[CL]《Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning》Y Deng, I Hsu, J Yan, Z Wang... [Google Cloud AI Research] (2025)
“监督强化学习(SRL)”助力小型大模型攻克多步推理难题
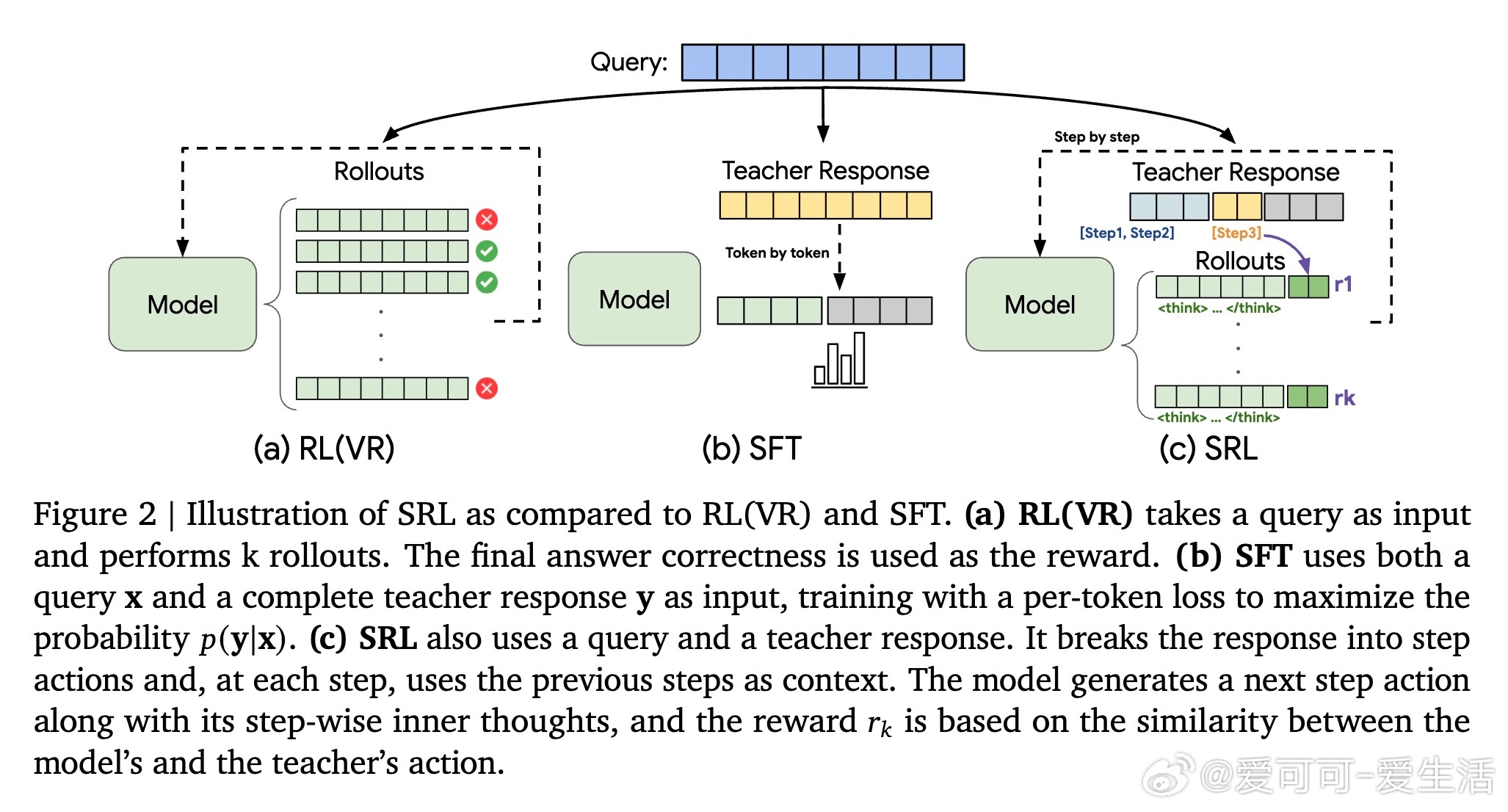
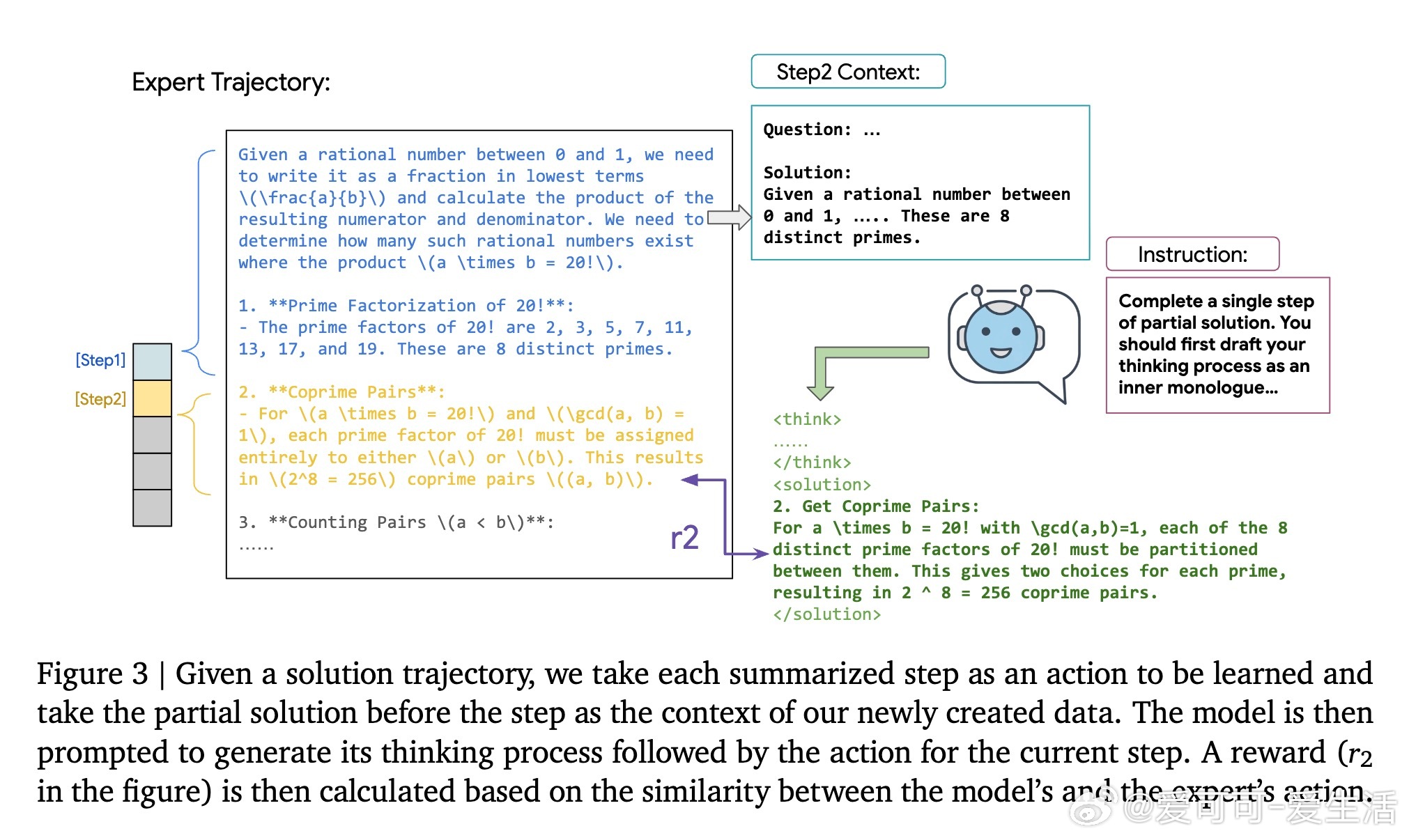
