[LG]《CANDI: Hybrid Discrete-Continuous Diffusion Models》P Pynadath, J Shi, R Zhang [Purdue University & Google DeepMind] (2025)
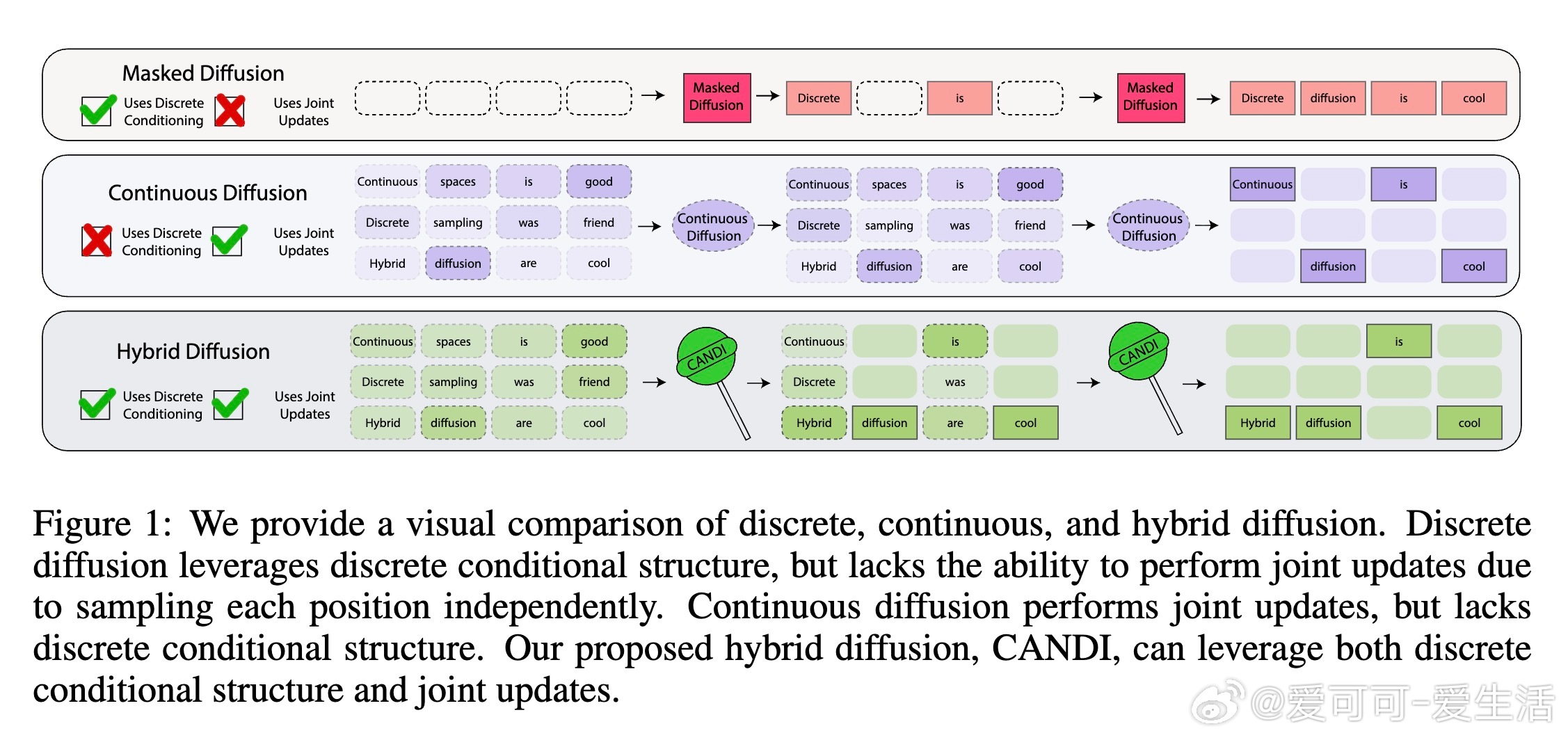
本文深入探讨了将连续扩散模型直接应用于离散数据时性能不佳的根本原因,并提出了创新的混合扩散框架CANDI来解决这一难题。
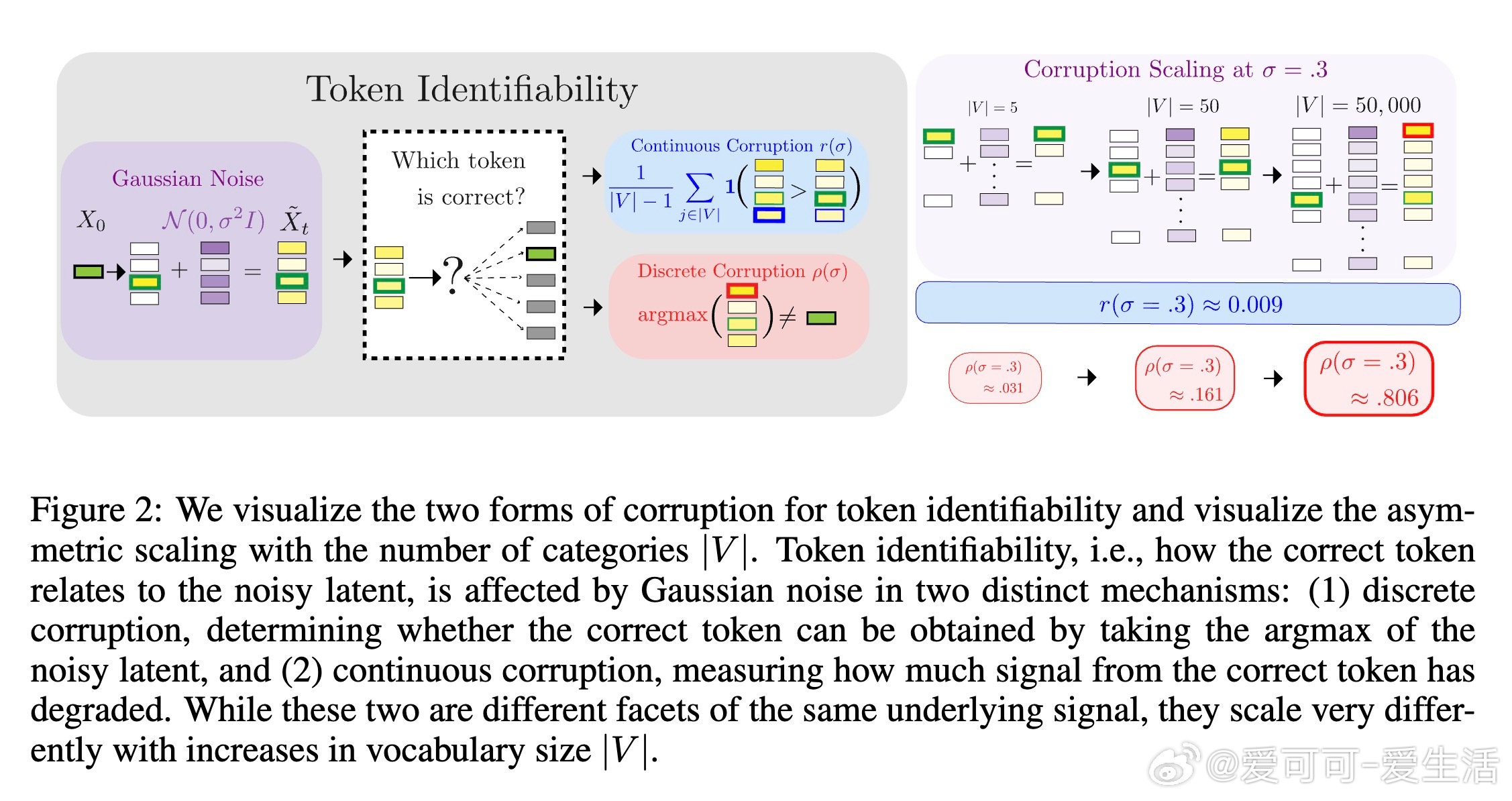
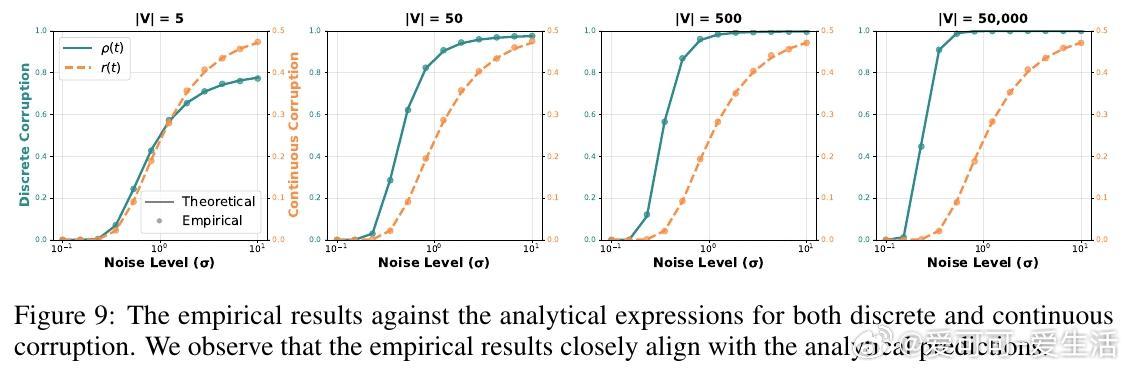
核心发现在于“token identifiability”(令牌可识别性)分析框架,揭示了高斯噪声对离散数据的破坏机制分为两类:
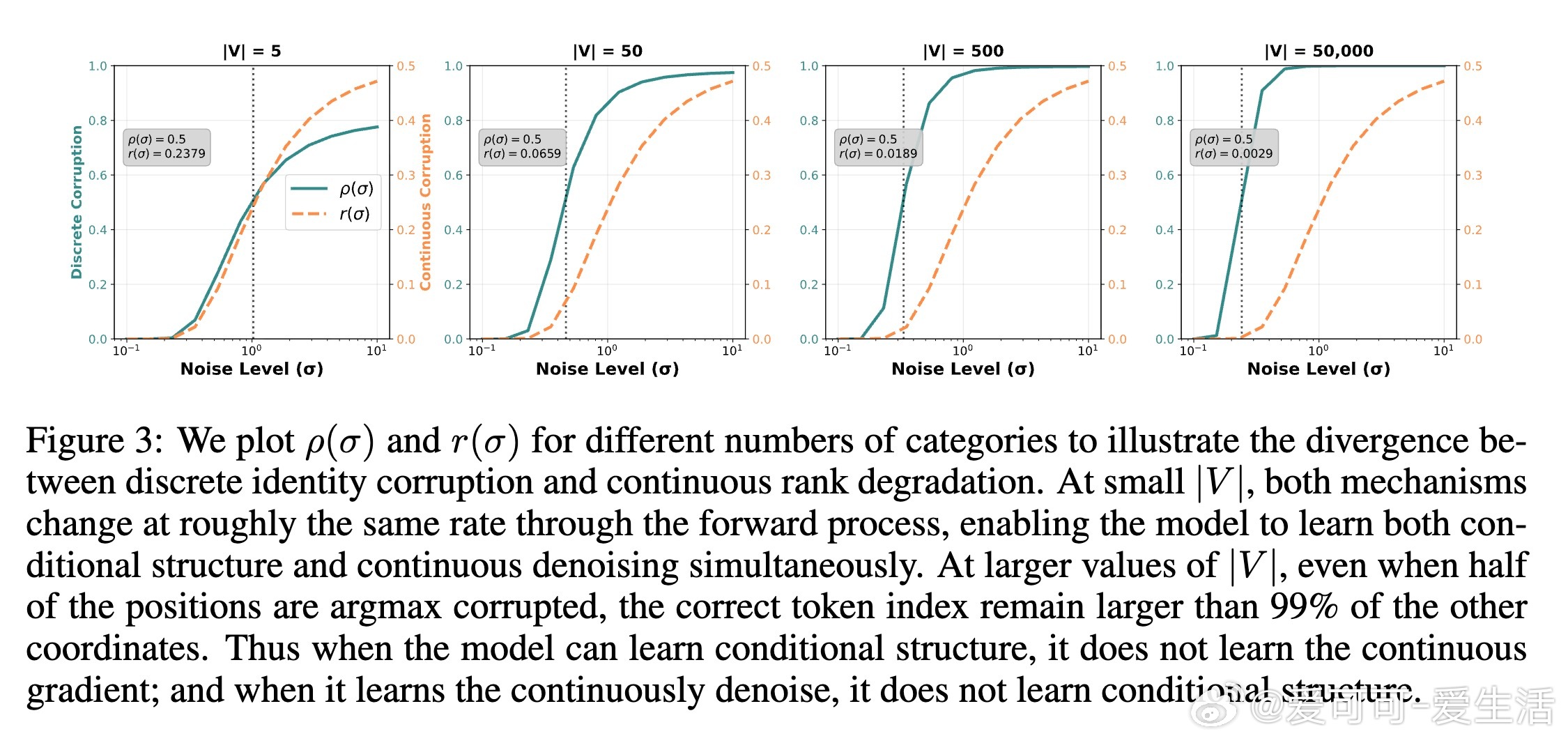
1. 离散身份破坏(Discrete Identity Corruption):噪声导致正确令牌无法被准确识别,其概率随着词汇表大小呈指数增长,严重影响模型学习条件依赖结构。
2. 连续秩降解(Continuous Rank Degradation):正确令牌相对其他令牌的排名退化程度,且与词汇表大小无关,反映了连续信号的损失程度。
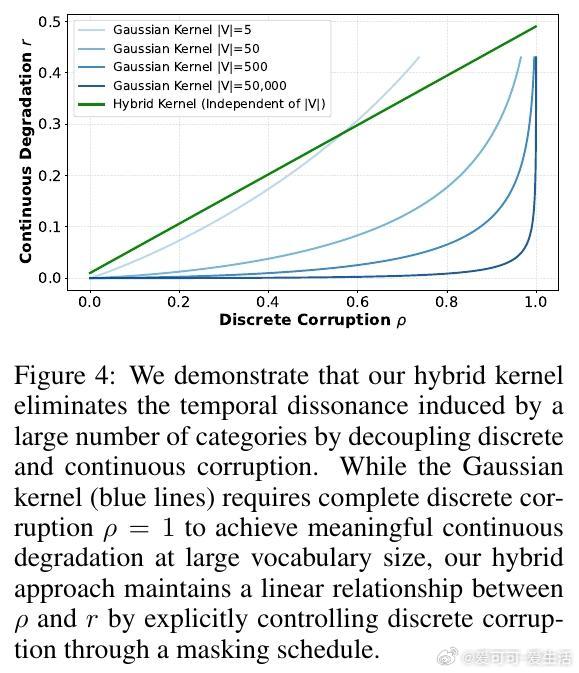
这两种破坏机制在时间尺度上的不一致(temporal dissonance)导致纯连续扩散模型难以同时学习到离散条件依赖和连续梯度信息,造成生成质量低下。
为解决此问题,作者提出CANDI框架:
- 设计结构化的噪声核,采用离散掩码过程保持部分位置干净,同时对其他位置注入高斯噪声,实现离散身份破坏和连续秩降解的解耦,令两者随时间线性变化,避免了词汇规模导致的时序错位问题。
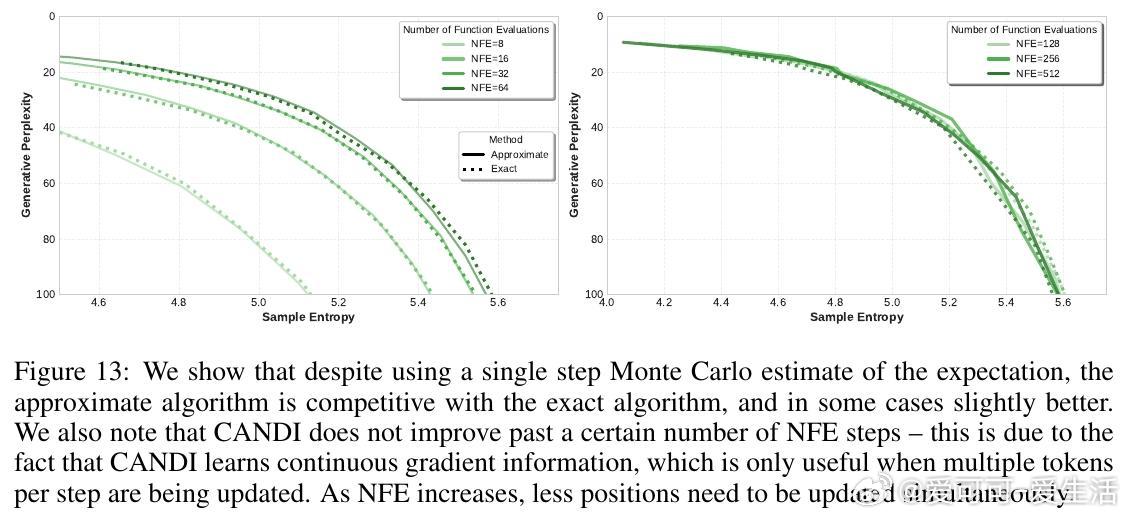
- 训练过程中同时学习条件分布和连续分数函数,推理时结合确定性ODE更新和离散条件采样,支持高效的近似算法以避免高维矩阵运算。
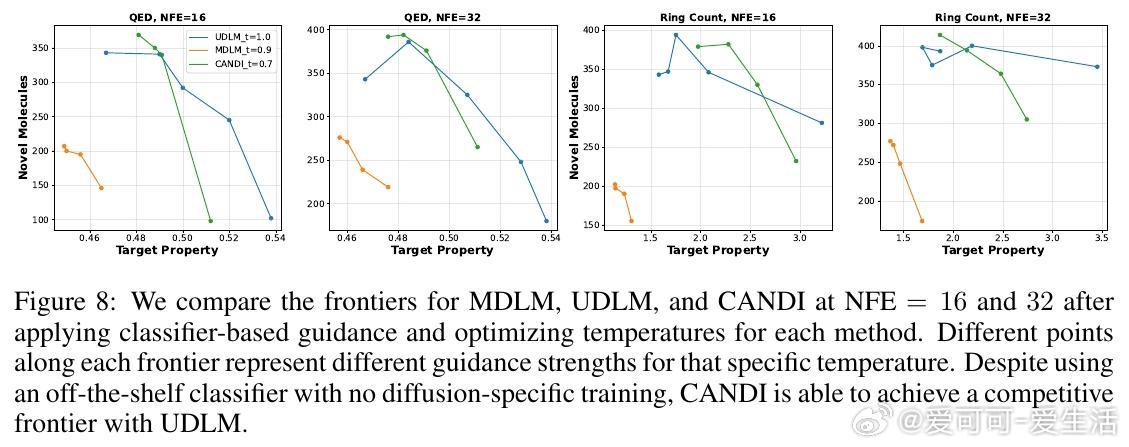
- 利用连续几何结构,实现了无需扩散特定训练的分类器指导(classifier-based guidance),极大方便了受控生成任务。
实验证明:
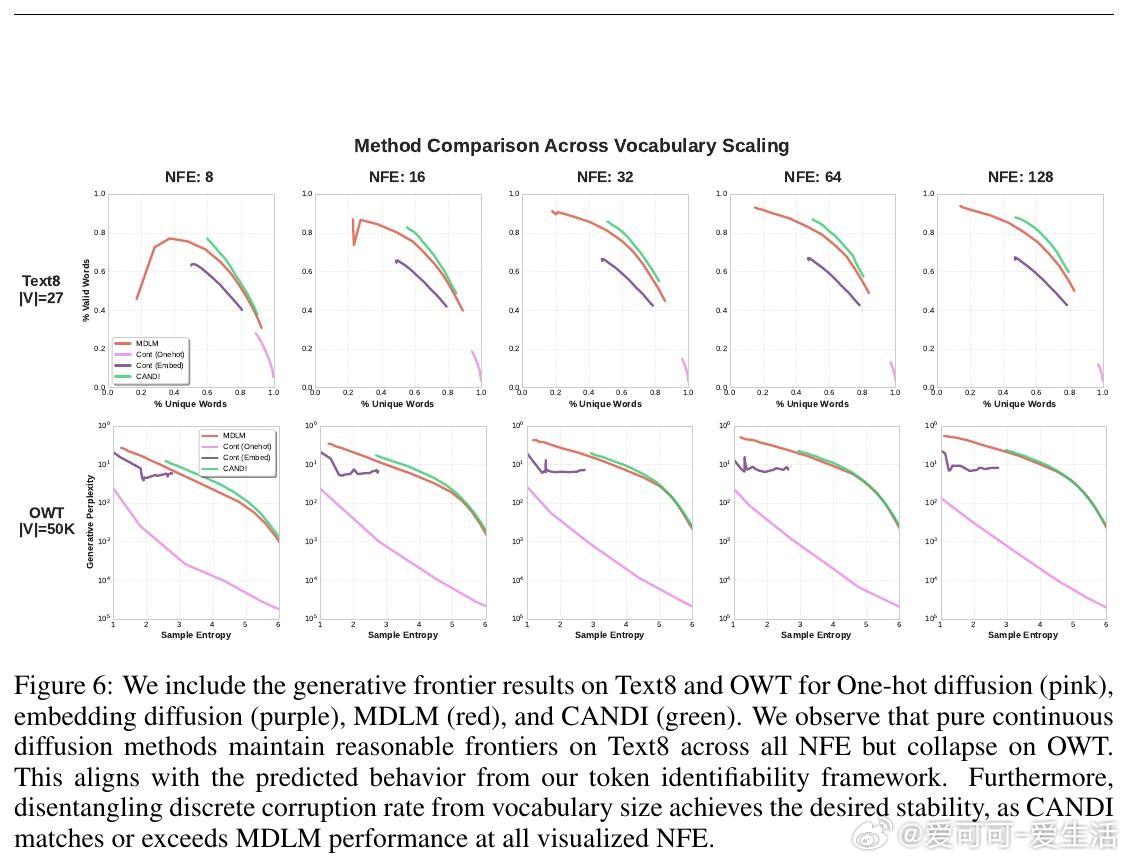
- 连续扩散在小词汇表上表现尚可,但随着词汇规模增大,生成质量严重退化,验证了时序错位现象。
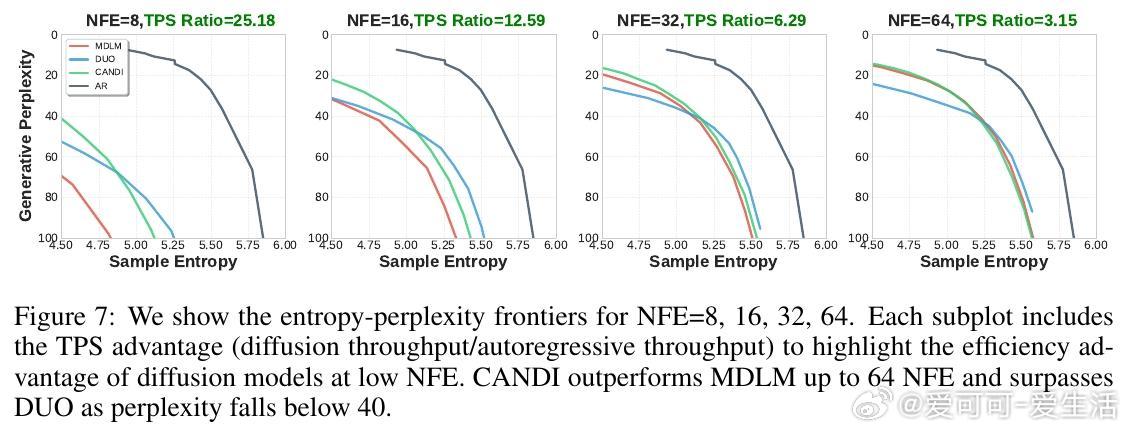
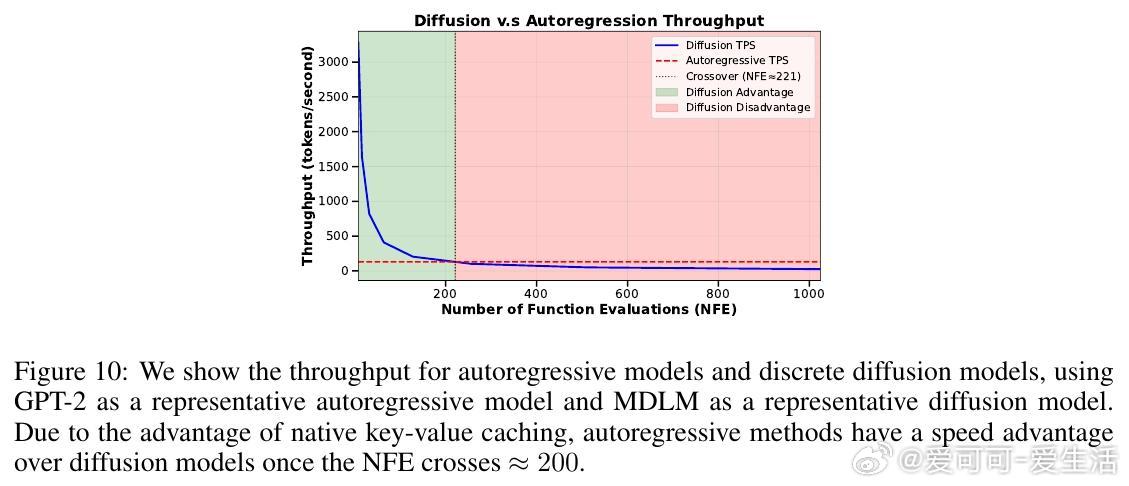
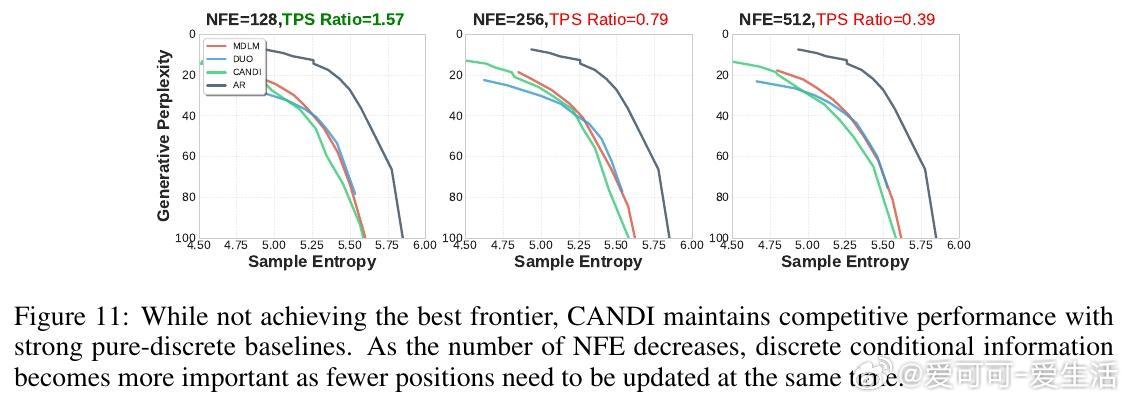
- CANDI成功避免此问题,在大词汇表文本生成任务(如OpenWebText)中表现优于纯离散扩散方法,尤其在低推理步数(NFE)情况下优势明显。
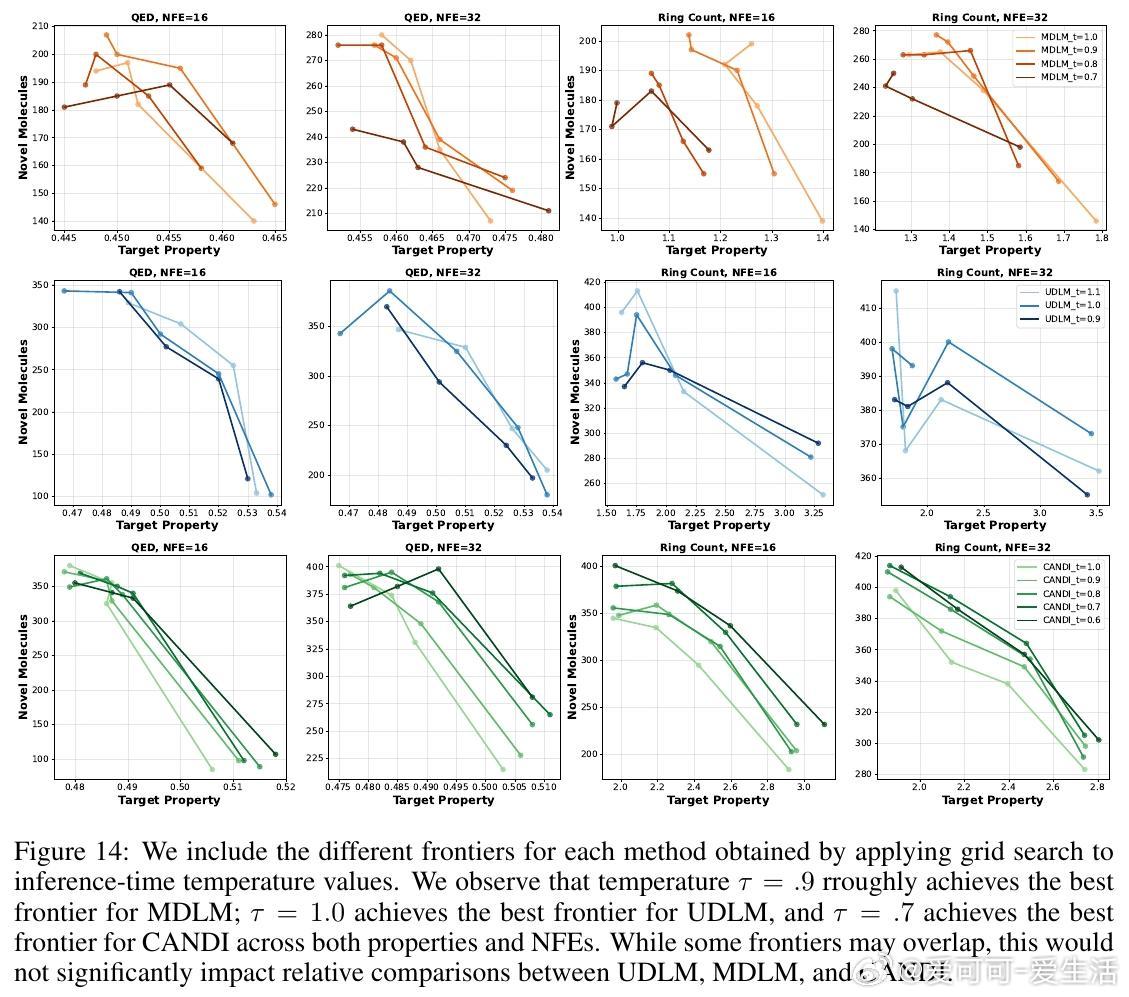
- CANDI支持利用现成分类器实现受控分子(QM9数据集)和文本生成,表现优于需专门训练分类器的离散扩散模型。
本文不仅提供了理论分析工具,还通过架构设计和训练策略创新,突破了连续扩散模型在离散空间应用的瓶颈,开启了统一离散与连续扩散建模的新篇章。
项目代码已开源,欢迎访问:patrickpynadath1.github.io/candi-lander
原论文链接:arxiv.org/abs/2510.22510