
引用
Kou B, Chen S, Wang Z, et al. Is Model Attention Aligned with Human Attention? An Empirical Study on Large Language Models for Code Generation[J]. arXiv preprint arXiv:2306.01220, 2023.
论文: https://arxiv.org/pdf/2306.01220.pdf
摘要
本文调查了LLMs在代码生成过程中是否关注自然语言描述的与人类程序员相同的部分。对一个流行的基准测试HumanEval上的五个LLMs的分析显示,LLMs的关注与程序员的关注存在一致性的不对齐。此外,本文发现LLMs的代码生成准确性与它们与人类程序员的对齐之间没有相关性。通过定量实验证明,通过扰动方法计算的注意力在定量实验和用户研究中都得到了验证,这种方法最符合人类注意力,并且在人类程序员中得到了持续的青睐。本文的发现强调了需要人类对齐的LLMs以提高可解释性和程序员信任。
1 引言
最近,大型语言模型(LLMs)在代码生成方面取得了巨大成功,但目前尚不清楚LLMs如何从自然语言中生成正确的代码。这主要归因于LLMs的规模和复杂性。例如,原始的Codex模型包含120亿参数,太大了无法解释。最近的一些研究调查了LLMs对代码的可解释性。它们要么使用探索性任务来了解LLMs对代码学到了什么属性,要么分析LLMs产生的自注意力值。其中没有一项研究分析LLMs是否以与人类程序员类似的方式生成代码。此外,它们都只尝试了一种解释方法,对于基于LLMs的代码生成模型,缺乏对不同解释方法的全面分析。
为了填补这一空白,本文首次努力揭示LLMs的代码生成过程,分析LLMs在生成代码时关注人类语言的哪些部分。本文进行了一项大规模研究,检查了五个LLMs和人类程序员的164个Python编程任务上的注意力对齐情况,该基准由OpenAI开发用于评估Codex和随后的模型。直觉是LLMs应该根据自然语言描述中的显著词生成代码,与人类程序员类似,而不是生成微不足道的标记。
由于现有的代码生成基准中没有包含程序员注意信息(即程序员在编写代码时关注哪些单词或短语),我们根据来自HumanEval的164个编程任务创建了第一个程序员注意力数据集。我们通过请两位经验丰富的程序员手动标记他们认为对解决每个编程任务重要的单词和短语来捕捉程序员的注意力。此外,为了捕捉LLMs的注意力,我们基于XAI文献实施了十二种不同的注意力计算方法,包括六种基于自注意力的方法、四种基于梯度的方法和两种基于扰动的方法。为了确保我们的发现适用于不同的LLMs,我们尝试了五种不同的预训练LLMs,包括InCoder、CoderGen、PolyCoder、CodeParrot和GPT-J-6B。
我们的研究揭示了LLMs代码生成过程的一些重要见解。首先,我们发现在所有五个模型中,无论采用何种注意力计算方法,LLMs与人类程序员之间存在一致的不对齐。这意味着LLMs在代码生成过程中并不像真实程序员那样关注自然语言的相同部分,对基于LLMs的代码生成模型的鲁棒性和泛化性提出了担忧。此外,我们没有发现模型准确性和注意力对齐之间存在显著的相关性。这意味着更准确的代码生成模型不一定与真实程序员更好地对齐,它们可能只是比其他模型更好地适应训练数据。最后,基于扰动的方法产生的模型注意力与程序员注意力最为一致,也是真实程序员最喜欢的方法。这表明研究人员和开发人员可能希望利用基于扰动的方法来解释LLMs在代码生成中的行为。
基于这些发现,我们总结了LLM基础代码生成领域未来研究的几个机会:
