[LG]《Encoder-Decoder or Decoder-Only? Revisiting Encoder-Decoder Large Language Model》B Zhang, Y Cheng, S Shakeri, X Wang... [Google DeepMind] (2025)
Encoder-Decoder还是Decoder-Only?重新审视编码-解码大型语言模型(RedLLM)
近年来,大型语言模型(LLM)在架构上从编码-解码模式转向了主流的解码器单独模式(DecLLM),但缺少对两者扩展性(scaling)的系统比较,导致编码-解码架构潜力被低估。本文由Google DeepMind团队基于RedPajama V1数据集(1.6万亿tokens)和FLAN指令调优,针对150M至8B参数规模,深入对比了RedLLM(编码-解码架构,采用prefix语言模型预训练)与DecLLM(单解码器架构,采用causal语言模型预训练)的性能与效率。
核心发现:
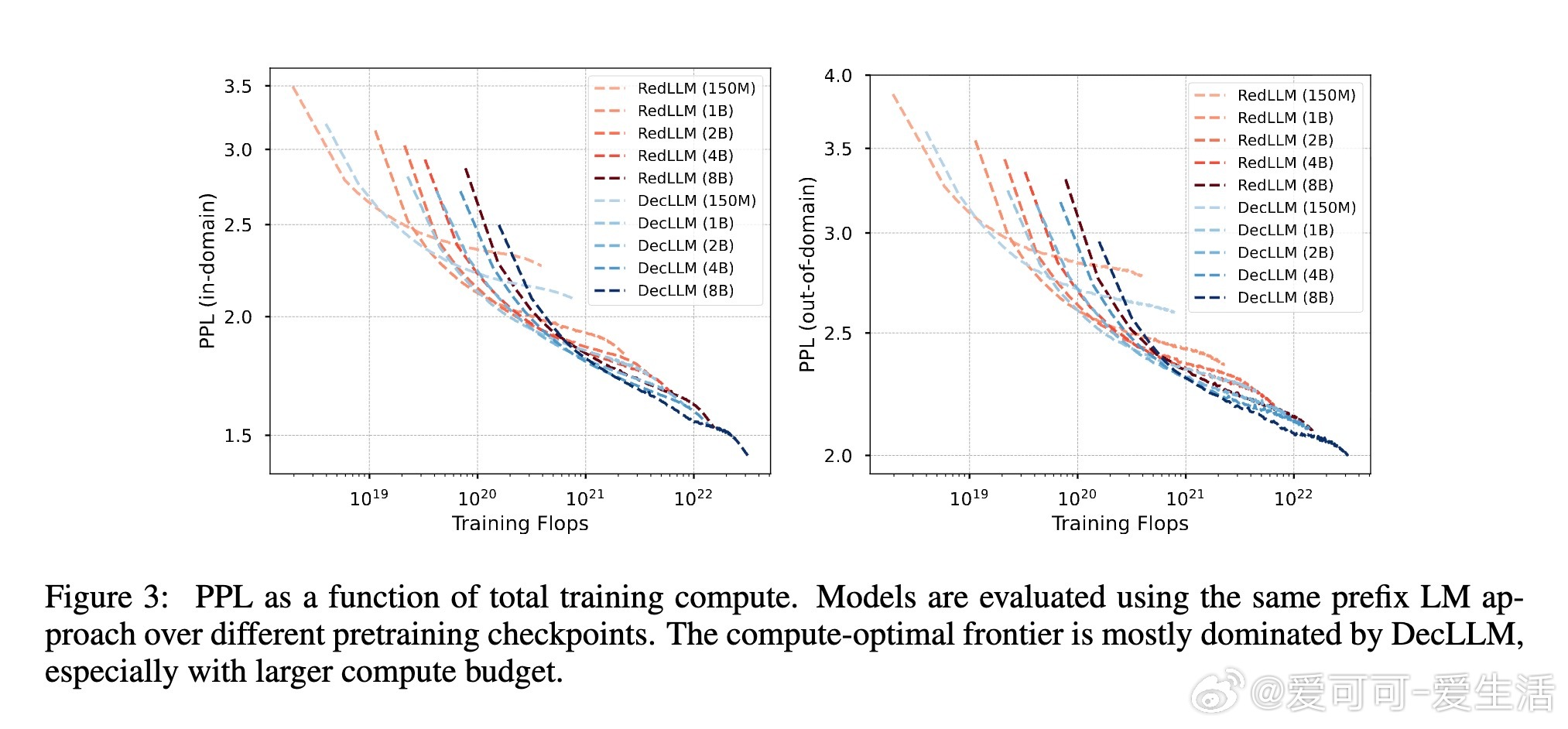
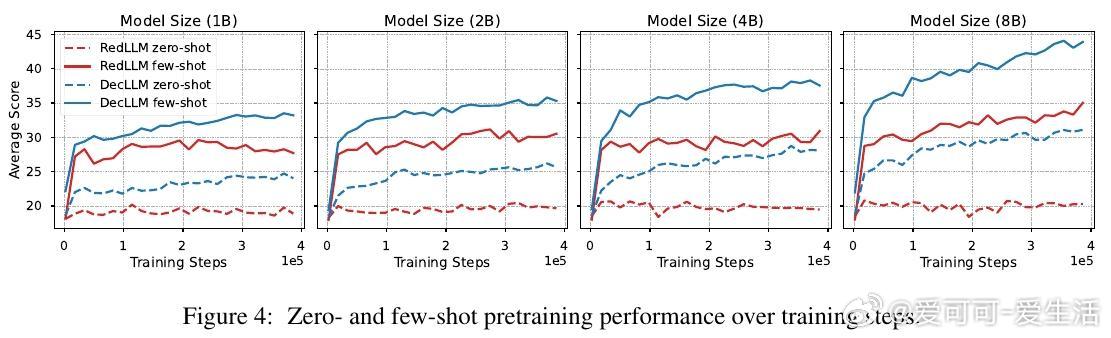
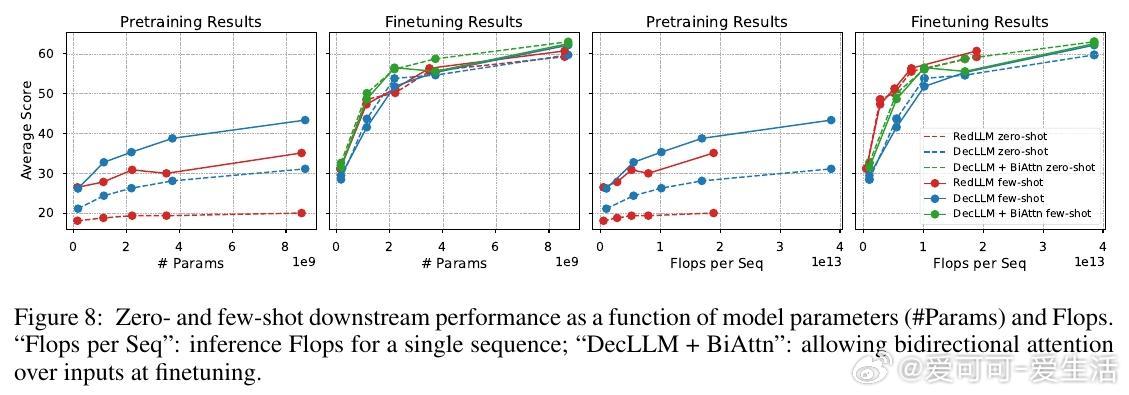
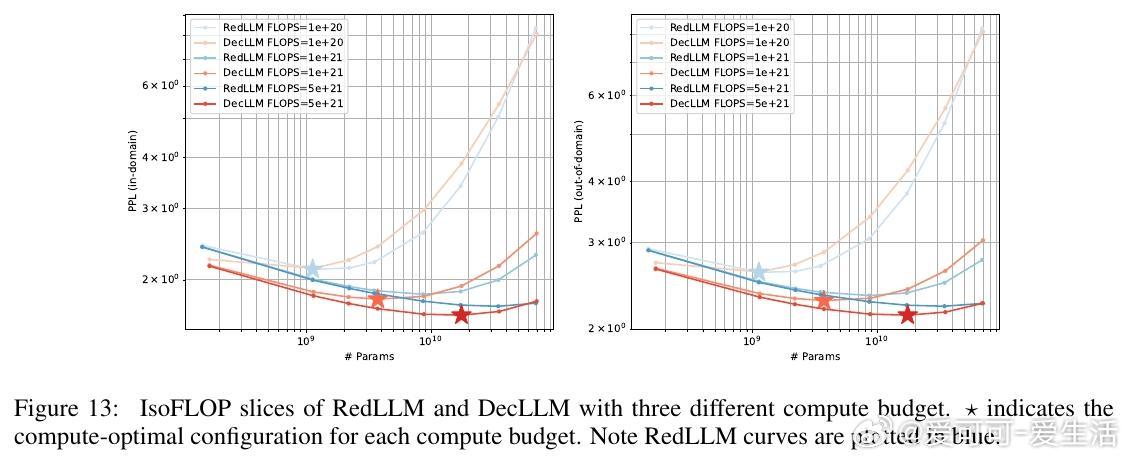
