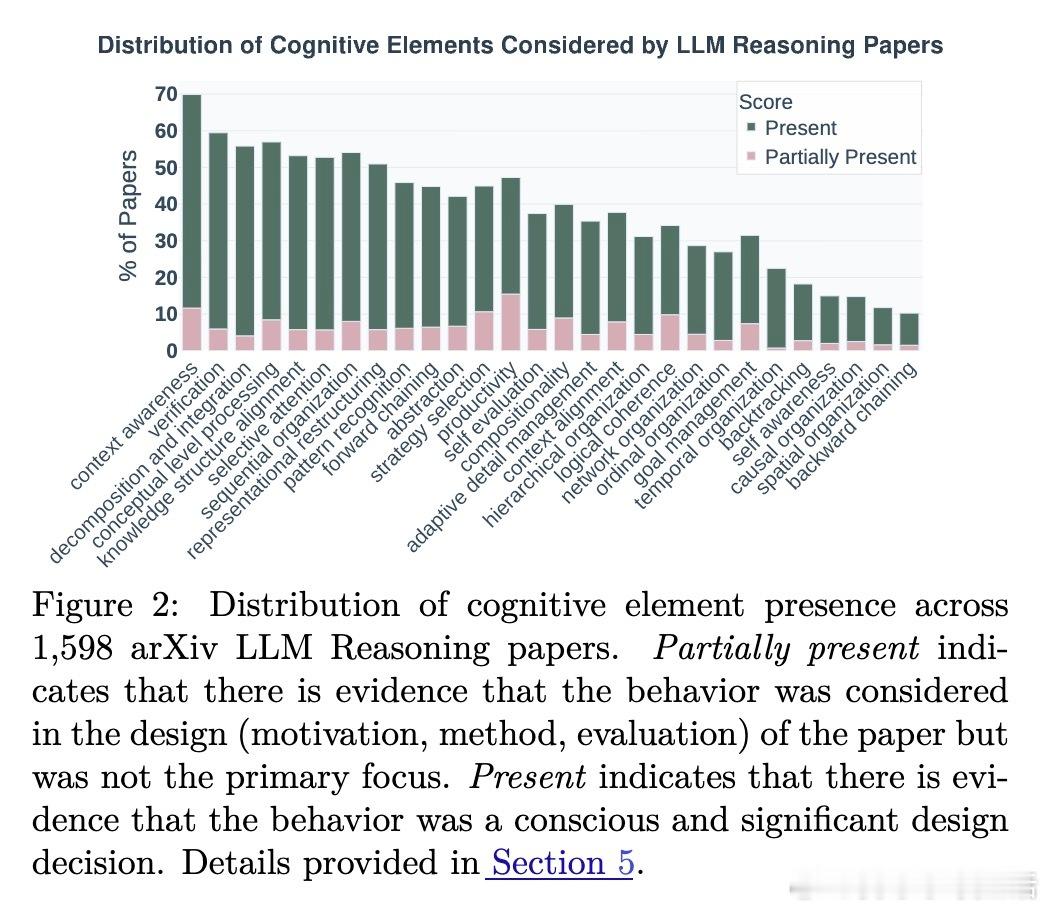
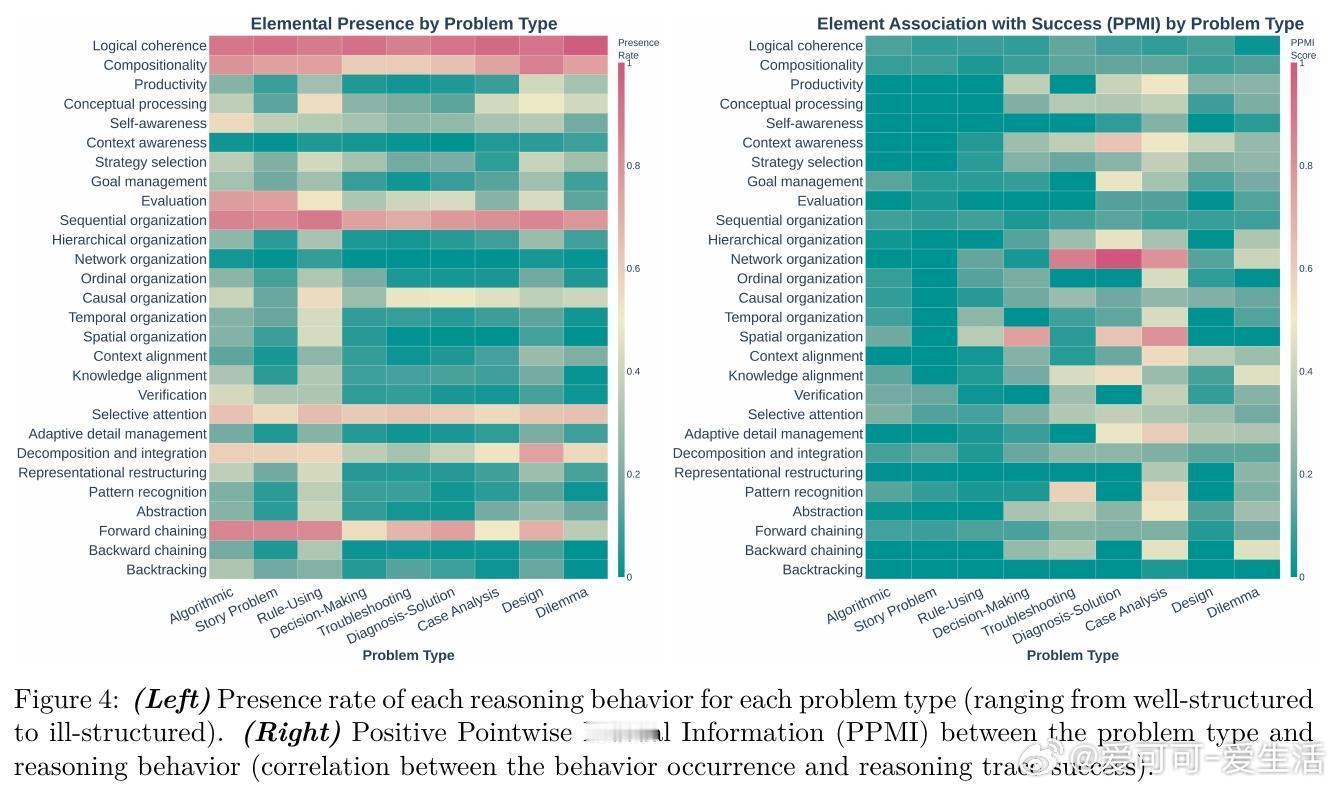
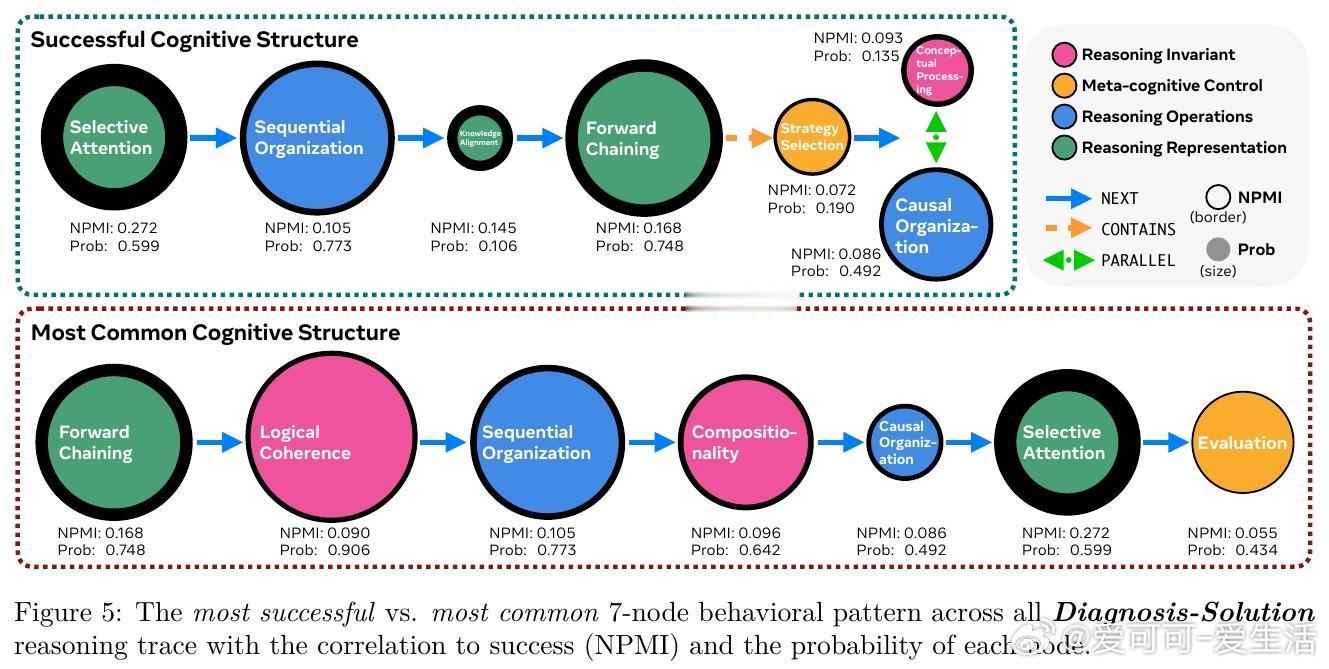
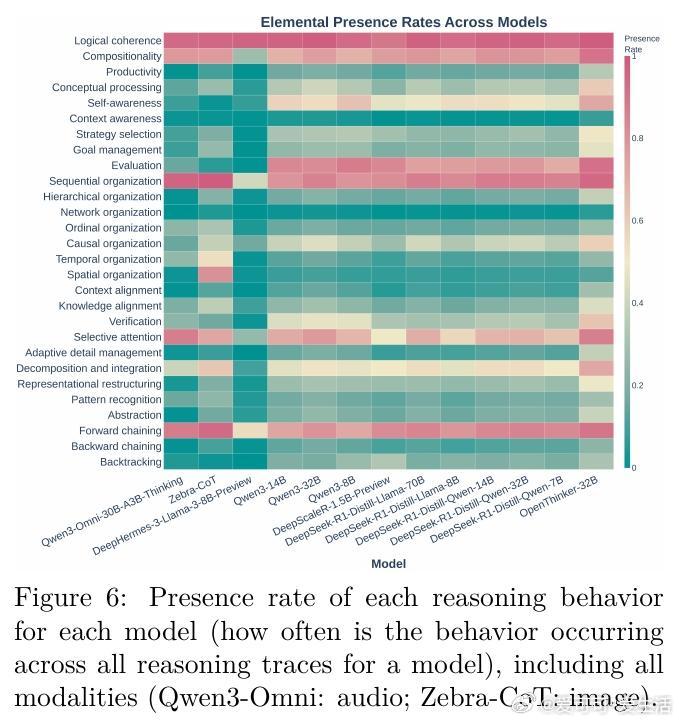
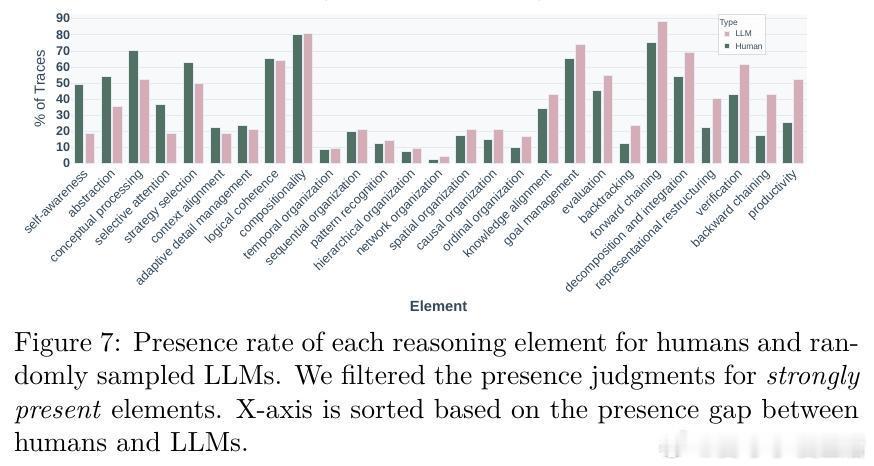
[LG]《Cognitive Foundations for Reasoning and Their Manifestation in LLMs》P Kargupta, S S Li, H Wang, J Lee... [University of Illinois Urbana-Champaign & University of Washington & Princeton University] (2025) 大规模语言模型(LLMs)在复杂问题上表现优异,却在更简单的变体上频频失误,揭示其推理机制与人类认知存在根本差异。本文首次提出涵盖28种认知元素(计算约束、元认知控制、知识表征及变换操作)的统一认知推理分类法,并基于此开发精细的认知评估框架,系统分析了17种模型(含文本、视觉、音频多模态)共17.1万条推理轨迹,以及54个人类思考轨迹,数据和代码均已公开(github.com/stellalisy/CognitiveFoundations,huggingface.co/collections/stellalisy/cognitive-foundations)。核心发现令人深思:人类推理强调层次结构和元认知监控,而模型则偏重浅层的顺序前向推理,特别在结构松散、目标模糊的“难题”类别表现出显著差异。更重要的是,模型虽具备与成功相关的推理行为库,却无法自发有效调用。元分析近1600篇LLM推理文献显示,研究社区大多集中于简单易量化的行为(如顺序组织55%、分解60%),却忽视了成功高度相关的元认知控制(自我意识16%、评估8%)。研究团队据此设计了“推理结构引导”——一种自动搭建成功推理行为序列的测试时干预,显著提升模型在复杂、开放性问题上的表现,最高提升60%。这表明模型潜藏推理能力未被完全激发,也证明认知科学理论能有效指导模型设计和评估。该工作不仅为LLM推理提供了跨学科、系统的认知框架,也开启了几个重要研究方向:如何从训练过程预测认知能力?如何突破泛化困境,实现结构化迁移?如何从可观察行为反推潜在认知机制?以及如何丰富和多样化推理行为的覆盖范围?同时,LLM为认知科学提供了规模化、可操控的实验平台,推动理论与实践的双向促进。一句话总结:要打造真正具备类人推理能力的AI,必须超越表层正确答案,关注推理的认知基础与结构化过程。唯有如此,我们才能突破当前模型的局限,实现更健壮、灵活和可解释的智能系统。详细解读及数据、方法、示例等内容,敬请访问论文全文:arxiv.org/abs/2511.16660 —— 来自认知科学与AI交叉前沿的最新突破,值得所有AI研究者深读反思。