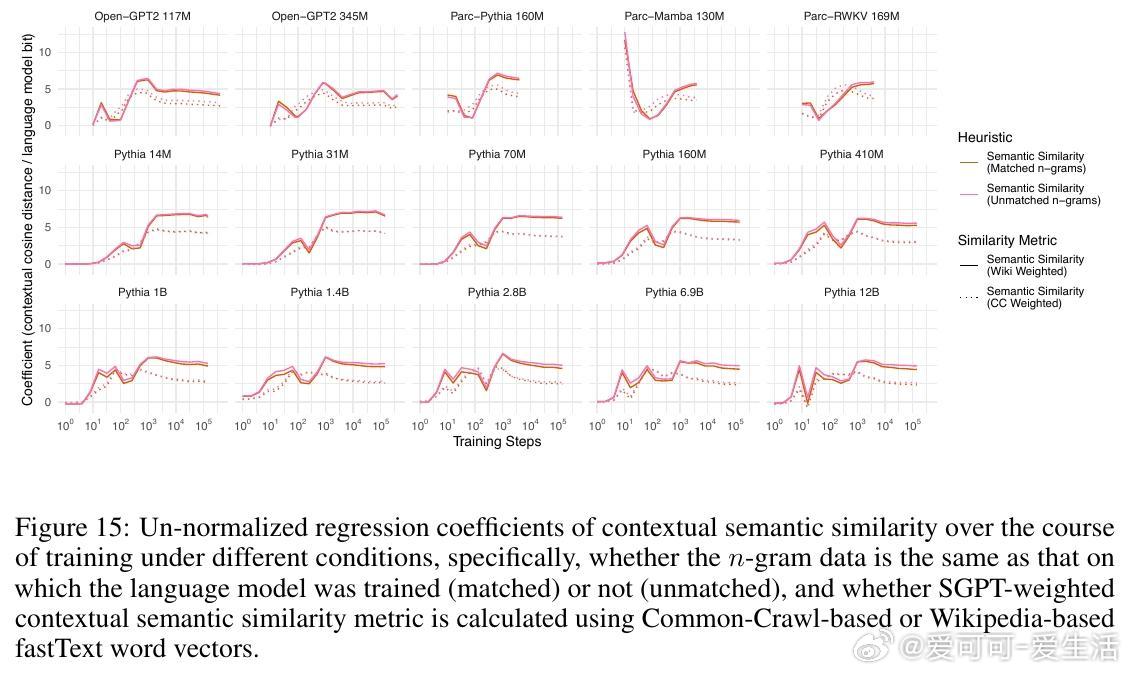
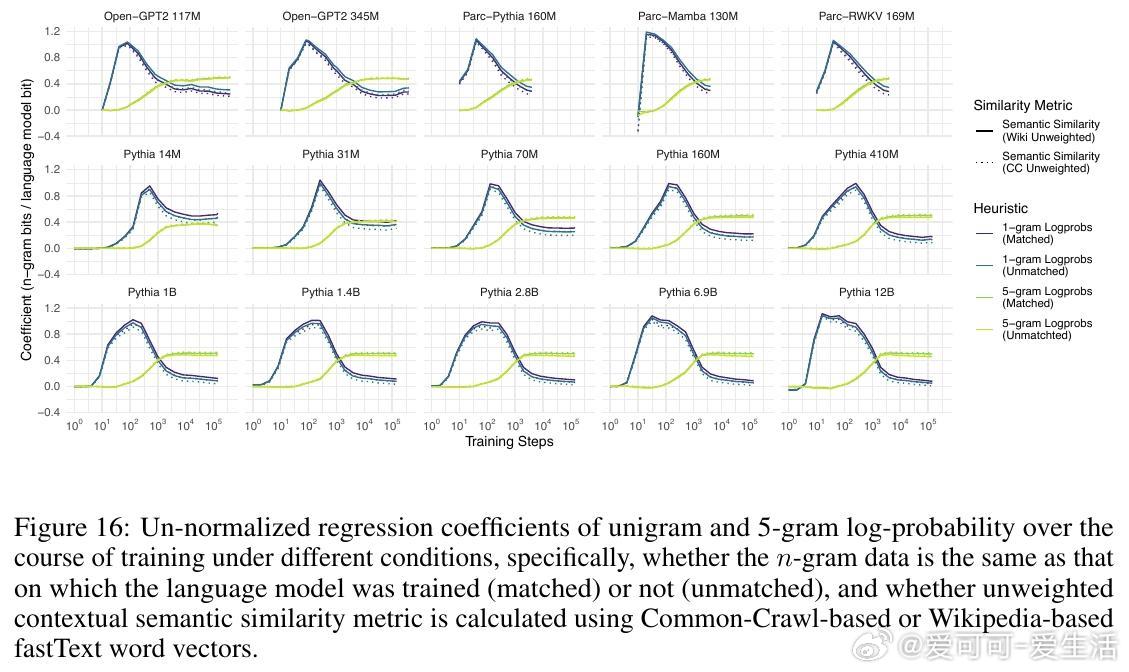
1. 语言模型对单词的预测概率高达98%的变化可以通过三条简单启发式规则解释:单词的一元概率(频率)、n元语法概率以及单词与上下文的语义相似度。