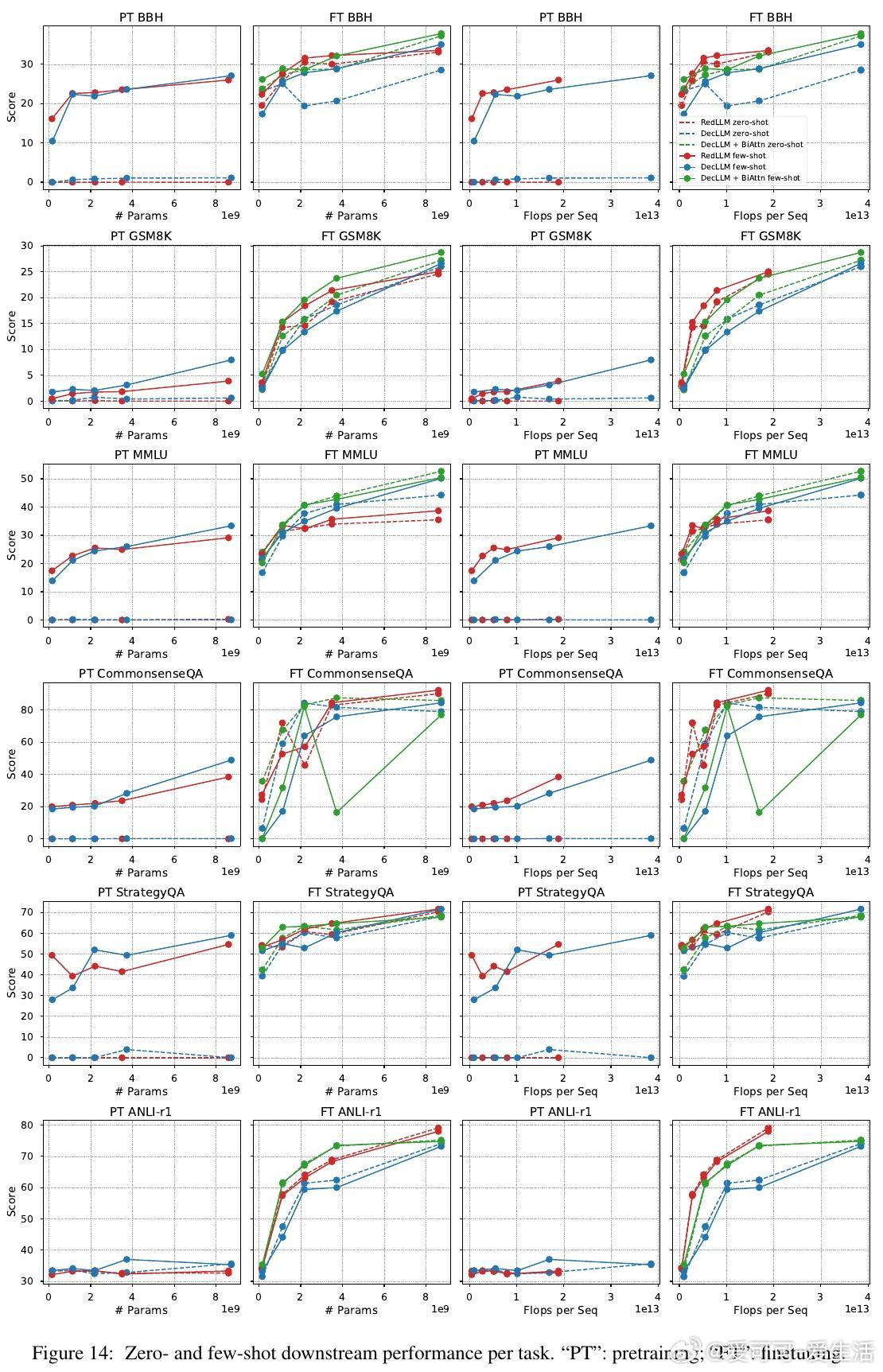
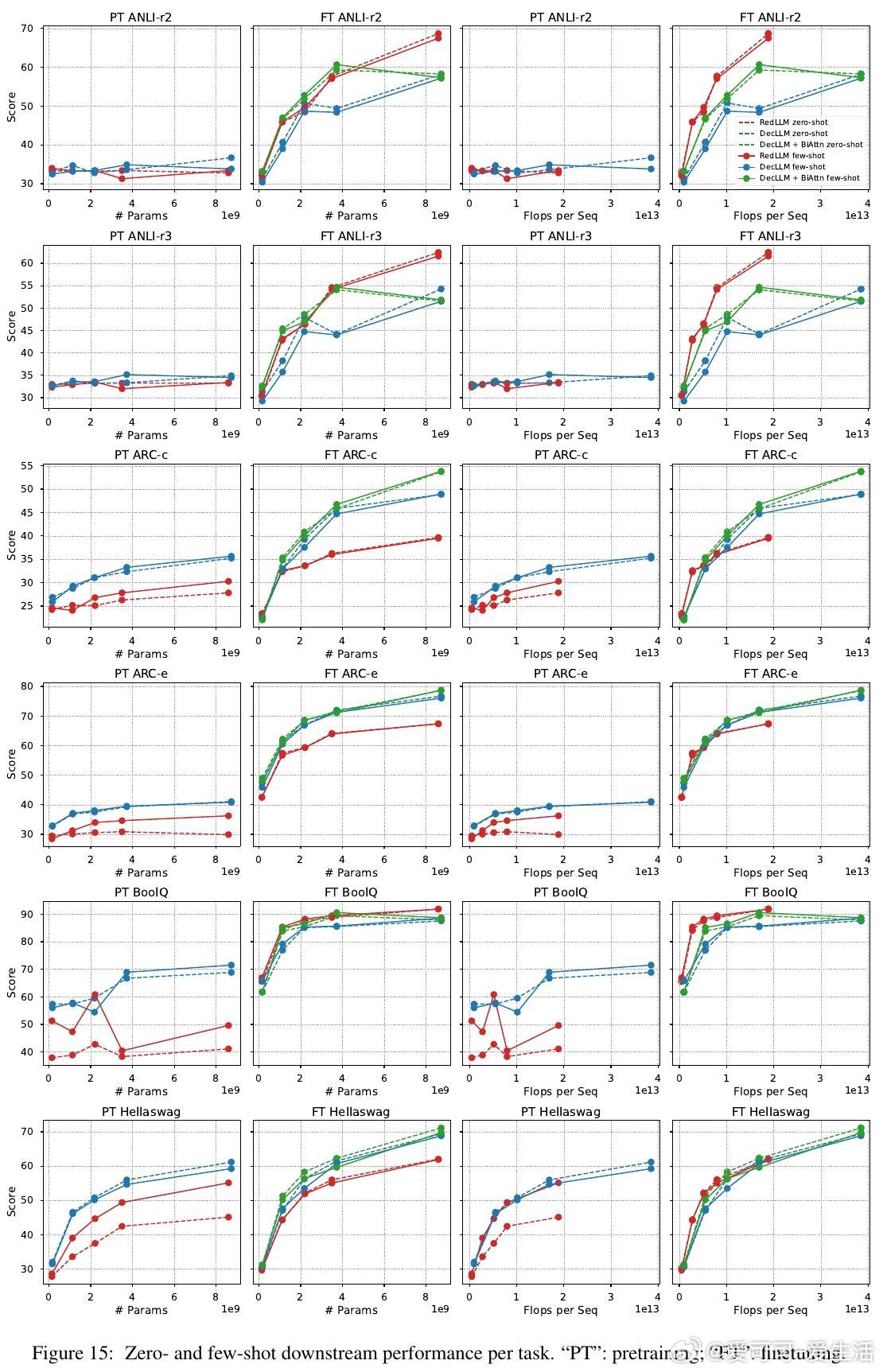
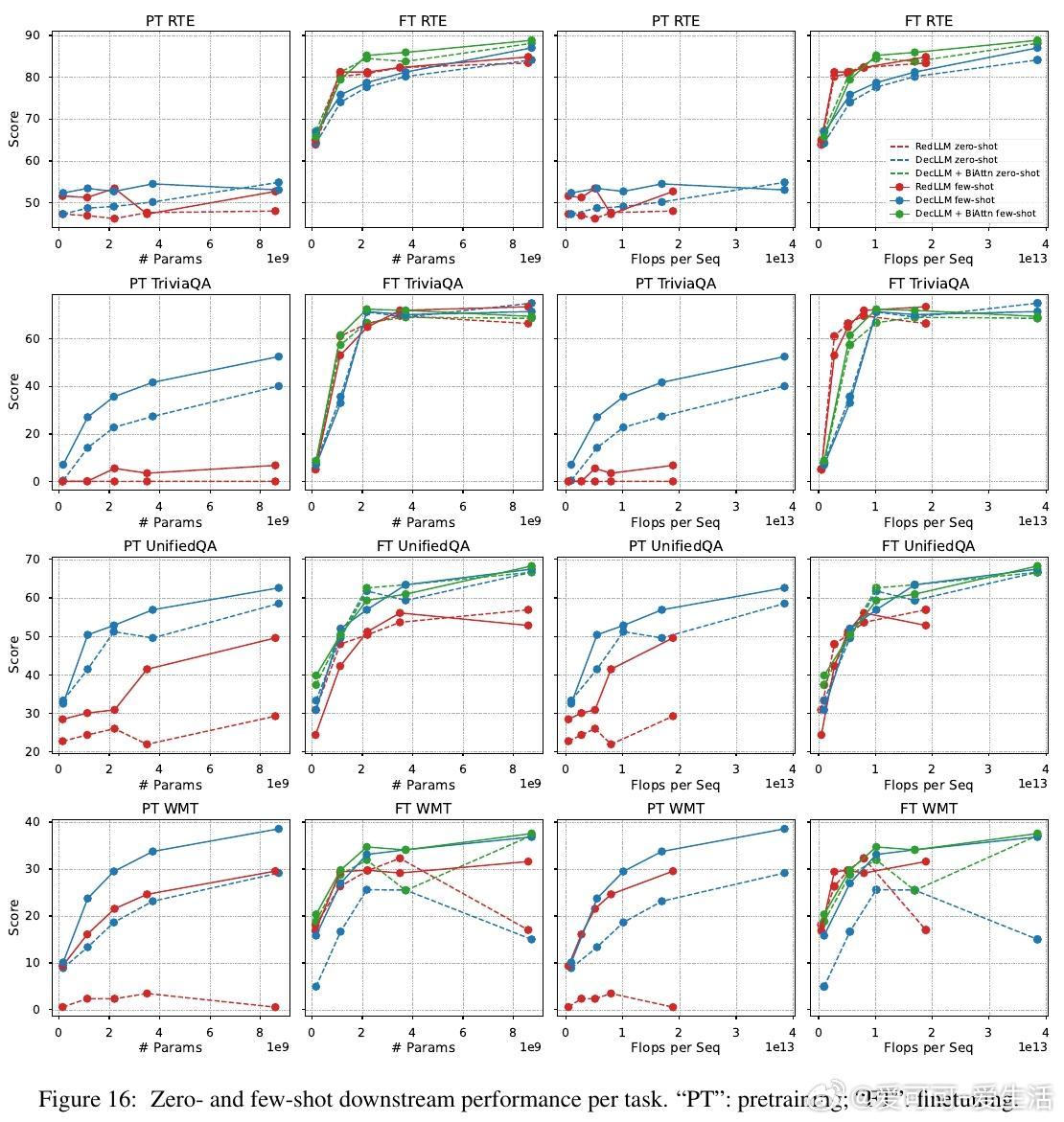
1. 预训练阶段,RedLLM与DecLLM在模型规模与计算量扩展上的表现相似,但DecLLM在计算效率上更优,尤其在零样本(zero-shot)和少样本(few-shot)学习上远超RedLLM。