我们进行了第一次关于LLMs和人类程序员在164个Python编程任务上的注意力对齐的全面研究,突显了了解LLMs代码生成过程的重要性。我们提炼了一系列为未来基于LLMs的代码生成模型和这些模型的解释方法制定的含义和实用指南。我们首次公开了164个Python任务的程序员注意力数据集,可用于开发新的与人类对齐的模型,并评估用于代码生成模型的新的XAI方法。2 技术介绍
2.1 代码生成、基准测试和度量标准
代码生成通常指生成代码的任何任务。根据模型接收的输入类型,代码生成任务可分为从自然语言预测、从IDE中不完整的代码上下文预测、从示例或测试用例预测、从用另一种语言编写的代码预测(即代码翻译)、从错误代码预测(如程序修复)等。此外,根据生成代码的类型,代码生成任务可以分为下一个令牌(例如,API调用、变量名)预处理、单语句完成、函数完成等。
在这项工作中,我们专注于从自然语言描述中生成函数的代码生成任务。自2021年OpenAI Codex和GitHub Copilot突破以来,这种代码生成任务在搜索社区越来越受欢迎。在此任务设置中,给定函数头和自然语言的任务描述,LLM应根据任务描述完成函数。
代码生成模型通常在众源编程基准上进行评估。OpenAI开发了一个名为HumanEval的Python程序,并使用它来评估原始Codex模型及其变体。HumanEval包括164个Python编程任务和基本事实解决方案。它是迄今为止最流行的基准测试,并已用于评估大多数基于LLM的代码生成模型。此外,MBPP是一个警报基准,有大约1000个众包入门级Python编程问题和解决方案。CodeXGLUE是另一个大型基准测试,不仅涵盖代码生成任务,还涵盖代码翻译和代码摘要任务。APP包括来自多个网站的10K编码练习任务,如CodeWars和AtCoder。CodeContests包括13.5K编码竞争任务,测试用例比APPS多。
通常使用两种类型的度量来评估基于LLM的代码生成模型的性能。首先,由于前面提到的许多基准测试都包括测试用例,因此可以简单地运行测试用例以评估生成的代码的正确性。此类别中的非典型指标是Pass@k,最初由 OpenAI提出.Pass@k代表正确求解的编程任务数,其中k指 LLM 生成的代码采样数。如果有k样本通过了一个测试中的所有测试用例,则认为任务已正确解决。例如,Codex模型实在Pass@1中实现了28.8% 并在Pass@100中实现了70.2%.由于测试用例的数量是有限的,通过任务的所有测试用例并不一定意味着生成的代码是完全正确的。因此,先验工作还测量生成的代码和搁浅真相解决方案之间的相似性,作为正确性的代理。BLEU 和 CodeBLEU)是常用的相似性度量。
2.2 模特注意力
在这项工作中,我们使用模型注意力来指代NL描述中不同标记对生成代码的重要性。它暗示了模型在代码生成过程中“关注”输入的哪些部分。这一观点与XAI文献中的特征重要性、显著性映射和特征归因相似。下面我们将描述XAI文献中的三种注意力计算方法。
2.2.1 基于自注意的方法
基于转换器的语言模型通常采用自注意机制来解释文本数据中的长期依赖性。因此,计算模型注意力的最直接方法是利用基于变换器的模型中的自我注意力核心。然而,这里的一个挑战是决定一种适当的方式,将来自不同注意力层的不同注意力头的自我注意力聚合起来。例如,GPT-3有96个注意力层,每个层有96个注意头。不同的负责人经常处理输入的不同部分。例如,图2显示了当生成两个不同的令牌时,CodeGen中两个不同注意力头的第一层的自我注意力得分。最近的几项工作要么总结了来自所有转换层的注意力,要么提取了来自第一转换层的词汇注意力。然而,据我们所知,没有标准来衡量自我注意力得分。