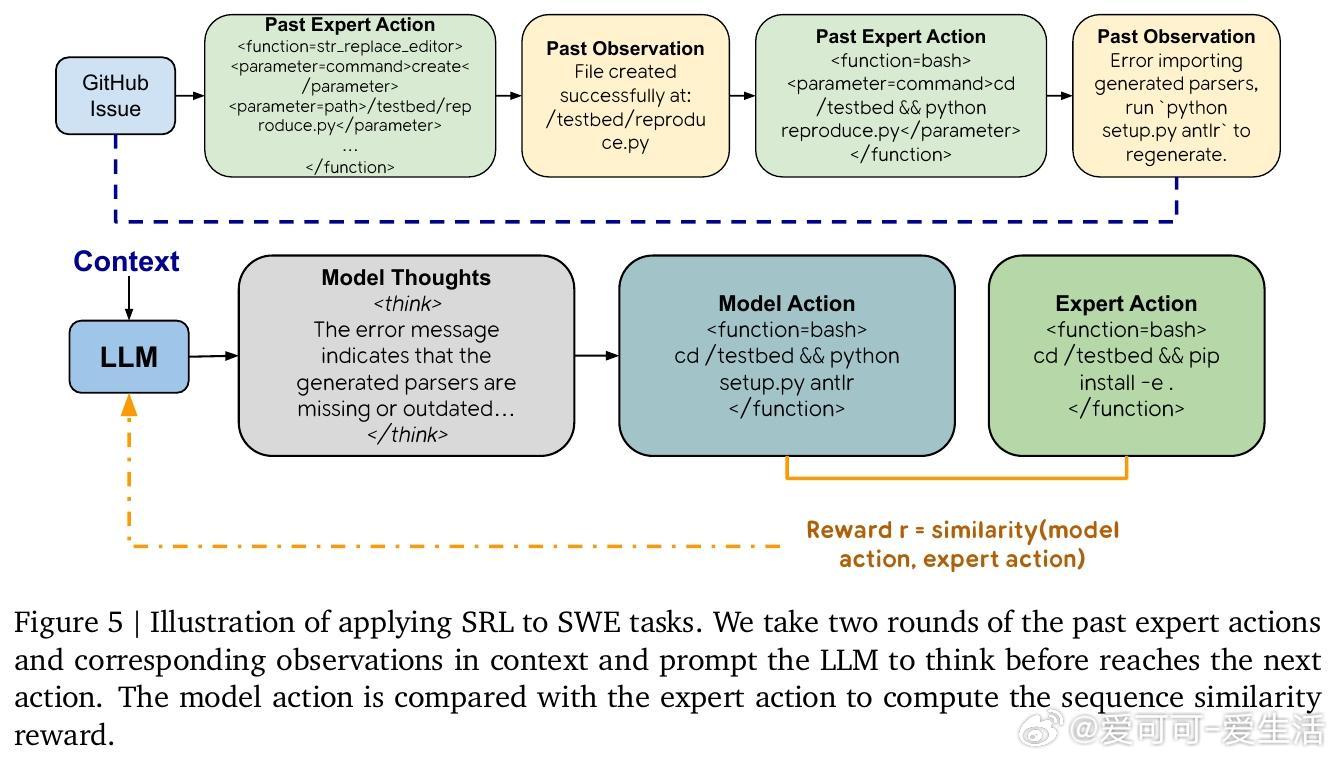
传统强化学习(RL)依赖最终答案对模型奖励,难以在复杂推理中找到正确路径,导致训练失败;监督微调(SFT)则因逐字模仿易过拟合,缺乏灵活性。SRL创新性地将问题拆解为一系列“步骤动作”,并要求模型在每一步先生成内部推理“思考独白”,再输出动作。每步动作与专家轨迹对比,给予细粒度相似度奖励,提供丰富、平滑的训练信号。
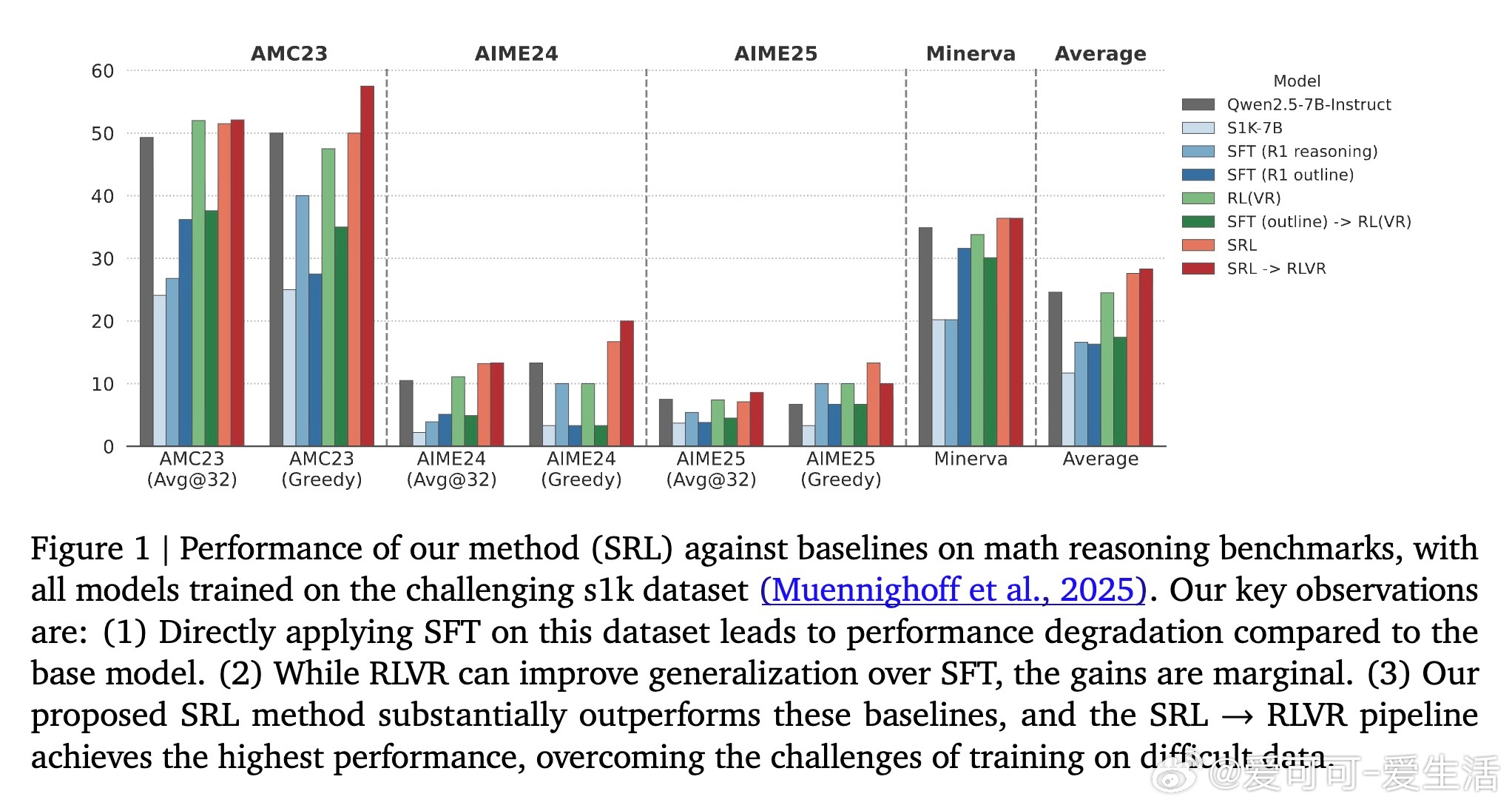