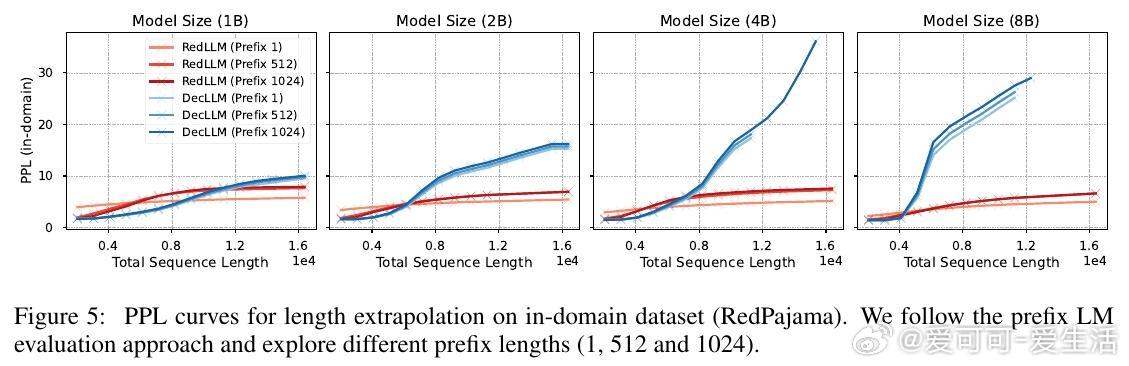
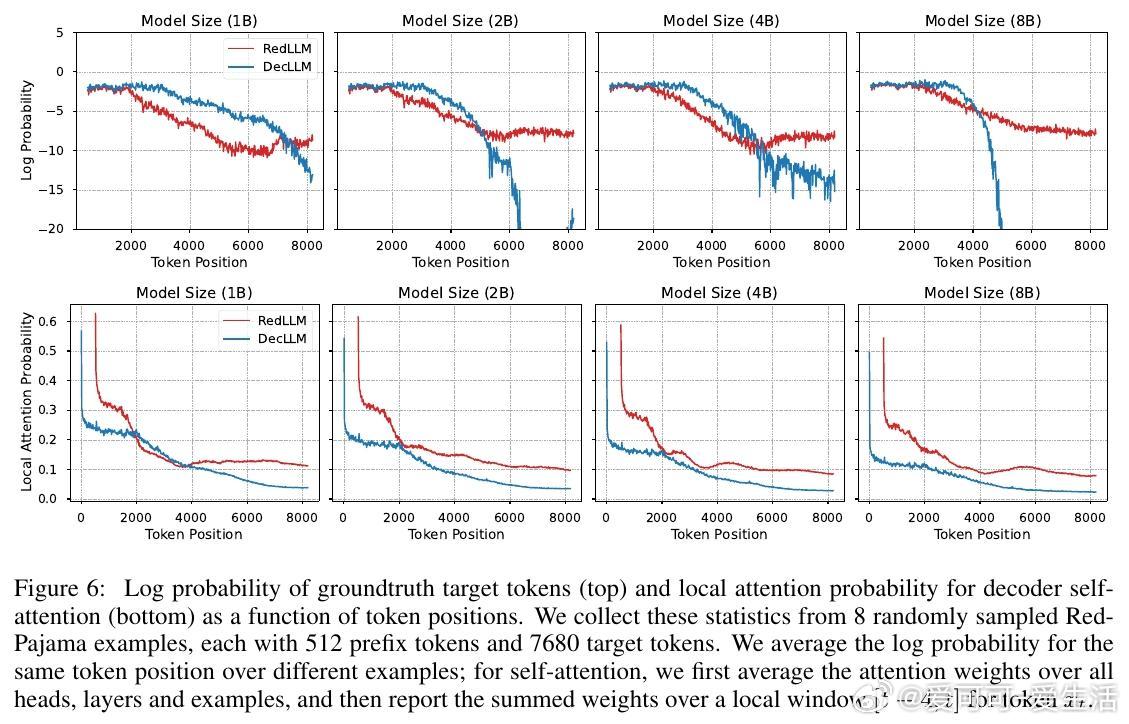
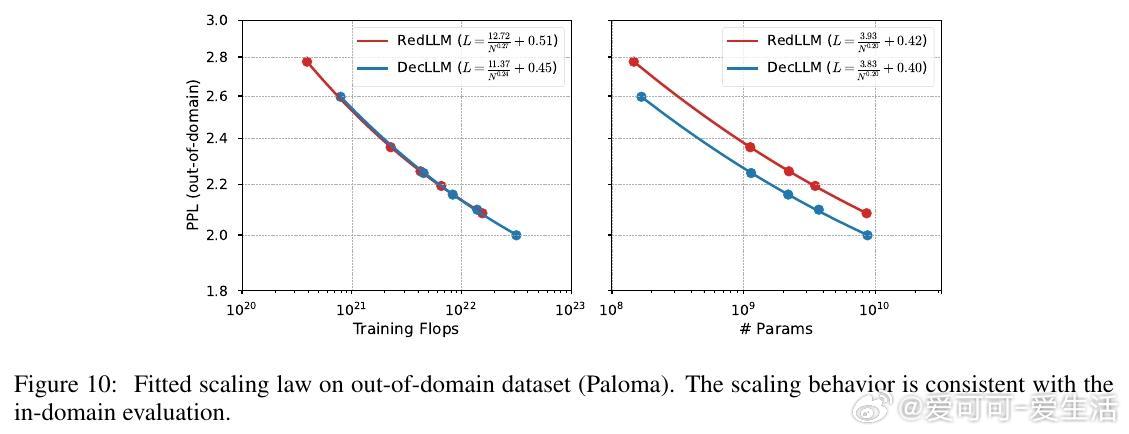
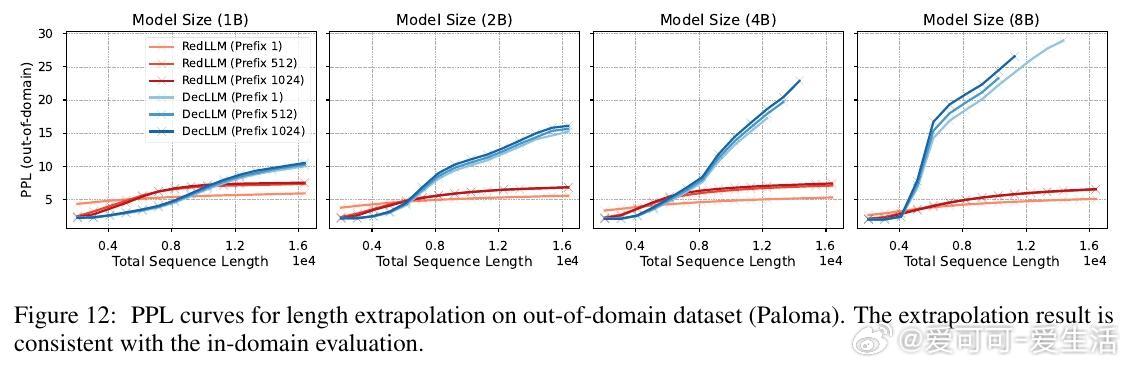
2. RedLLM在上下文长度外推(context length extrapolation)能力上表现突出,甚至优于DecLLM,展现对长文本处理的潜力。