图2: 在不同的生成步骤中,CodeGen的第一层中的不同节点头识别的最重要的令牌
2.2.2 梯度法基于梯度的方法
利用模型预测相对于输入特征的梯度来计算模型的注意力。基于梯度的方法的计算包括两个不同的步骤:(1)执行感兴趣的输入的前向传递,以及(2)通过神经网络的层使用反向传播来计算梯度。通过分析这些梯度的大小,这些方法可以识别哪些输入标记在确定输出时最有影响力。例如,积分梯度是一种基于梯度的方法,它计算模型输出的梯度相对于每个输入特征的积分
基于梯度的方法的计算包括两个不同的步骤:(1)执行感兴趣的输入的前向传递,以及(2)通过神经网络的层使用反向传播来计算梯度。通过分析这些梯度的大小,这些方法可以识别哪些输入标记在确定输出时最有影响力。例如,积分梯度是一种基于梯度的方法,它计算模型输出的梯度相对于每个输入特征的积分。
2.2.3 基于摄动的方法
与前两类方法不同,基于摄动方法是模型不可知的。这些方法首先扰动模型的输入,然后根据输出差异计算模型的注意力。LIME和SHAP是两种流行的基于扰动的方法。LIME通过用更简单的模型(例如,线性分类器)近似特定的模型预测来生成局部解释。SHAP基于博弈论通过扰动输入来增强LIME,并使用Shapely值来估计不同于kens的重要性。这些方法通常需要大量的带孔样本来确保估计的准确性。此外,LIMEa和SHAP只通过删除标记来干扰输入,这可能会显著改变输入的含义或结构。为了解决这一限制,最近的基于扰动的方法倾向于用上下文中类似或语义相关的标记来替换标记。他们经常使用掩蔽的语言管理模型,如BERT来预测相似或语义相关的标记,以替换输入中的现有标记。
2.3 程序员注意力数据集
由于现有的代码生成基准都不包含程序员注意力信息(即程序员在编写代码时认为哪些单词或短语很重要),我们首先基于HumanEval的164个编程任务创建了第一个程序员注意力数据集。前两位作者拥有五年以上的编程经验,他们在任务描述中手动标记了他们认为对解决编程任务很重要的单词和短语。
在标记过程之前,两位标记人员一起完成了几个任务,以熟悉编程任务和代码解决方案。在标注过程中,两位标注者首先独立标注了20个任务描述。第一轮标签的Cohen Kappa评分为0.68。两位标签作者讨论了分歧,并总结了他们都认为重要的四类关键词:
数据类型:描述代码应输入或输出的数据类型的关键字,如“字符串”、“数字”或“列表”运算符:描述代码应对数据执行的操作的关键字,如“比较”、“排序”、“筛选”或“搜索”条件:表示代码执行条件的关键字,如“if”、“else”、“when”和“for”属性:被操纵数据和操作的重要属性,包括量词(如“all”、“one”)、形容词(如“first”、“closer”)和副词(如“every”、“none”)在解决了分歧之后,他们继续标注剩余的124个任务描述。最后,他们讨论了自己的标签,并解决了标签中的所有分歧。表1显示了我们程序员注意力数据集的统计数据。平均而言,每个任务描述有93个单词,其中10个单词被两个标注者都认为是重要的。在所有四种类型的关键字中,属性关键字(35.6%)被两个标注者标注的频率最高,其次是操作者(26.3%)、条件关键字(21.7%)和数据类型关键字(15.5%)。表2显示了标记任务描述的两个示例。这四种类型的关键字用不同的颜色标记。

3 实验评估
3.1 实验设置
研究问题。在本文中,我们研究以下研究问题:
RQ1:模型注意力与人的注意力在多大程度上一致?
RQ2:代码生成精度更高的LLM与真正的程序员有更好的一致性吗?
RQ3:不同注意力计算方法对注意力对齐的影响是什么?
RQ4:真正的程序员最喜欢哪种注意力计算方法?
RQ1模型注意力与人的注意力在多大程度上一致?