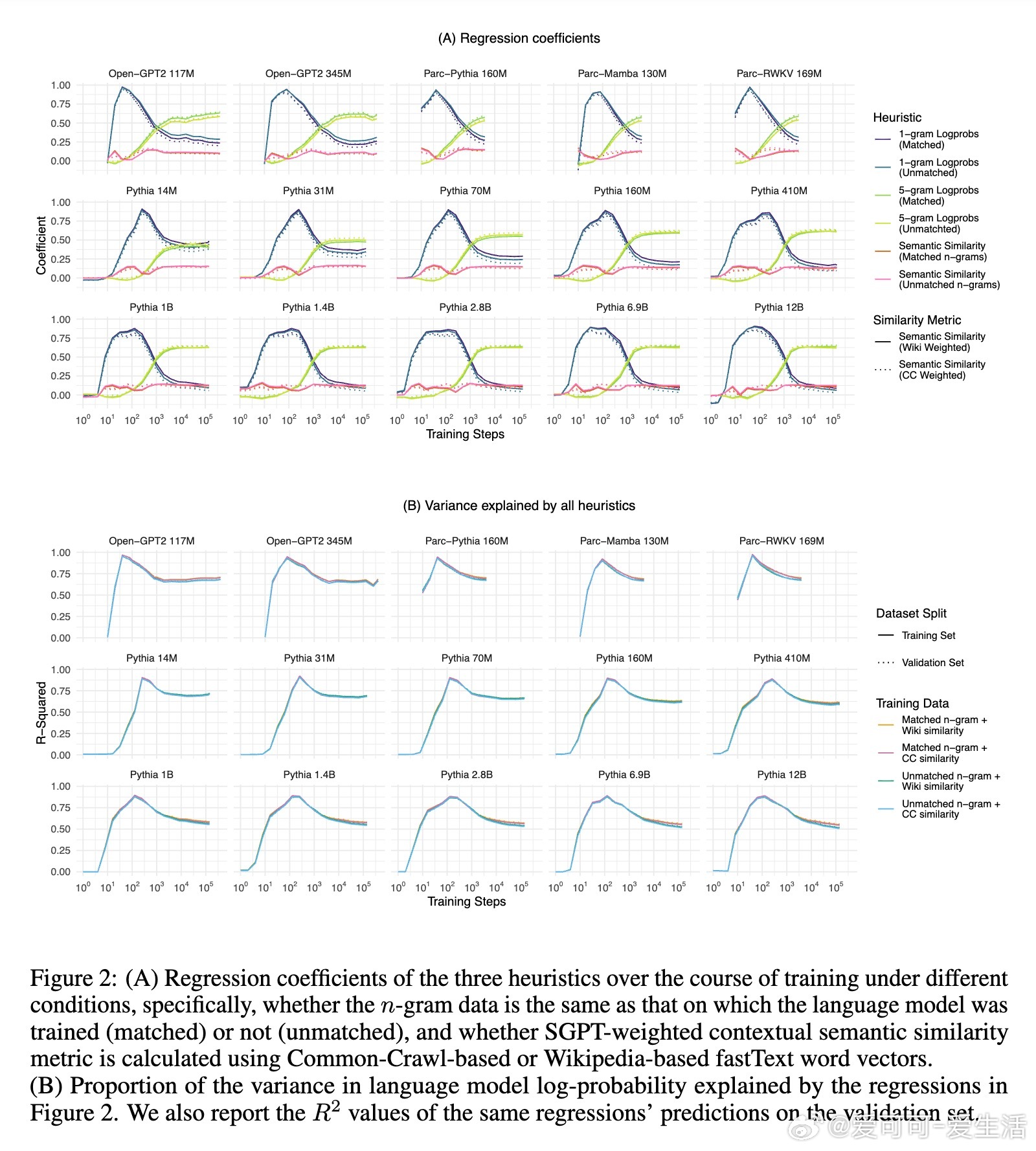
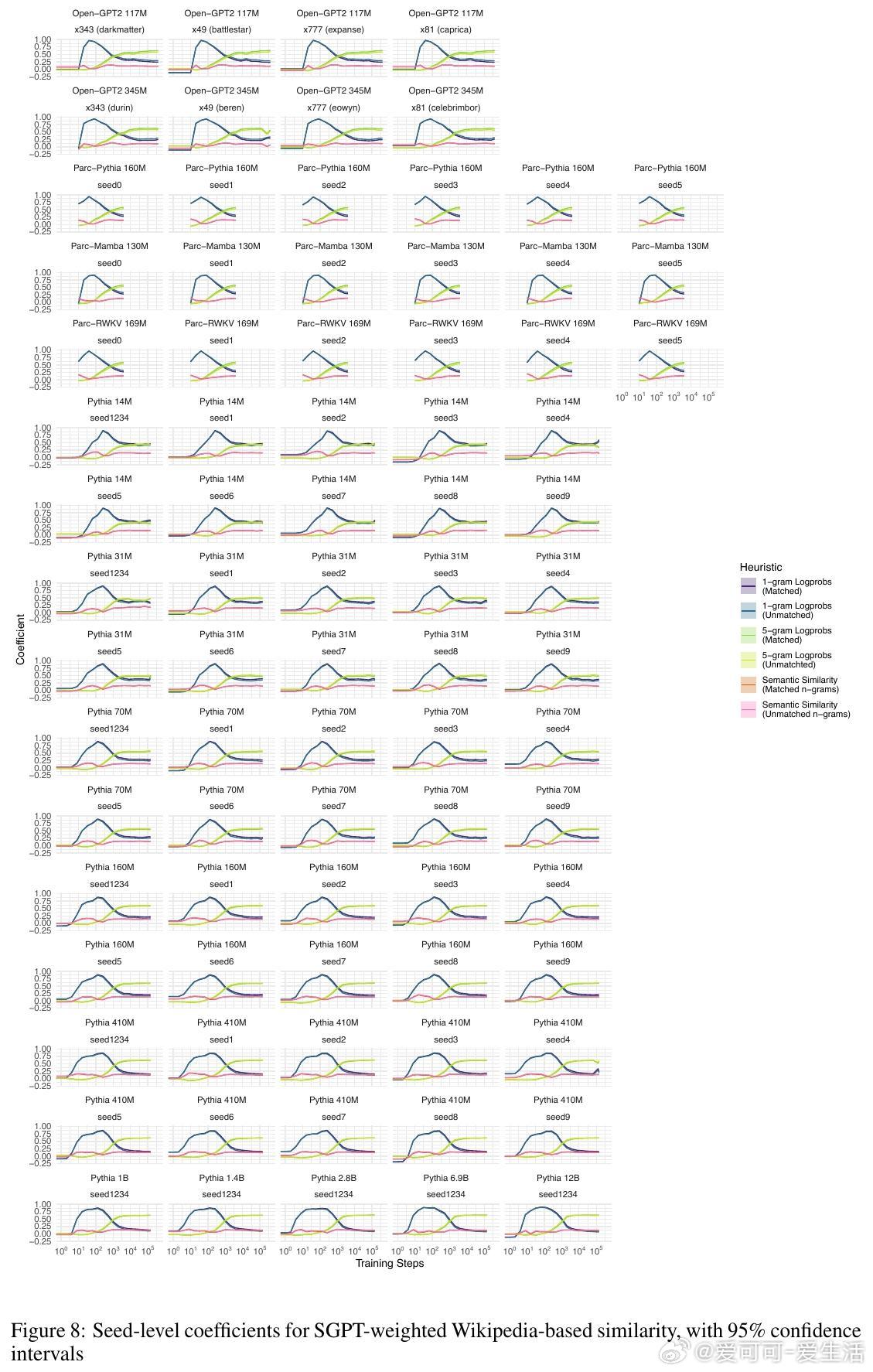
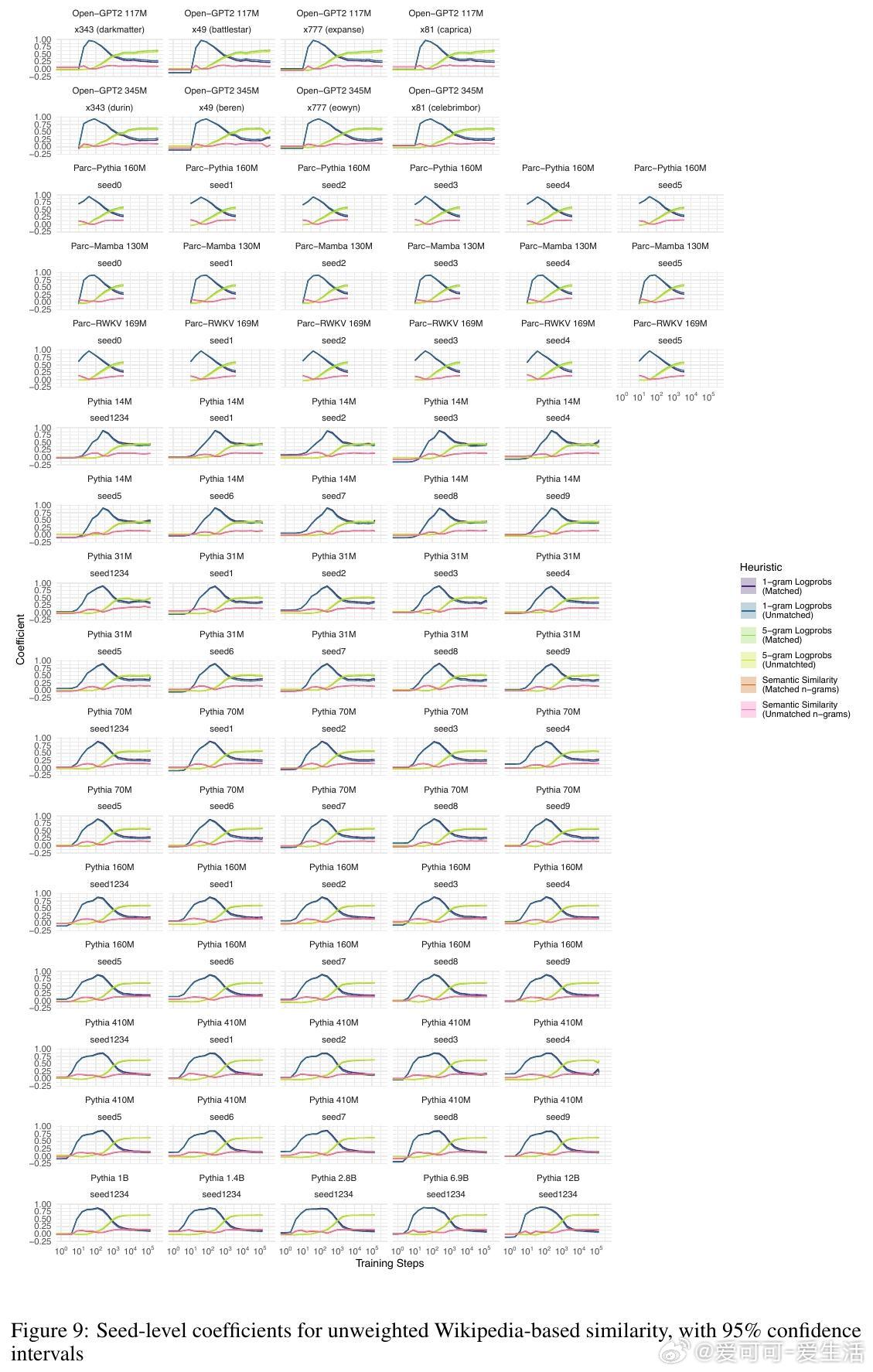
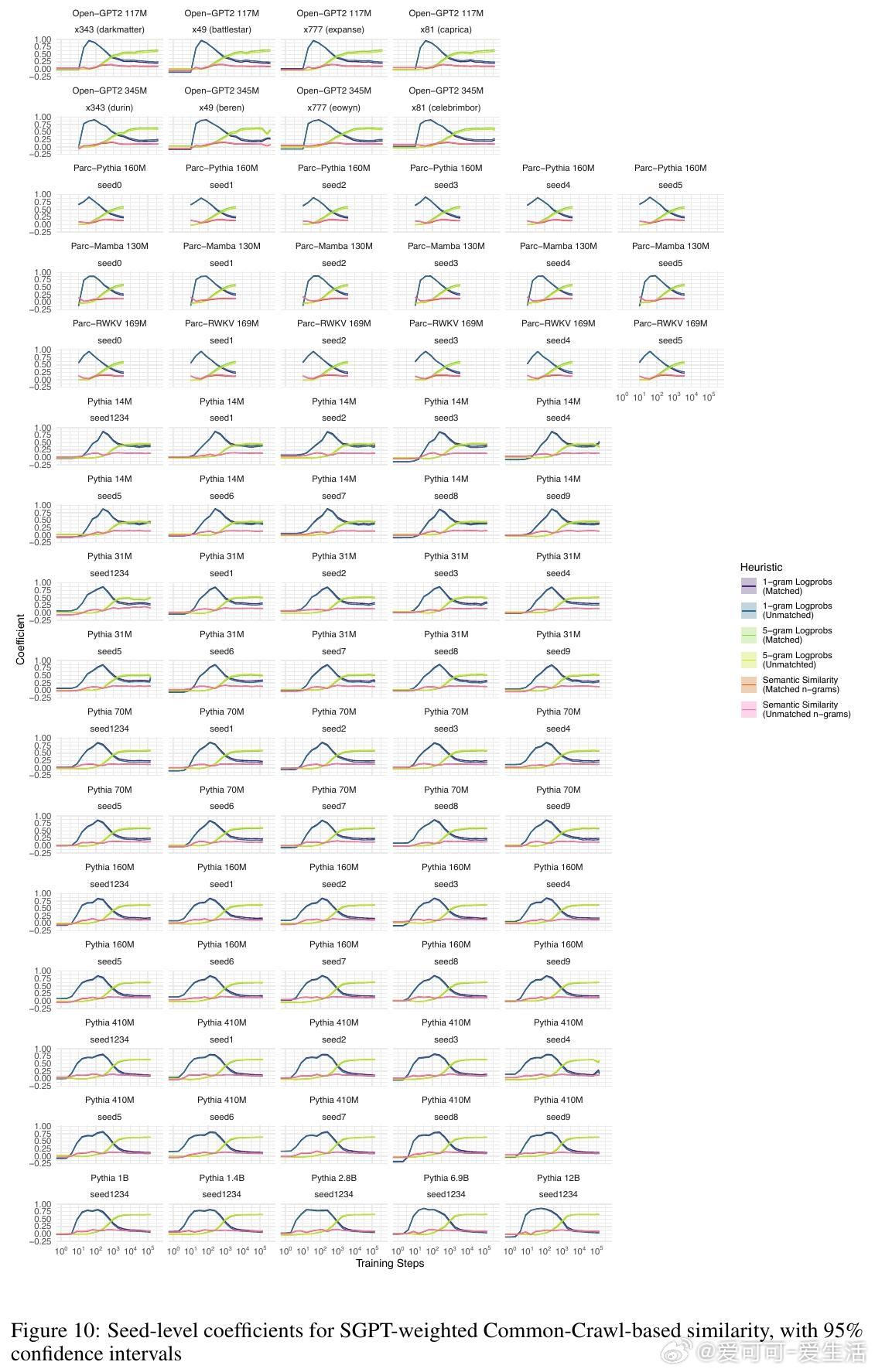