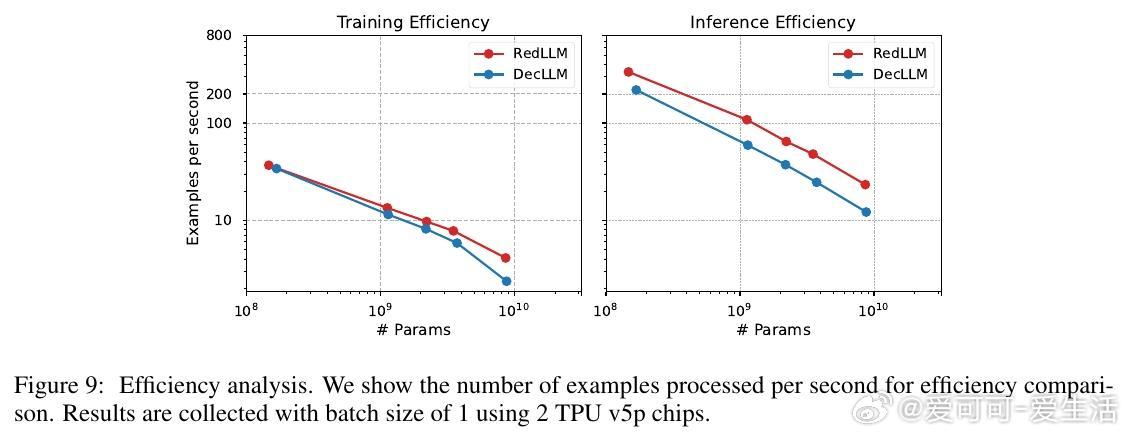
3. 经过指令微调后,RedLLM性能明显提升,能够匹配甚至超越DecLLM,且在推理效率(inference efficiency)上有显著优势,意味着更优的质量-计算折中。
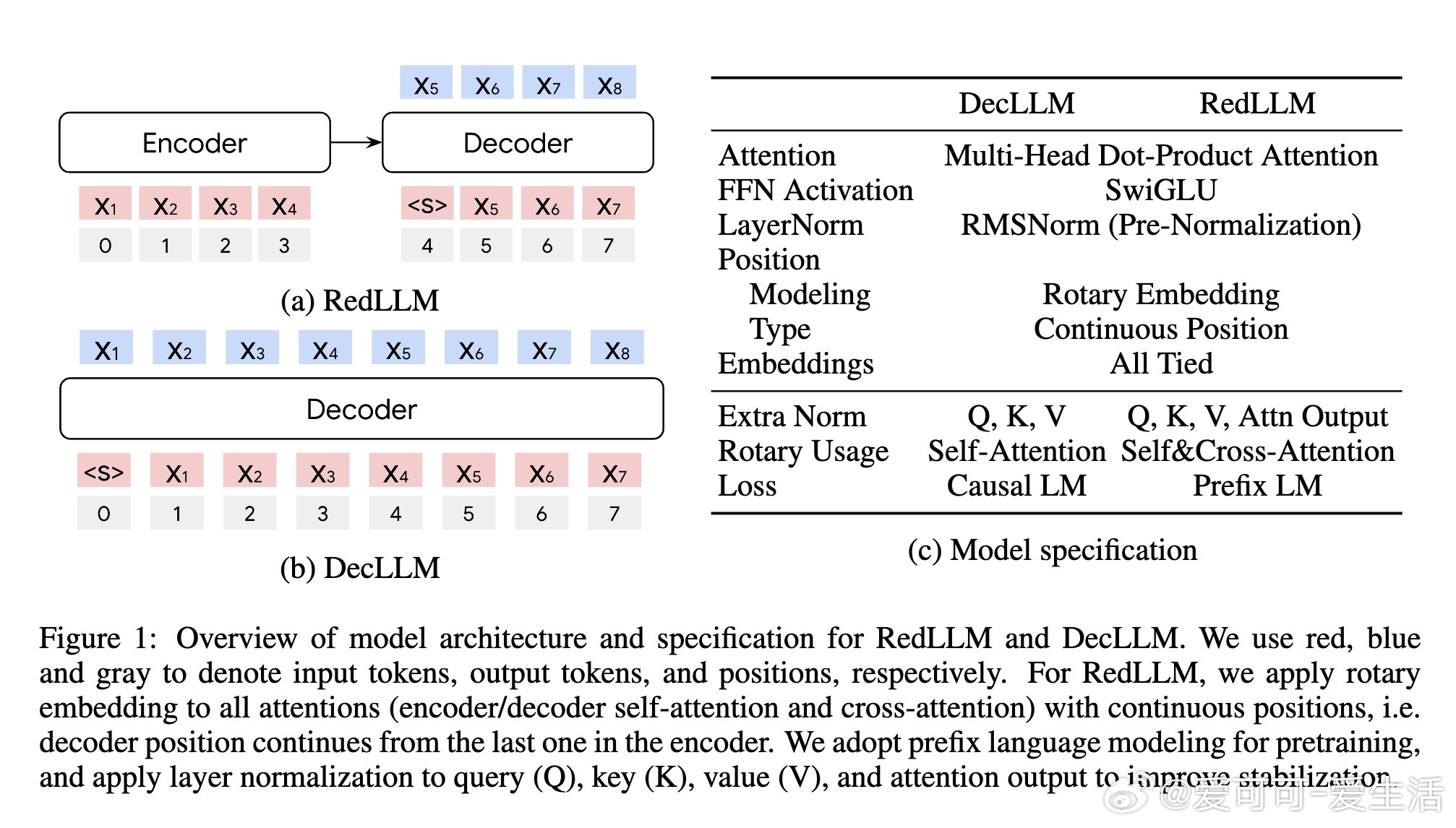
