
机器之心发布
当OpenAI前CTOMiraMurati创立的ThinkingMachinesLab(TML)用Tinker创新性的将大模型训练抽象成forwardbackward,optimizerstep等⼀系列基本原语,分离了算法设计等部分与分布式训练基础设施关联,把“训练”大模型变成了简单的“函数调用”时,行业进入一场从“作坊式炼丹”到“工业化微调”的升级。
潞晨云微调SDK正式开放上线:基于ThinkingMachineLab开源的TinkerSDK构建,作为国内首个兼容Tinker范式且全面开放的Serverless微调平台,为复杂昂贵的强化学习提供更具成本优势的工业级解法——开发者无需囤卡,rollout→reward→update全链路按Token计价,让每一分钱都花在产生梯度的“刀刃”上。
拥抱后训练与RL
算法层与底层算力架构的解耦
随着OpenAIo1在推理能力上的突破,业界逐渐形成共识:大模型的能力突破已不再单纯依赖预训练(Pre-training)阶段的参数堆砌,后训练(Post-Training)特别是强化学习正成为决定模型实用价值的核心战场。以DeepSeek‑R1为例,仅靠强化学习训练,模型在AIME数学推理基准上的pass@1从15.6%提升至77.9%,充分展示了RL在低数据量条件下即可实现大幅能力跃升,迅速成为后训练赛道的新范式。
然而,摆在算法工程师面前的问题依旧严峻。强化学习涉及到更为复杂的系统设计,训练过程中存在一系列的问题,如多个模型的优化,数据的传递,以及模型权重的传递;一系列工程化的工作,给算法的设计带来了更多的困难,同时也对基础设施提出了更高的要求。
Tinker的出现,就是为了解决这个问题:把繁杂训练变成标准易用的API。
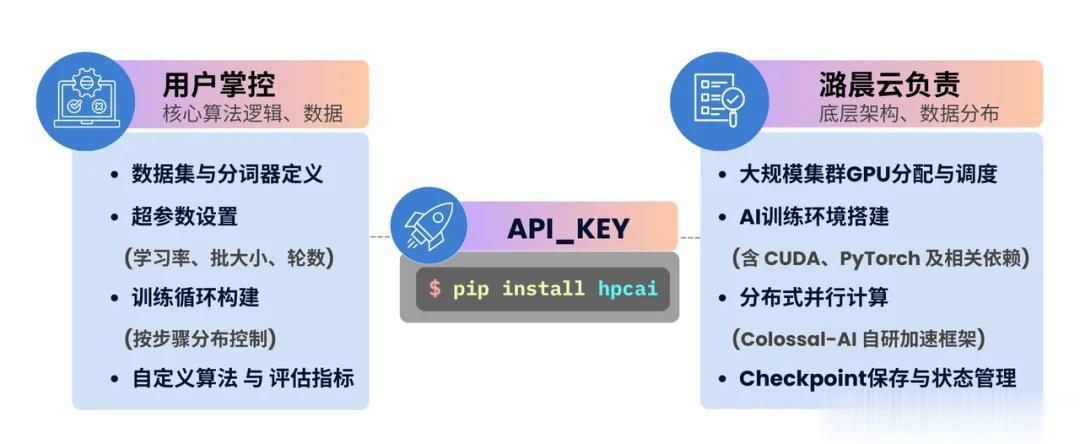
潞晨云把这一范式写进底层假设,算法设计与基础设施解耦——开发者只负责定义数据与Loss函数,底层的异构集群调度、并行策略优化、容错运维等应被封装为基础设施服务,对开发者实现全托管与无感支持。
