Hi,我是 Chris,精彩文章都在我的博客 https://aichris.cc/。
Chris 在社群、公众号后台经常收到大家的提问,XX 模型免费吗?类似的问题,可见大家对 AI 最关注的可能还是价格。
今天就来分享一下如何在本地运行 AI 大模型,用到的是两个目前非常主流的本地大模型工具:Ollama 和 LM Studio。一个适合开发者,一个适合所有人。
为什么要本地运行大模型?在深入介绍工具之前,先说说本地运行的核心优势:
零费用:没有 API 调用计费,运行多少次都不花钱隐私安全:数据完全留在本地,不上传任何服务器,适合处理敏感信息无网络依赖:断网也能用,响应速度只取决于你的硬件️高度可定制:可以加载各种开源模型,自由调整参数
当然,本地运行也有局限:需要一定的硬件配置(主要是内存和显存),模型能力通常比 GPT-4、Claude 等顶级商业模型稍弱。但对于日常写作、代码辅助、文档问答等任务,完全够用。
OllamaOllama 是一个开源工具,让你能通过一行命令下载并运行各种主流开源大模型,堪称本地 AI 界的 "Docker"。它支持 macOS、Linux 和 Windows,背后维护活跃,更新很快。

官方网址:https://ollama.com/
如果你国内环境无法下载 Ollama,可以试试 https://cnb.cool/hex/ollama 下载安装。
 支持哪些模型?
支持哪些模型?Ollama 的模型库非常丰富,比如最新的 qwen3.6/Kimi-k2.6/deepseek-v4-pro/glm-5.1 等等,如果按照系列划分的话,主要包括:
Llama 系列:Meta 出品,综合能力强Qwen 系列:阿里出品,中文表现优秀Gemma 系列:Google 出品GLM 系列:智谱 AI 出品Minimax 系列:minimax 出品Mistral / Mixtral 系列:法国团队,代码能力突出DeepSeek 系列:国产推理模型,数学逻辑强Phi 系列:微软出品,小而精有非常多,这里没有全部列出,主要是看你电脑配置啦。
如何使用首先到官网 https://ollama.com/download 下载并安装即可。
然后下载安装你需要的模型即可,你可以在 https://ollama.com/search 找到合适的模型,打开详情页,比如 Chris 这里打开最新 qwen3.6 模型页面:

然后根据你电脑性能,选择合适的模型尺寸,比如 Chris 电脑是 48G 内存的配置:

就可以选择 qwen3.6:27b尺寸的模型进行下载,这时候需要打开电脑命令行工具,输入 ollama run qwen3.6:27b命令,进行下载并运行。

等待下载安装完成后,就可以输入 ollama run qwen3.6:27b运行了,Chris 这里使用的是 qwen3:14b 模型进行演示,整体流程一样的,这时候你就可以自由跟这个 AI 大模型对话了:
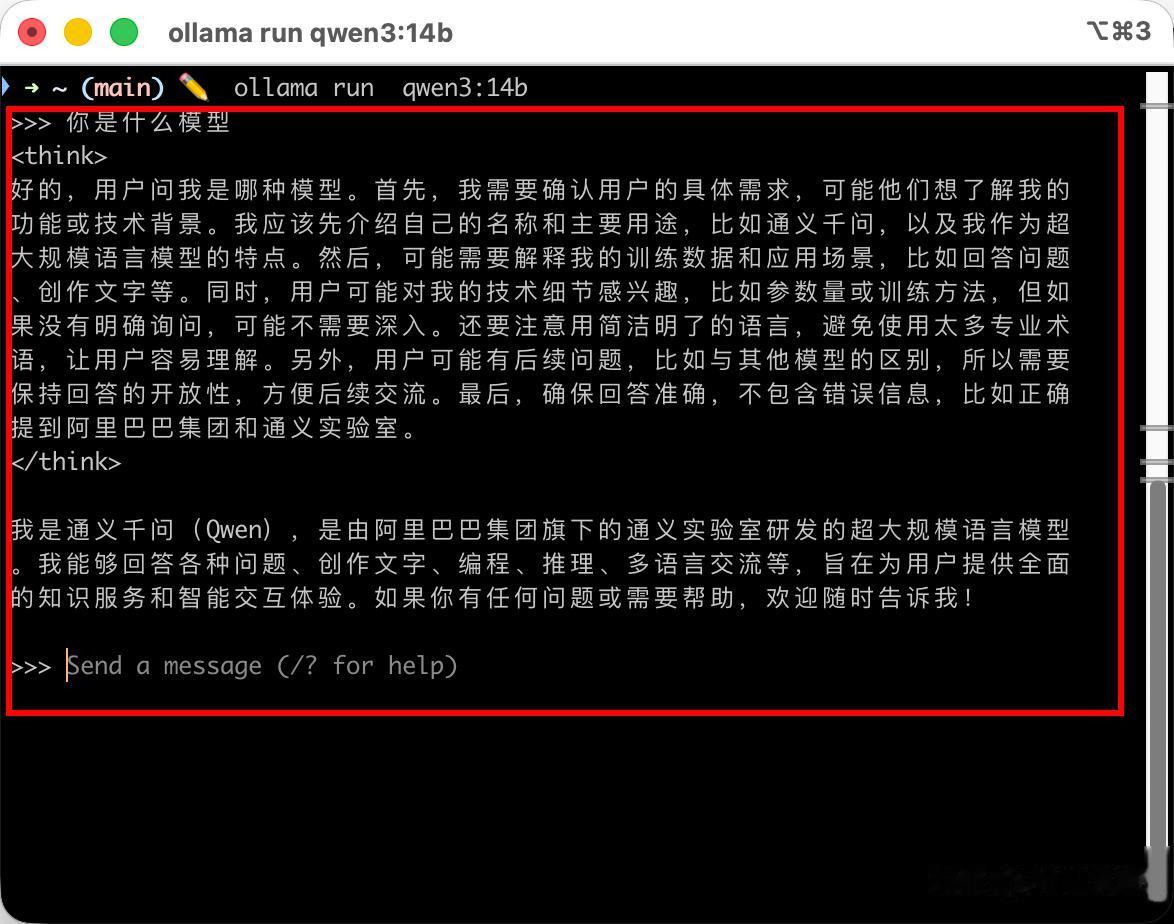
这里有几个 Ollama 常用命令如下:
# 下载并运行 Llama 3(8B 参数版本)ollama run llama3
# 下载并运行中文友好的 Qwen
ollama run qwen3