4. RedLLM的双向编码器注意力机制在训练和推理效率上表现优异,适应性强;为DecLLM引入类似双向注意力结构,也能大幅提升其表现。
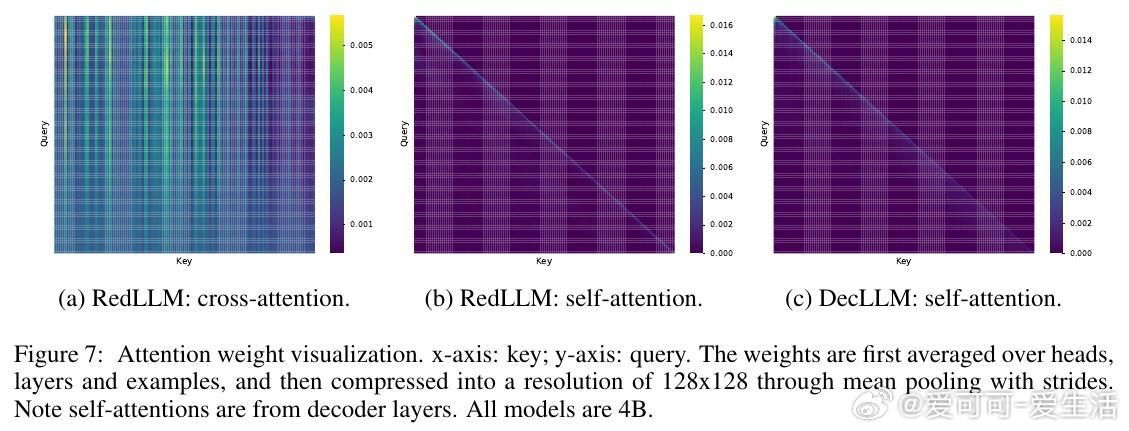
5. 两者在注意力机制上存在差异,RedLLM的交叉注意力更为多样,帮助捕捉远距离信息,但也增加学习难度。
研究方法:
- 预训练使用RedPajama V1和T5X框架,采用统一的32K词汇表和相似的优化策略。
- 评估包括RedPajama(域内)和Paloma(域外)数据集的困惑度(perplexity)及13项下游任务的零样本和少样本性能。
- 规模从150M到8B参数,细致分析了模型在不同计算预算下的质量-效率曲线。
意义与展望:
本文挑战了目前解码器单独架构主导的观点,强调编码-解码架构在效率与后期微调表现上的优势。未来工作将探索更大规模模型、非均衡结构(如深编码器浅解码器)、多样化预训练目标及更深入的长序列建模机制。
链接详读: