编辑|Panda
长期以来,AI领域一直怀揣着一个宏大的梦想:创造出能够像人类一样直观理解物理世界,并在从未见过的任务和环境中游刃有余的智能体。
传统的强化学习方法往往比较笨拙,需要通过无数次的试错和海量的样本才能学到一点皮毛,这在奖励信号稀疏的现实环境中简直是灾难。
为了打破这一僵局,研究者们提出了「世界模型」这一概念,即让智能体在脑海中构建一个物理模拟器,通过预测未来状态来进行演练。
近年来,虽然能够生成精美像素画面的生成式模型层出不穷,但对于物理规划而言,沉溺于无关紧要的细节(如背景烟雾的流动)往往是低效的。真正的挑战在于,如何在错综复杂的原始视觉输入中提取抽象精髓。
这便引出了本研究的主角:JEPA-WM(联合嵌入预测世界模型)。
从名字也能看出来,这个模型与YannLeCun的JEPA(联合嵌入预测架构)紧密相关。事实上也确实如此,并且YannLeCun本人也是该论文的作者之一。更有意思的是,在这篇论文中,YannLeCun的所属机构为MetaFAIR。不知道这是不是他在Meta的最后一篇论文?

论文标题:WhatDrivesSuccessinPhysicalPlanningwithJoint-EmbeddingPredictiveWorldModels?
论文地址:https://arxiv.org/abs/2512.24497
JEPA-WM继承了JEPA的衣钵,不再纠结于像素级的重建,而是在高度抽象的表征空间内进行预判。在这项研究中,团队试图通过对架构、目标函数和规划算法的全方位扫描,揭示究竟是什么驱动了物理规划的成功,并试图为机器人装上一个更理性的「大脑」。
JEPA-WM核心方法
该团队将JEPA-WM的训练与规划流程形式化为一套统一的「终极指南」,重点在于如何在学习到的特征空间中模拟动力学。
1.层次化的编码与预测架构
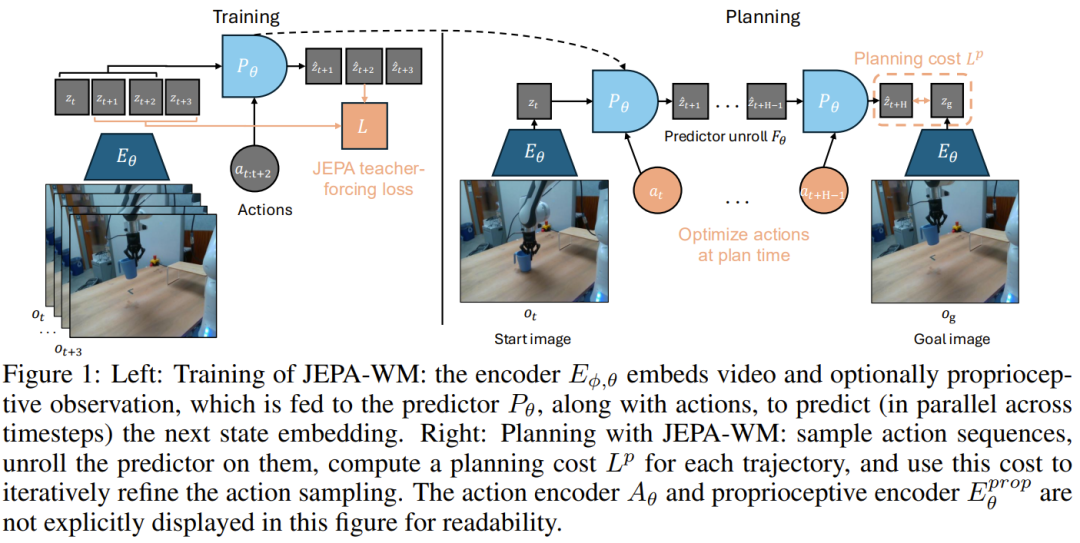
在训练阶段,模型主要由四部分交织而成:
视觉编码器
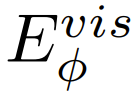
:使用预训练且冻结的ViT权重(如DINOv2或DINOv3)来提取空间特征,确保模型具备敏锐的视觉感知力。
本体感受编码器
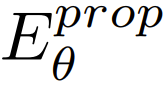
:一个浅层网络,用于捕捉机器人自身的关节角度和位姿,这与视觉信息共同构成了全局状态嵌入。
动作编码器A_θ:将机器人的控制指令转化为同维度的特征向量。
预测器P_θ:这是模型的心脏。它接收过去窗口内的观测序列
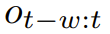
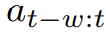
,在因果掩码的保护下,并行预测下一时刻的状态嵌入。
和动作序列
2.多步展开与动作调节细节
为了让模型不至于「走一步看一步」,研究者引入了多步展开损失
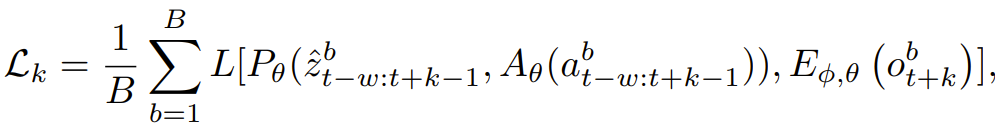
在训练时,模型不仅要预测下一帧,还要学会在没有真实观测反馈的情况下,基于自己的预测结果递归生成后续状态。为了提高效率,采用了截断反向传播(TBPTT),即只针对最后一步的预测误差计算梯度,而切断之前的累积梯度。
在动作信息如何干预预测过程上,该团队对比了三种关键方案:
特征调节(FeatureConditioning):将动作向量直接拼接到每一个视觉特征向量上,增加了预测器的隐藏层维度。
序列调节(SequenceConditioning):将动作作为一个独立的Token插入到ViT的输入序列中,通过注意力机制进行信息分发。
自适应层归一化(AdaLN):动作嵌入被投影为缩放和偏移参数,在每一个Transformer块中动态调制归一化统计量,这能有效防止动作信号在深层网络中「淡出」。
3.规划逻辑:在嵌入空间中寻找最优解
规划被建模为一个在动作空间
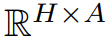
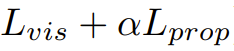
。通过多轮迭代,优化器会不断收敛动作分布,最终输出最优的第一步或前m步动作。
上的优化问题。给定初始观测o_t和目标图像o_g,智能体会在其内部模型中「试运行」N条候选路径。评价标准是预测终点的嵌入向量与目标嵌入向量之间的距离
实验与结果:从模拟器到真实机械臂
研究团队在Metaworld(42个操纵任务)、Push-T(物体推送)、PointMaze(导航)以及DROID(真实机械臂数据集)上进行了评估。
1.规划器之争:梯度vs采样
实验结果揭示了一个有趣的现象:在像Metaworld这种成本曲线相对平滑的任务中,基于梯度的Adam或GD优化器表现惊人,因为它们能顺着梯度迅速找到目标。但在2D导航(Wall,Maze)任务中,梯度法极易卡在局部极小值(例如对着墙猛撞而不懂得绕过门口),此时基于采样的交叉熵方法(CEM)凭借其探索能力完胜。
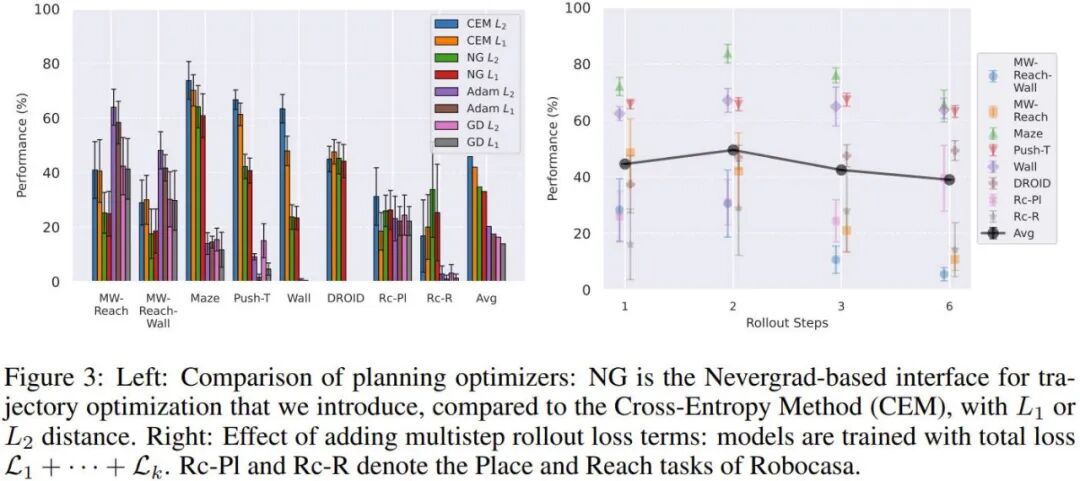
此外,新引入的Nevergrad(NG)规划器在无需调参的情况下展现了与CEM相当的实力,尤其适合跨任务迁移。
2.关键因素的「贡献度」
为了量化不同设计决策对智能体最终表现的影响,研究团队采用了一种严谨的控制变量法。
他们以一个基础配置(DINO-WM结合ViT-S编码器及6层预测器)为基准,独立改变每一个核心组件,从而在复杂的系统工程中剥离出真正驱动性能增长的关键因子。通过在Metaworld、Push-T等多种异构环境下进行数以万计的幕(Episode)测试,实验揭示了世界模型在处理物理逻辑时的内在偏好。以下是影响物理规划成败的核心贡献因素:
本体感受的显著增益:引入机器人内部状态信息(如关节角度、末端位姿)能够一致性地提高规划成功率。在Metaworld任务中,这能有效减少机械臂在目标点附近震荡的情况,提供更精准的距离感知。

编码器架构:DINO系列编码器(DINOv2/v3)在所有任务中均表现出对V-JEPA等视频编码器的明显优势。这归功于DINO强大的细粒度目标分割能力,这对于需要精确感知物体位置的操纵和导航任务至关重要。在视觉复杂度更高的真实数据(DROID)中,DINOv3的优势进一步扩大。
动作调节技术的微妙差异:实验发现AdaLN(自适应层归一化)调节技术在平均性能上表现最强,且计算效率更高。它通过在Transformer的每一层注入动作信息,有效防止了控制信号在深层网络传递过程中的消失,相比传统的特征拼接(ftcond)或序列拼接(seqcond)更具稳健性。

训练上下文长度的权衡:预测器需要至少2帧上下文来推断速度信息,这在W=1与W=2之间的巨大性能鸿沟中得到了印证。然而,盲目增加上下文长度(如W>5)反而有害,因为这会减少训练中看到的独特轨迹数量,并可能引入无用的梯度噪声。
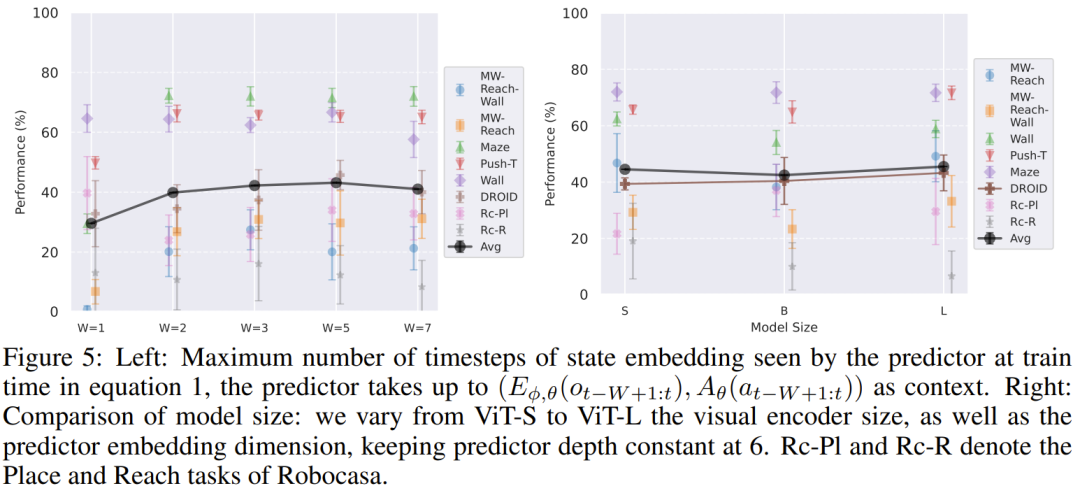
模型规模:这是一个令人意外的发现:在简单的模拟环境(如Maze,Wall)中,增大模型规模(从ViT-S到ViT-L)非但没有帮助,反而可能由于嵌入空间过于复杂而导致规划效率下降。但对于复杂的现实数据(DROID),大容量的编码器和更深的预测器则展现出了明确的正相关收益,说明任务的物理复杂度决定了智能体所需的智力上限。
多步损失的对齐作用:在训练中加入2步展开损失能显著改善预测器的长时稳定性,使其训练任务与测试时的递归规划任务更加对齐。对于最复杂的DROID任务,最佳的展开步数甚至需要达到6步。
3.提出的最优解
研究最终汇总所有洞察,提出了针对不同任务的最优配置:在模拟器中使用ViT-S配以AdaLN,而在真实复杂场景中使用DINOv3ViT-L配以12层深度的预测器。

在与DINO-WM和V-JEPA-2-AC的直接较量中,该模型在几乎所有维度上均取得了领先。
更多详情请参阅原论文。