# 列出已安装的模型
ollama list
# 删除模型
ollama rm llama3
运行后直接在终端对话,或者通过它内置的 REST API(默认 http://localhost:11434)接入自己的应用,接口格式与 OpenAI API 兼容,几乎可以无缝替换。
国内模型加速下载如果你在国内下载模型很慢,可以试试 ModelScope 的方案,在 https://modelscope.cn/models?libraries=GGUF 找到合适的模型,然后把命令里面模型名称改成:ollama run modelscope.cn/{model-id},其中 {model-id} 替换成具体模型名称即可,格式是 {username}/{model},比如:
ollama run modelscope.cn/Qwen/Qwen2.5-3B-Instruct-GGUFollama run modelscope.cn/second-state/gemma-2-2b-it-GGUF
ollama run modelscope.cn/Shanghai_AI_Laboratory/internlm2_5-7b-chat-gguf
{model-id}获取方式如下,打开一个模型页面后,复制上面红色框内容:
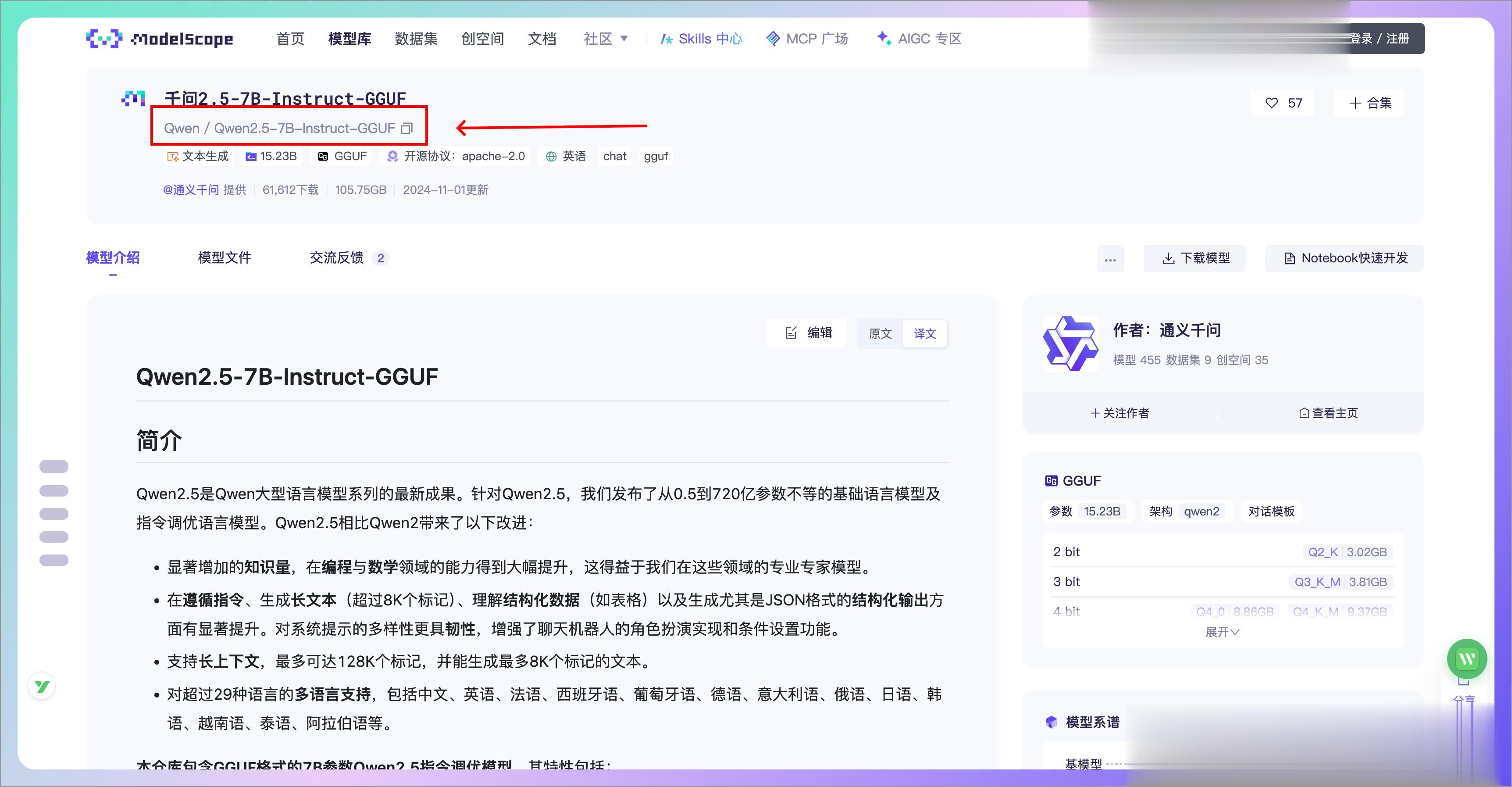
ModelScope社区上托管了上万个优质的GGUF格式的大模型(包括LLM和视觉多模态模型),并支持了Ollama框架和ModelScope平台的链接,通过简单的 ollama run 命令,就能直接加载运行ModelScope模型库上的GGUF模型。
参考文档:https://modelscope.cn/docs/models/advanced-usage/ollama-integration
客户端使用通常对于普通人来说,这个黑乎乎的命令行界面很不方便,所以 Chris 推荐下一些客户端页面可以使用,跟在网页使用一样:
1.Ollama 官方客户端在下载并安装好 Ollama 后,会自带一个客户端界面,你可以在输入框右下角直接选择要使用的 AI 模型,然后正常进行对话即可:
 2.ChatWise 客户端
2.ChatWise 客户端ChatWise 是一款本地 AI 大模型聊天客户端,官方网址:https://docs.chatwise.app/
使用方式也是类似,在对话页面左上角切换模型。
 3.WiseMindAI 客户端
3.WiseMindAI 客户端WiseMindAI 是一款本地优先的 AI 学习与知识工作台。不仅支持使用本地 AI 模型进行文档总结、对话,还支持 AI 知识库、知识卡片等功能。让资料处理、知识沉淀和成果输出都在一个地方完成。
官方网址:https://wisemindai.app/


当然,所有的对话记录你都可以保存成笔记、知识卡片,还可以做成海报直接分享,学习起来就特别的方便。
LM Studio如果你不喜欢命令行,LM Studio 是更好的选择。它提供了一个漂亮的桌面 GUI,让你像用普通软件一样管理和使用本地大模型,支持 macOS、Windows 和 Linux。