2. 所有模型在训练过程中均表现出对n元语法概率的过拟合趋势,且随着训练步数增加,模型对更高阶n元语法的敏感性逐步增强,而对低阶n元语法的依赖则减弱。大型模型更倾向于利用高阶n元语法关系,而小型模型更多依赖低阶n元语法。
3. 语义相似度与模型预测概率之间存在稳定的相关性,这种关系超出了n元语法隐含的共现信息,表明语言模型在训练中逐渐学习到词汇与上下文的语义关联。
4. 训练过程可划分为三个阶段:初期模型主要受单词频率影响,中期开始更多利用高阶n元语法信息,后期各因素的权重趋于稳定,且大型模型开始展现更复杂的语言理解能力。
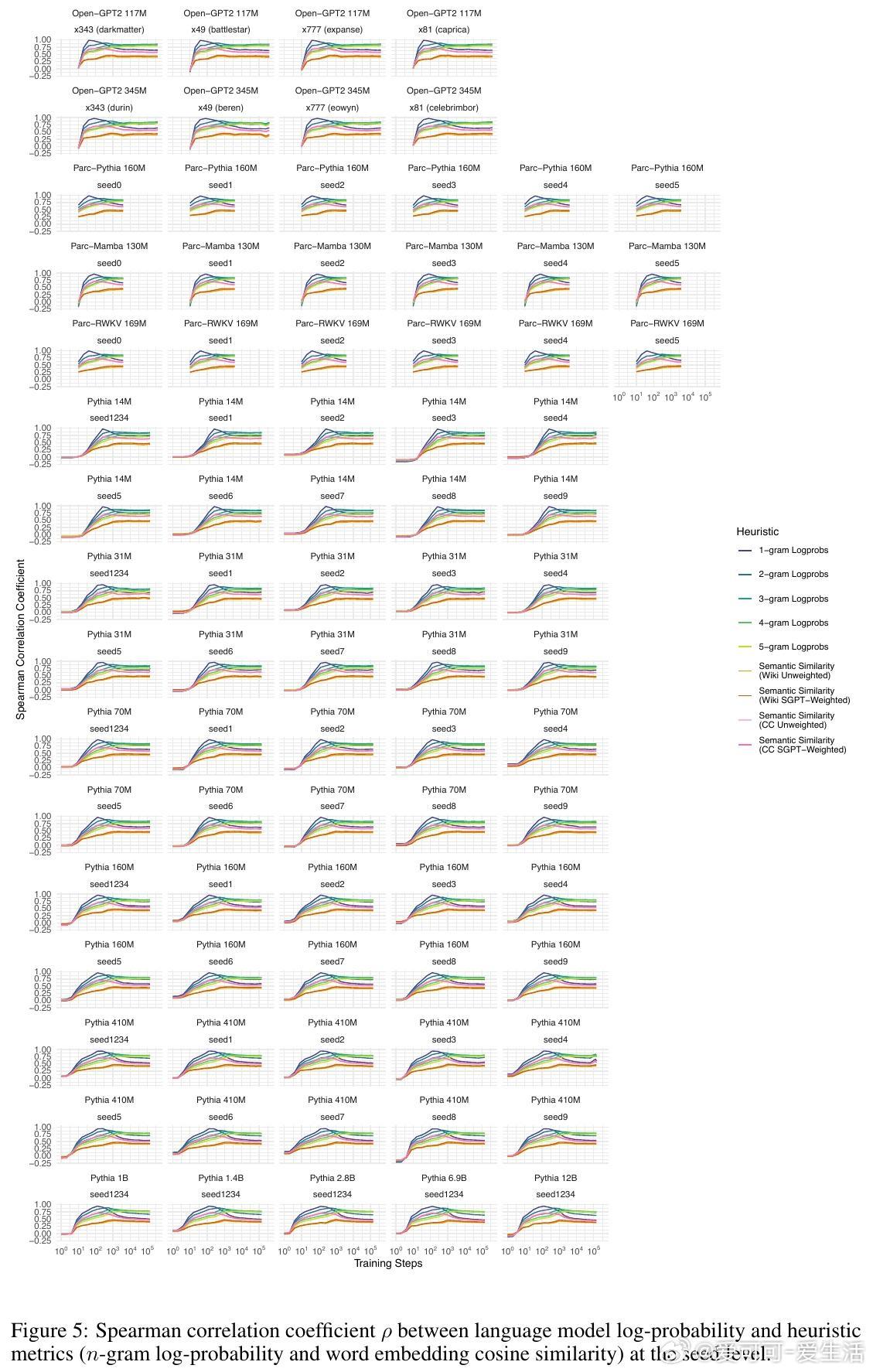
5. 该行为阶段性规律在不同架构、不同数据集及不同规模的模型间高度一致,暗示自回归语言建模任务本身是塑造这些行为阶段的关键驱动力。
此外,研究中还发布了基于Parc架构训练的1314个模型检查点和包含15万自然语境词汇的NaWoCo数据集,为社区提供了宝贵资源。实验证明,即使训练数据和模型结构差异显著,语言模型的行为发展轨迹依然遵循类似的规律,揭示了语言模型学习机制的普适性。
这项工作不仅深化了我们对语言模型训练动态的理解,也为未来设计更高效、更具解释性的语言模型提供了理论基础和实验依据。
论文链接:arxiv.org/abs/2510.24963
语言模型 机器学习 自然语言处理 模型训练 深度学习