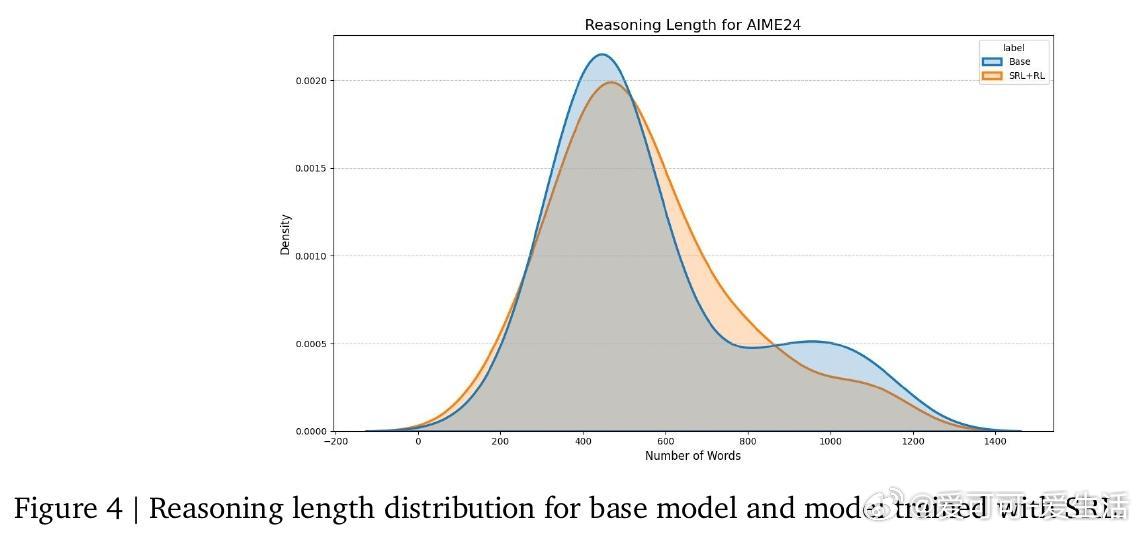
实验中,SRL在数学竞赛级推理任务(AMC23、AIME24/25、Minerva Math)上显著超越SFT和RL基线,单独使用SRL平均提升3.0%,结合RL微调更达3.7%。SRL不仅提升准确率,更激发模型灵活推理能力,如交错规划与自检验证,提升解题质量而非简单延长输出。进一步,SRL成功扩展到软件工程智能体任务,解决长上下文、高延迟和动态环境反馈难题,实现修复率提升74%。
SRL核心优势:
1. 将专家示范分解为步骤动作,便于小模型学习复杂推理。
2. 通过内部推理“独白”保持灵活思考,避免死板模仿。
3. 基于步骤动作相似度的密集奖励,解决传统RL稀疏反馈瓶颈。
4. 动态采样过滤弱信号样本,保障训练稳定有效。
SRL为小规模开源模型带来强大推理能力,是连接监督学习与强化学习的桥梁,为AI在数学、编程等多领域复杂任务的突破提供新范式。
论文链接:arxiv.org/abs/2510.25992