官方网址:https://lmstudio.ai/
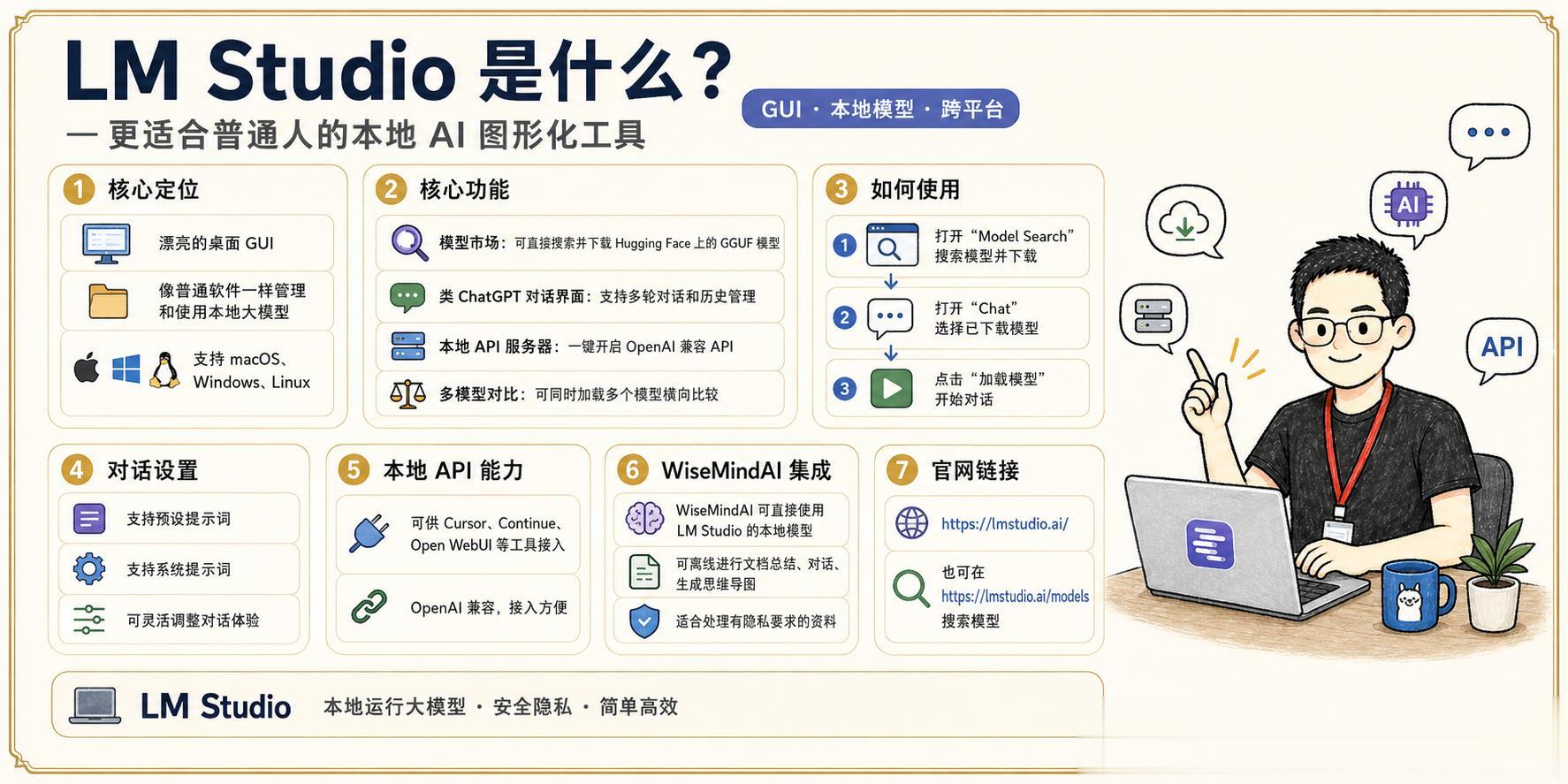
 核心功能
核心功能1. 模型市场内置模型搜索界面,可以直接搜索并下载 Hugging Face 上的 GGUF 格式模型,无需手动折腾。
2. 类 ChatGPT 对话界面下载好模型后,可以直接在软件里和模型对话,界面清晰,支持多轮对话历史管理。
3. 本地 API 服务器一键开启本地 OpenAI 兼容 API,让其他工具(如 Cursor、Continue、Open WebUI)直接接入你的本地模型。
4. 多模型对比可以同时加载多个模型,进行横向对比,找到最适合自己需求的那一个。
如何使用打开 LMStudio 后,在左侧“Model Search”菜单按钮,打开弹窗,直接选中你要使用的模型,点击右侧下载模型即可。
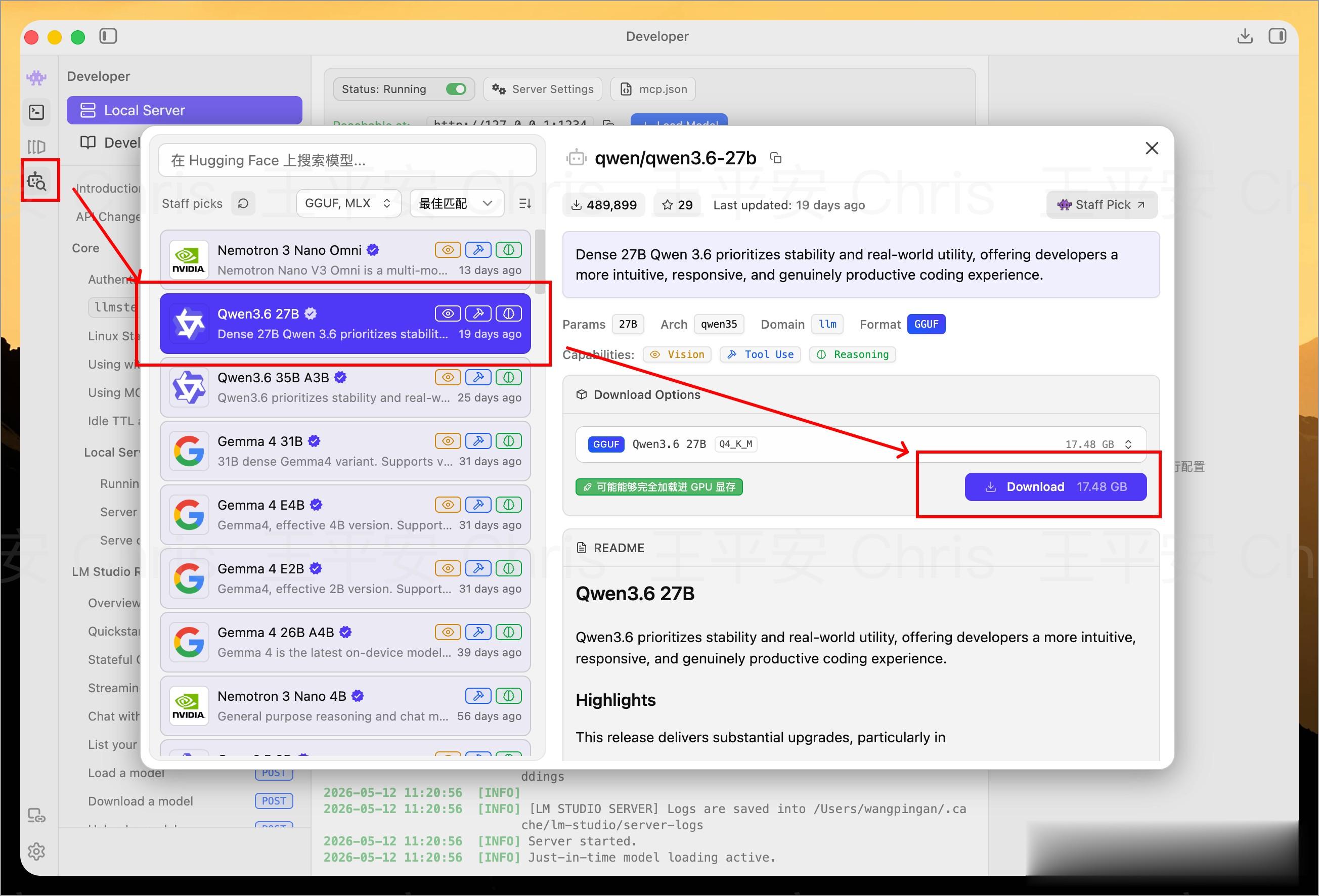
当然也可以到官网 https://lmstudio.ai/models 搜索并安装。
下载完成后,点击左侧第一个菜单“Chat”,在顶部选择你下载好的模型:

然后点击“加载模型”按钮:
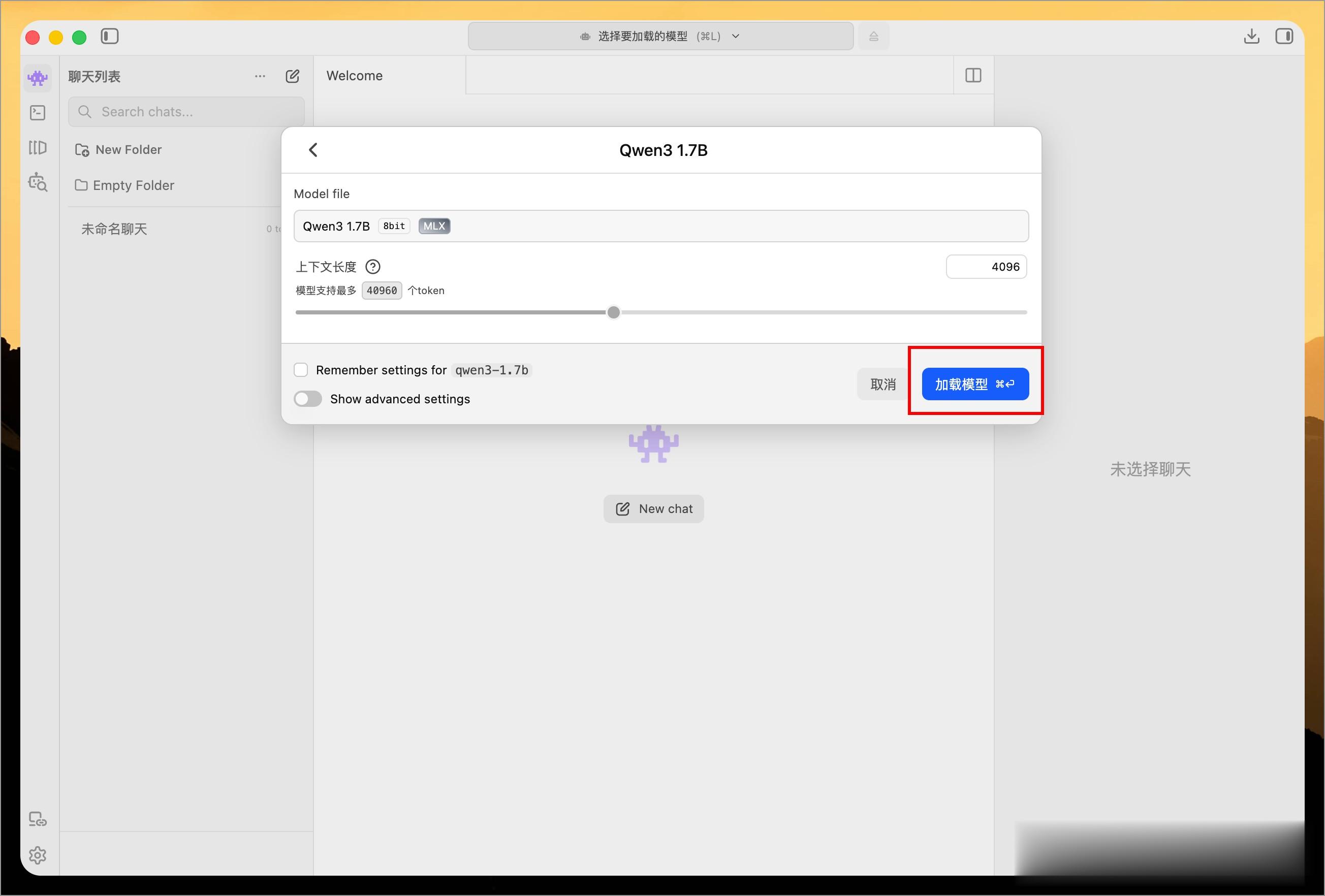
接下来就可以和这个 AI 模型对话了,并且 LM Studio 还支持很多对话设置,比如预设提示词、系统提示词等等:
当然,在前面说的 WiseMindAI 中,也可以直接使用 LMStudio 的本地 AI 模型:

这样就可以完全离线去使用各种 AI 功能啦,特别是一些有隐私要求的文档,你就可以用 WiseMindAI 在离线的情况下,进行文档总结、对话、生成思维导图等。
Ollama vs LM Studio:怎么选?对比维度 Ollama LM Studio 操作方式 命令行 图形界面 上手难度 需要基础终端知识 零门槛 API 集成 ✅ 原生支持,OpenAI 兼容 ✅ 支持,需手动开启 模型来源 Ollama 官方模型库 Hugging Face(GGUF 格式) 适合场景 开发集成、自动化脚本 日常对话、模型体验 性能开销 极低(纯后台服务) 稍高(带 GUI) 跨平台 macOS / Linux / Windows macOS / Windows / Linux
简单建议:
你是开发者,想把 AI 接入自己的应用 → 选 Ollama你只是想在电脑上和 AI 聊天,省掉订阅费 → 选 LM Studio两者也可以同时安装,各取所长,然后可以使用 WiseMindAI 进行学习和资料管理硬件要求参考本地运行大模型对硬件有一定要求,以下是常见模型的内存参考:
模型规模 推荐内存/显存 可用模型举例 3B 参数 4 GB Phi-4-mini、Gemma 3 3B 7B 参数 8 GB Llama 3.1 8B、Qwen 2.5 7B 14B 参数 16 GB Qwen 2.5 14B、Gemma 3 12B 32B+ 参数 32 GB+ Qwen 2.5 32B、Llama 3.3 70B(量化版)
没有独立显卡也没关系,两款工具都支持纯 CPU 运行,只是速度会慢一些。有 Apple Silicon(M1/M2/M3/M4)的 Mac 用户体验尤其好,Metal GPU 加速效果出色。
Chris 的模型推荐清单(2026 最新版)模型迭代太快,这份清单我会尽量保持更新。以下是我目前实际在用、或测试过觉得值得推荐的:
日常中文对话:qwen3.6:9b(阿里 Qwen 系列的最新一代,中文理解依然是开源里最强的,8GB 显存即可跑)代码辅助:qwen3.6:27b(2026 年 4 月刚发布,SWE-bench 成绩达到 77.2%,和 Claude Opus 4.5 打平,代码质量让我很惊喜)综合推理 / 长文档:gemma4(Google 出品,MoE 架构,256K 超长上下文,推理速度快,本地跑起来非常流畅)低配设备:phi4-mini(微软出品,3.8B 参数,4GB 内存可跑,速度 15-20 tokens/s,轻量但表现出乎意料地好)强推理 / 数学逻辑:deepseek-v3.2-exp:7b(DeepSeek 最新推理实验版,数学和逻辑分析很强)
如果你的机器内存够大(32GB+),可以试试 qwen3.5:72b 或 llama4:8b,综合质量已经非常接近云端的 GPT-4o mini,本地跑完全免费。
写在最后云端 AI 服务固然强大,但本地开源模型已经足以覆盖大多数日常需求。借助 Ollama 和 LM Studio,任何人都可以在自己的电脑上免费运行 AI 大模型,彻底告别 API 账单,同时获得更好的数据隐私保护。
不妨今天就下载试试——毕竟,免费的才是最贵的。