致敬创新,更致力于落地。潞晨云微调SDK兼容Tinker接口,消除了从“算法灵感”到“模型落地”之间的工程化壁垒,在零代码微调与裸机全手写之间落在最佳平衡点,将研究精力和算力成本从集群运维还原至算法本身,带给开发者“本地写码,云端计算的“训练即服务(TrainingasaService)”流畅体验。

潞晨云微调SDK今日起全量开放,前150名用户通过专属链接注册,可获得30元Token使用额度:
https://cloud.luchentech.com/account/signup?invitation_code=JQZX
颠覆性人力效能比
1名算法工程师顶替原庞大Infra团队
潞晨云微调SDK的核心思路可以概括为:算法工程师定义算法逻辑,潞晨云搞定Infra。
在传统的开发中,用户往往要花大量精力去租赁合适的算力集群、管理环境配置、调训练框架和集群运维。但潞晨云将大模型训练拆解成了一组标准的函数原语,打通了从SFT到RL的全链路:
Forward&Backward:处理前向传播与梯度计算
OptimizerStep:执行权重更新策略
Sample(Rollout):做推理生成和评估,使用户不仅可以完成SFT,更能轻松构建PPO、GRPO、DPO等复杂的强化学习(RLHF/RLAIF)训练流
SaveState:管理模型检查点与状态保存
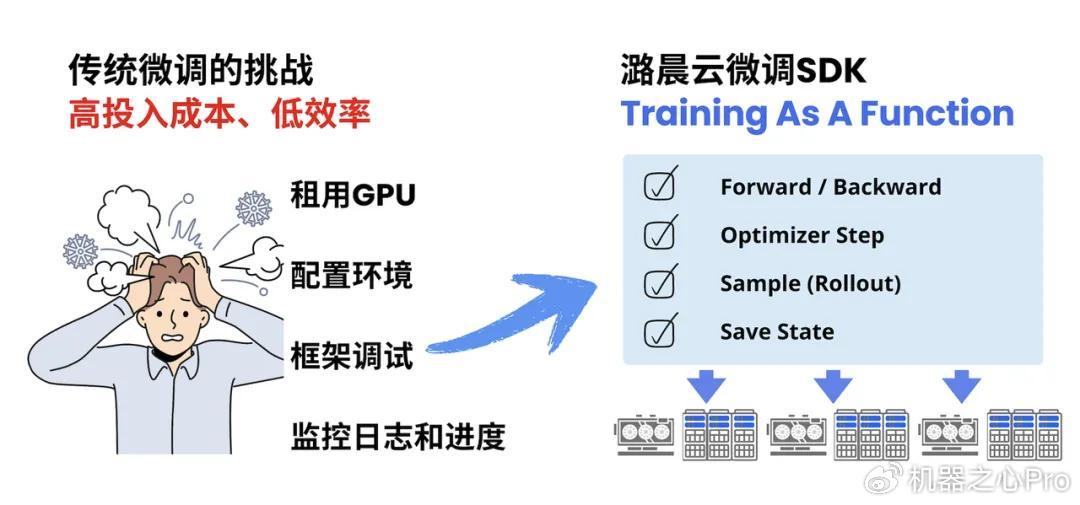
这意味着,用户可以在本地熟悉的JupyterNotebook或IDE里,用最标准的Python语法像搭积木一样自由组合,掌控训练逻辑的细节。
这种模式带来了颠覆性的‘人力效能比’提升:它将原本需要运维工程师、Infra工程师、平台工程师和算法工程师紧密配合的庞大团队,简化为了‘一个算法工程师’的独立闭环。
用户不再被底层繁杂的基建拖累,不再背负多职能的枷锁,也不再是黑盒填参的被动执行者,而是能够独立驾驭大规模训练流的主动设计师。无论是监督微调(SFT)还是更复杂的强化学习(RL)Pipeline,都能通过组合这些原子函数来灵活构建。
为什么这种体验如此丝滑?
为了实现极致的流畅度,潞晨云基于现有的GPU云服务架构实现了一套完整的后端系统。在具体实现中,潞晨云采用控制面与计算面分离设计,通过统⼀APIServer管理跨地域的多个GPU计算集群,实现多云部署能力。核心采用基于Future模式的异步API,所有训练操作⽀持非阻塞调用,用户无需等待GPU计算完成即可继续执行后续逻辑。
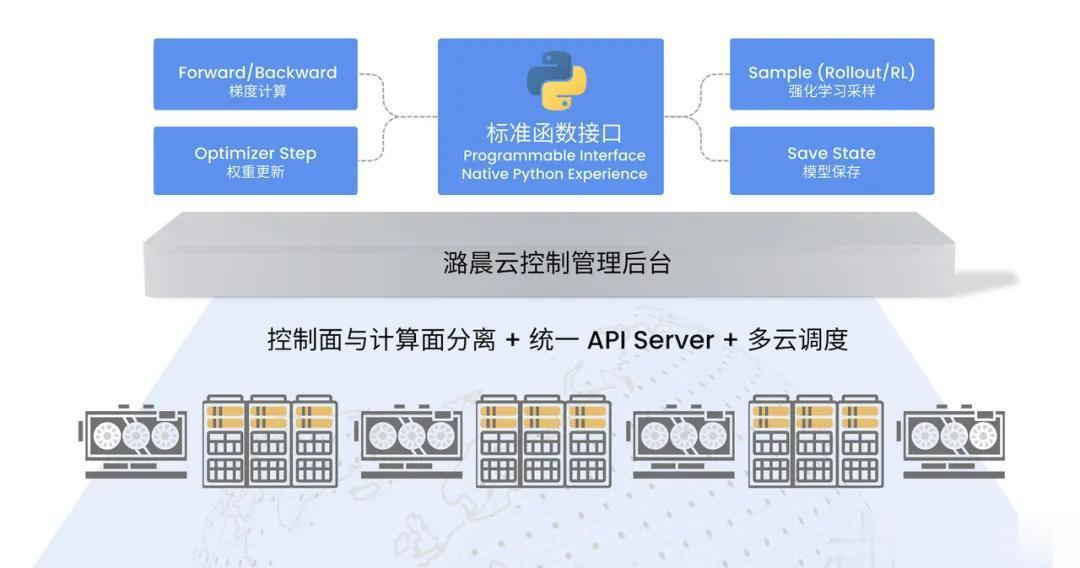
潞晨云微调SDK还具备智能队列系统,即使在资源洪峰期,任务也会自动进入持久化队列(PersistenceQueue),一旦底层资源可用,毫秒级启动,队列等待期间0计费,仅对实际prefill+sample+train的Token量收费,无资源闲置,将用户每一分钱都用在产生梯度的刀刃上。
模型微调的算力零售革命
从“包机租赁”到“按Token计费”
如果说“易用性”是后训练平台的入场券,那么“成本结构”则是决定谁能走得更远的护城河。
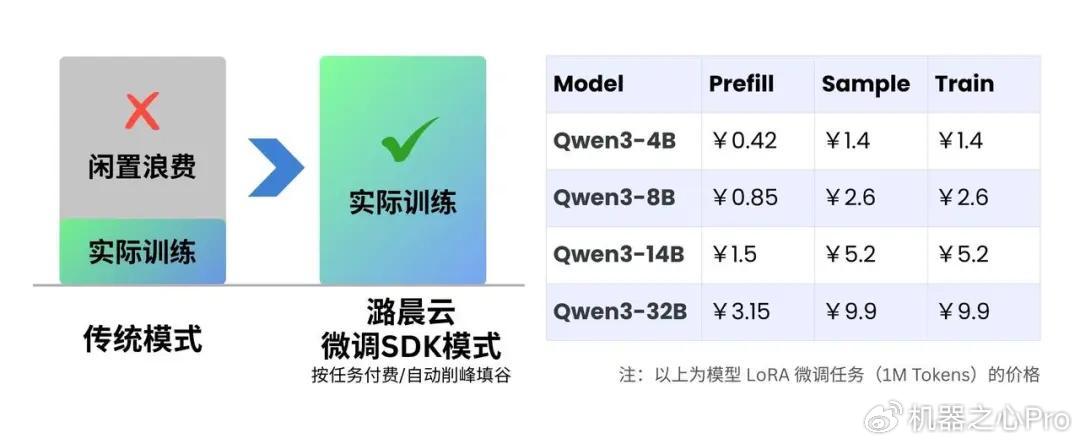
在传统云主机的“包机/时租”模式中,用户一直在为“过程”买单——无论是在加载数据、调试代码,还是仅仅在思考Loss函数,只要占用了显卡,计费表就在跳动。这种模式下,开发过程中有一半以上的预算都浪费在了这些没有实际产出的“垃圾时间”里。
潞晨云为微调大模型场景引入了Serverless架构,推行“按Token计费”的商业模式,将微调场景的算力服务切分到了最细的颗粒度:
为价值付费:就像使用推理API一样,用户只需为Prefill(输入)、Sample(推理输出)和Train(训练)产生的有效计算Tokens量付费。
其他环节全免费:本地代码调试、环境配置、数据预处理、模型Checkpoint保存……这些在传统租卡模式下分秒必争的环节,在潞晨云全部免费。
极致性价比:通常,RL需要同时维护高吞吐的推理集群(vLLM)和训练集群,算力成本极高。但在潞晨云上,实测基于官方Cookbook的math_rlrecipe跑通包含Rollout采样、Reward评分和PPO更新的完整RL流程(~300steps),总算力成本仅8.61元。这意味着,个体开发者也能低成本复现RLHF/RLAIF探索。
技术落地的三个场景
SFT与RL同时“开箱即用”
这种新模式,也将彻底改变不同领域开发者的工作流:
科研场景:告别资源焦虑
学术界,时间与算力往往是最紧缺的资源。研究人员不仅要面对繁琐的集群运维(Slurm/Docker配置),还要应对昂贵的实验复现成本。潞晨云微调SDK支持“白盒级”的科研探索,全面兼容TinkerAPI。研究人员可以自定义Evaluation逻辑、通过Forward/Backward,Sample等原语精确控制后训练和强化学习Pipeline,而无需关心底层的分布式实现,让实验复现成本大幅降低。
创业与独立开发:极速验证MVP
对于初创团队,“快”是生存根本。利用潞晨云微调SDK的Serverless特性,开发者无需等待资源排期。配合极低的Token成本,实测从pipinstall到跑通一个包含1000条样本的SFT或RL微调实验,仅需数分钟。这种极致的边际成本,让创业者敢于在有限预算下快速迭代Reward模型,实现真正的“低成本试错”。
工业级落地:复杂架构突围
在金融、医疗等垂直领域的工业应用中,已有微调API往往难以应对复杂的异构架构与RLHF/RLAIF需求。潞晨云微调SDK允许工程师通过train_step自由定义Loss逻辑与强化学习奖励函数。开发者拥有对模型权重与训练细节的完整控制权,实现端到端定制。
极简实战:三步上手
没有复杂的集群配置,没有冗长的Docker构建。使用潞晨云微调SDK,训练一个大模型就像写普通Python脚本一样简单:
1.Install&Import:
Bash
pipinstallhpcai
2.InitializeClient:目前已支持Qwen3系列(4B-32B),更多模型即将上线
Python
importhpcai
#初始化LoRA训练客户端,无需配置复杂的分布式参数
training_client=service_client.create_lora_training_client(
base_model="Qwen/Qwen3-4B",
rank=32
)
3.DefineTrainingLoop&Run:像在本地写PyTorch一样,拥有对训练循环的完整控制权:
Python
#训练循环:完全可控forstepinrange(target_steps):
#前向与反向传播
fwd_bwd=training_client.forward_backward(batch,"cross_entropy")
#优化器步进
optim=training_client.optim_step(adam_params)
#实时获取Loss进行监控
loss=fwd_bwd.result().metrics.get("loss:mean")
目前,微调SDK已覆盖Qwen3系列模型(4B、8B、14B、32B),支持监督学习和强化学习训练方式,并将持续扩展更多模型能力与细分落地场景,大家也可以向官⽅提交需求push更新。
平台还准备了开箱即用的HPC-AICookbook,提供包括DeepSeek-R1GRPO算法、基于Verifier的数学推理、自定义Reward函数等复杂RL场景的完整代码实现。开发者无需从零构建复杂的PPO/GRPO流水线,只需复制Cookbook中的“配方”,运行轻量级本地train.py脚本,即可驱动云端复杂的分布式RL训练流,在潞晨云上复现具备复杂逻辑推理能力的SOTA模型。
现在体验
后训练正从学术支线升级为工程主线,AI基础设施的终极形态应该是“零认知负荷”——开发者只需描述数据与算法,其余(租卡、配环境、并行策略、运维调度、故障自愈,乃至RL涉及的一系列工程化的工作)全部下沉到用户无感。当GPU闲置成本趋近于0,环境配置时间趋近于0,长序列RLHF也能按Token即时计费,应用创新效率直接逼近算力上限。
潞晨云微调SDK今日起全量开放:
无需白名单,无需预约
前150名注册即得30元体验金(填写专属福利码JQZX)
把资源弹性交给平台,把算法自由度留给自己,每一分钱都用在产生梯度的刀刃上!
立即体验:https://cloud.luchentech.com/fine-tuning
使用文档:https://cloud.luchentech.com/doc/docs/finetune-sdk/
Reference
[1]TinkerSDK:https://github.com/thinking-machines-lab/tinker