[CL]《Reasoning Curriculum: Bootstrapping Broad LLM Reasoning from Math》B Pang, D Kong, S Savarese, C Xiong... [Salesforce AI Research & University of California, Los Angeles] (2025)
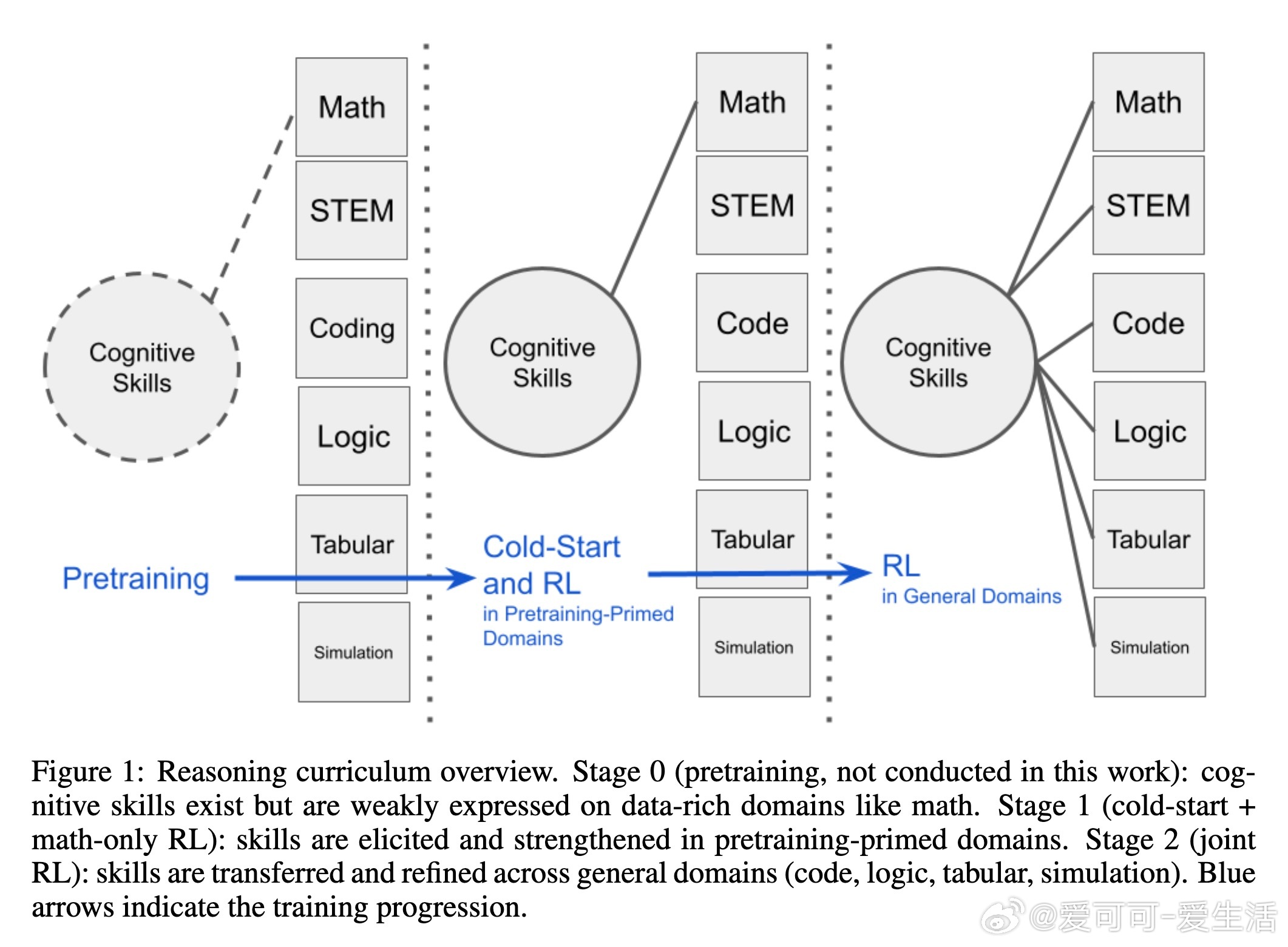
本文介绍了“推理课程”(Reasoning Curriculum),一种简单且高效的两阶段训练策略,旨在提升大语言模型(LLMs)的广泛推理能力。核心思路是:先在数学这一预训练中模型较为擅长且奖励易验证的领域,通过冷启动和强化学习(RL)阶段强化推理技能;随后在多领域混合数据上进行联合强化学习,迁移并巩固这些技能,实现跨领域推理能力的提升。
第一阶段包括对预训练模型进行小规模数学任务的监督微调(冷启动),快速让模型学习多种认知技能(如子目标设定、枚举、回溯与验证),之后通过数学专属的强化学习进一步巩固这些技能,利用简单、低噪声的正确性奖励信号进行训练,避免复杂奖励模型带来的稳定性问题。第二阶段则是在涵盖数学、STEM、代码、逻辑、仿真及表格数据等多领域混合数据上,使用同样的强化学习方法,完成技能的跨领域迁移和细化。
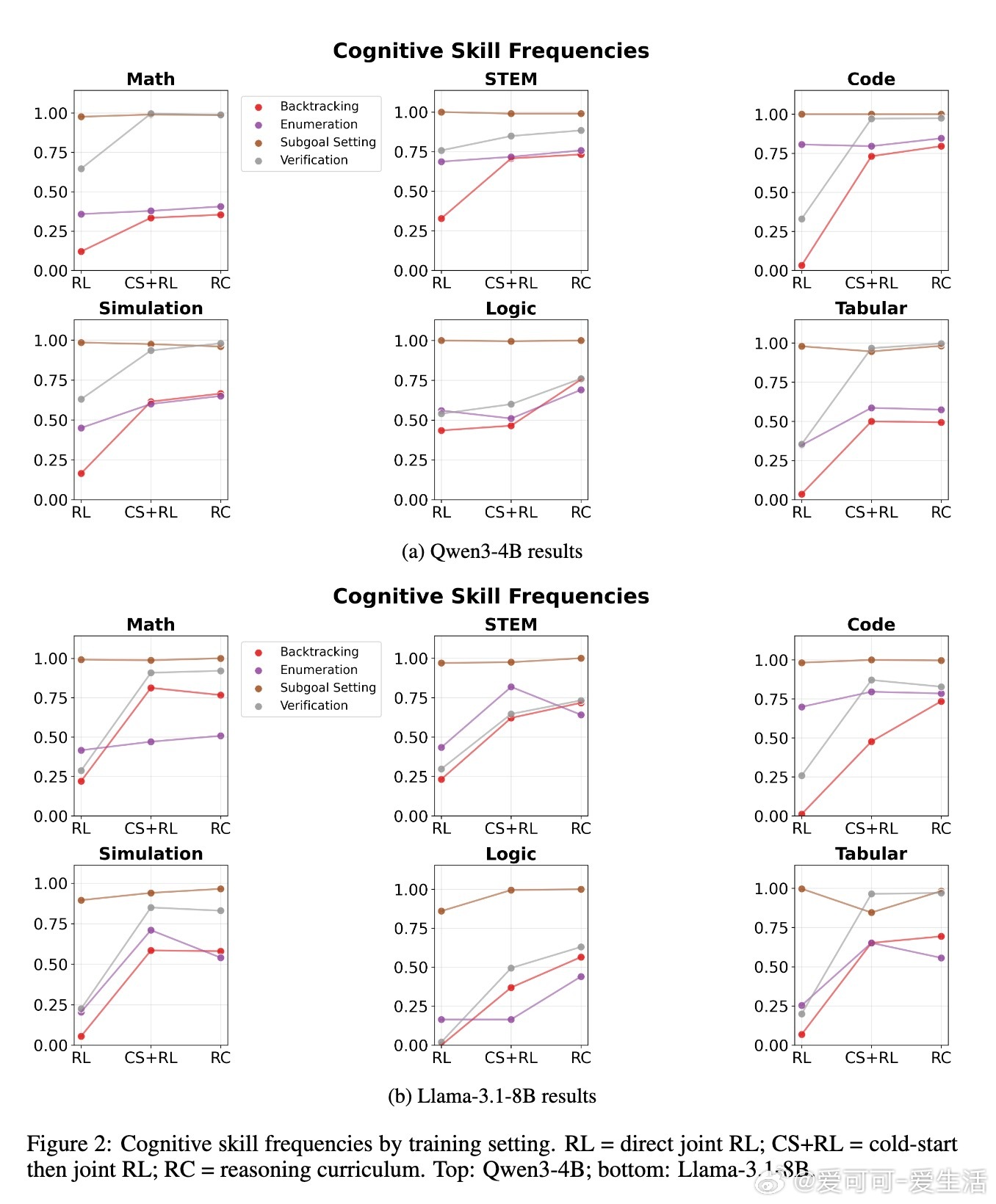
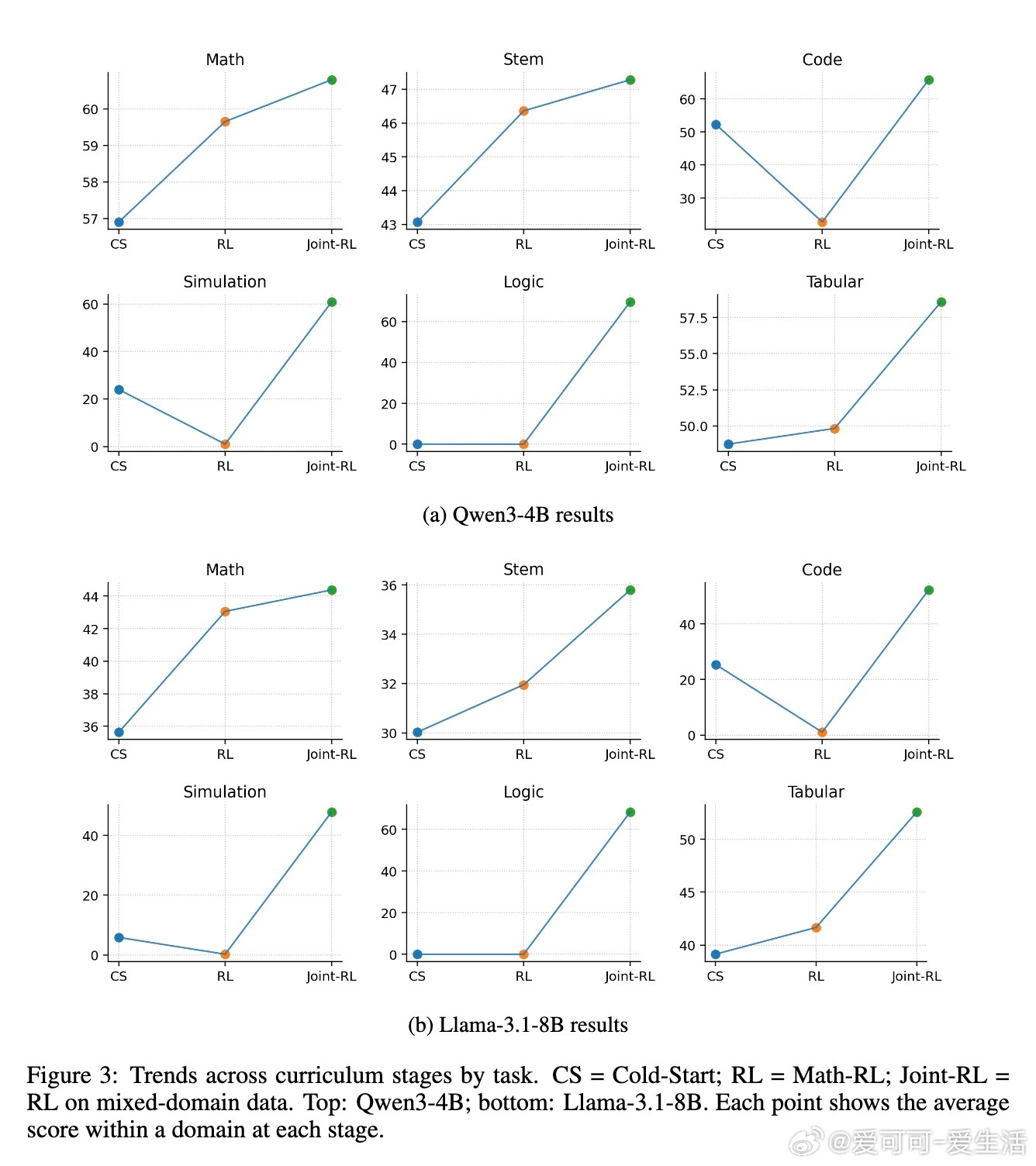
在两个代表性模型Qwen3-4B和Llama-3.1-8B上的实验证明,该课程训练方法能显著超越同规模基线,甚至在部分任务上媲美或优于32B级别的大模型。针对Llama模型,作者进一步引入了数学训练阶段的难度递进策略(中等难度先于高难度),稳定了训练过程并提升性能。消融实验表明,冷启动和数学强化学习两个阶段缺一不可,均对最终性能贡献显著。认知技能分析显示,数学优先的训练有效提升了验证和回溯等高级认知行为的使用频率,这些技能对于解决复杂问题至关重要。
该方法的优势在于其极简主义设计,不依赖专门复杂的奖励模型,仅通过标准的可验证性检查即可实现,且适用于不同模型架构。它为实现通用推理能力提供了一条紧凑、易于采纳的训练路线图,有望推动大语言模型在多领域复杂推理任务中的表现提升。
详情阅读论文: