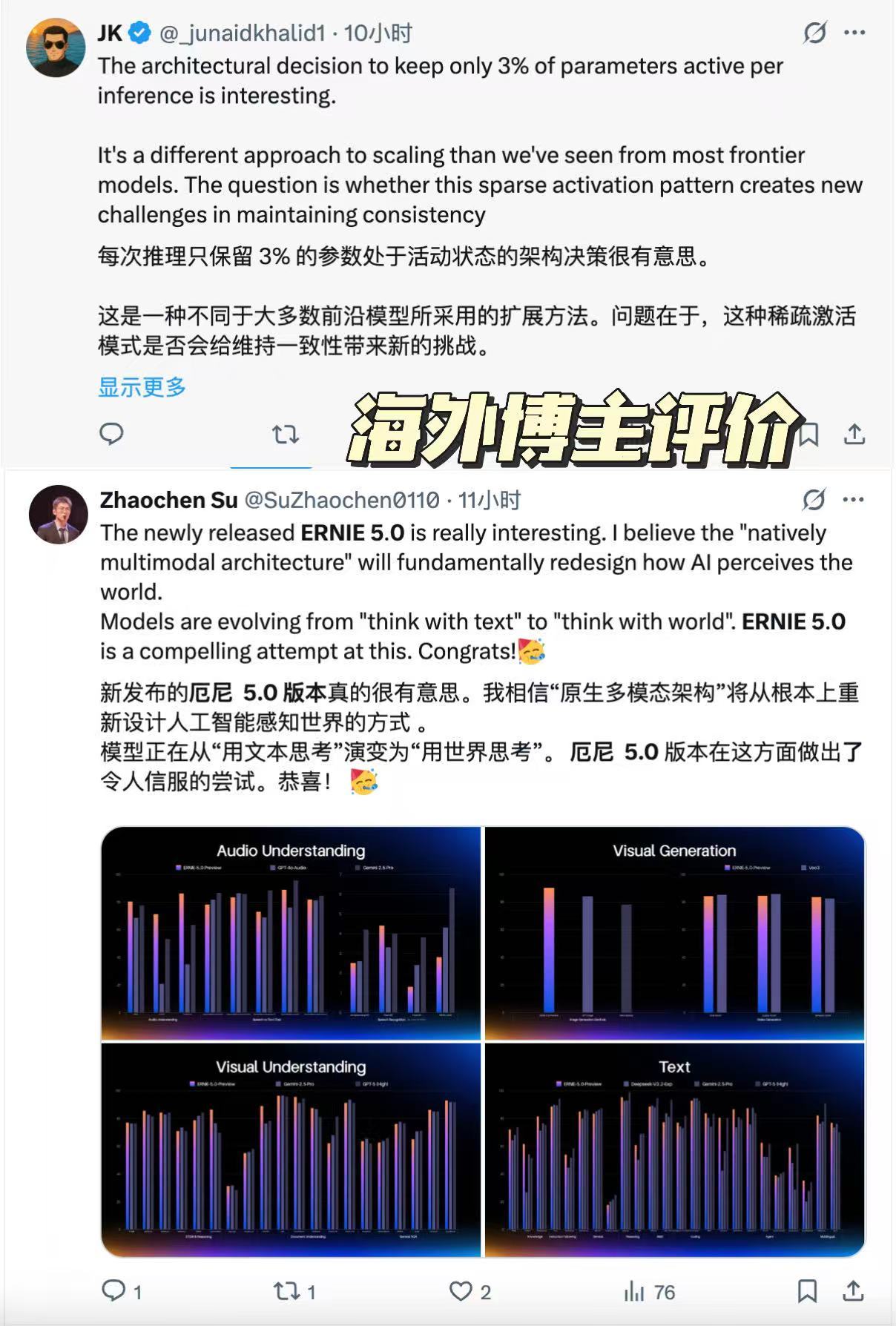
文心5.0凭什么让海外博主集体点赞?当百度在海外直播介绍文心5.0的时候,一个技术名词突然在X平台火了起来,Natively Omni-modal Modeling,翻译过来就是原生全模态。这个看起来有点拗口的概念,却让不少海外科技博主眼前一亮。有人直接评论说,这可能是大模型接下来发展的清晰方向。话说得这么绝对,到底什么来头?说白了就是一个核心差异,业界大多数多模态模型都是后期拼凑出来的。先训练文本模型,再训练图像模型,最后想办法把它们缝合在一起。就像搭积木,每块积木本来就是独立的,你硬要把它们搭成一个城堡。文心5.0不一样,它从训练的第一天开始,就把语言、图像、视频、音频这些数据混在一起喂给模型。模型从出生那刻起,就知道这个世界本来就是多模态的,不是只有文字或只有图片。这种训练方式带来的变化是根本性的。传统的多模态模型处理问题时,更像是在不同专家之间切换。你问它文字问题,它调用文本专家,你给它看图片,它切换到视觉专家。每个专家都很厉害,但协同起来总觉得差点意思。文心5.0的逻辑完全不同,它不是在不同模态之间来回切换,而是真正以一个统一的智能体在思考。你给它一段视频配一段文字描述,它能同时理解画面在说什么、文字在表达什么,以及两者之间的关系是什么。数据很能说明问题,文心5.0的模型参数量达到2.4万亿,在40多项权威基准测试中,它的语言和多模态理解能力已经可以和Gemini-2.5-Pro、GPT-5-High这些国际顶级模型持平。图像和视频生成能力,也达到了垂直领域专精模型的水平。为什么海外科技圈会对这个技术路线如此关注?因为多模态是目前AI领域公认的下一个突破口,但怎么做多模态,大家其实都在摸索。简单粗暴的后期融合方案虽然见效快,但天花板也很明显。模型越大、模态越多,这种拼凑式的方案就越力不从心。百度这次直接从源头解决问题,原生全模态意味着模型从一开始就被设计成多模态的,它的架构、训练方式、优化目标,全都是为多模态协同准备的。这种做法难度大、周期长、成本高,但一旦做成了,带来的提升是系统性的。文心5.0在多模态理解、指令遵循、创意写作、事实性、智能体规划这些方面的表现,都印证了这条路的潜力。更关键的是,这给整个行业指了一个方向。