实验设计。我们收集了顶部K个LLM关注的关键字,并将它们与程序员注意力数据集中标记为重要的关键字进行比较。由于每个任务描述的标记关键字的平均值为12.9(表1),我们设置K到5,10,20。我们使用两个指标,关键词覆盖率和Cohen的Kappat来衡量LLM和人类程序员之间的注意力一致性。
结果。表4a、表4b和表4c分别给出了使用基于扰动、基于梯度和基于自身注意力的方法计算注意力得分时的注意力对齐结果。我们发现,与其他两类方法相比,这两种基于扰动的方法在所有设置中都能在很大程度上与程序员的注意力保持一致。第5.3节详细比较了不同的注意力计算方法。在这里,为了简洁起见,我们重点解释基于扰动的方法的结果。
表4a、表4b和表4c分别给出了使用基于扰动、基于梯度和基于自身注意力的方法计算注意力得分时的注意力对齐结果。我们发现,与其他两类方法相比,这两种基于扰动的方法在所有设置中都能在很大程度上与程序员的注意力保持一致。第5.3节详细比较了不同的注意力计算方法。在这里,为了简洁起见,我们重点解释基于扰动的方法的结果。
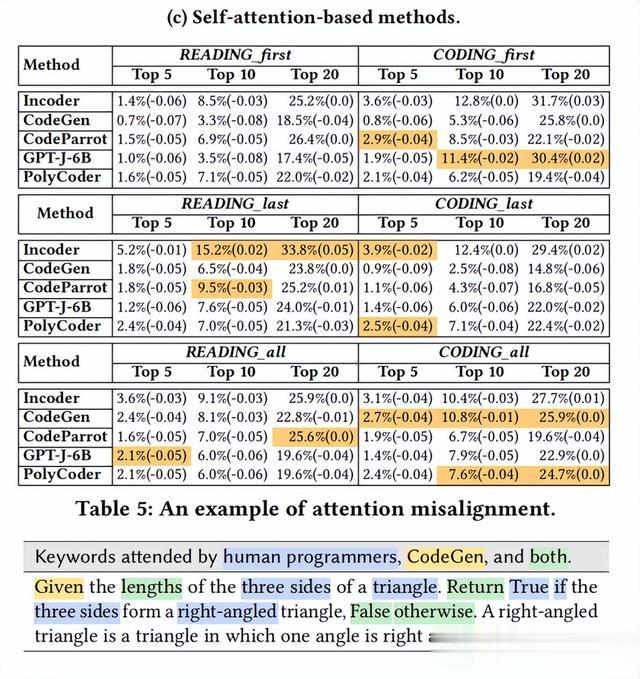
对于所有五个LLM,随着更多的关键词被考虑,关键词覆盖率和Cohen的Kappa都会增加。然而,即使K为20,关键词覆盖率仍低于50%。此外,Co-hen的Kappa总是低于0.2,这表明很少或没有对齐。这些结果表明,在生成代码时,LLM和程序员之间存在一致的注意力错位。表5显示了当使用SHAP计算注意力时,人类程序员和CodeGen之间的注意力错位的示例。
为了进一步理解模型和程序注意力之间的差异,我们使用关键词覆盖率最高的注意力计算方法SHAP分析了CodeGen选择的关键词的分布,CodeGen是所有五个模型中与人类程序员最一致的模型。表6显示了CodeGen和人类参与的不同类型关键字的分布。总体而言,CodeGen和人类在任务描述中关注相似数量的名词和动词,但人类程序员对形容词和数字更敏感。卡方检验结果证实了CodeGen和人类程序员参与的不同类型关键字分布之间的统计差异(=57.9, df=7, p < 1.仔细看表5,人类程序员会考虑更多的形容词/副词(例如,直角),并且更善于确定条件关键字(例如,“if”)。

RQ2 注意力错位是否会导致代码生成错误?
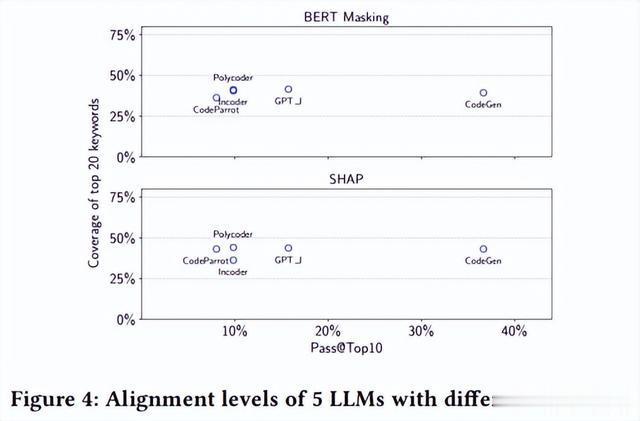
实验设计。为了回答这个问题,我们分析了LLM的准确性和注意力一致性水平之间的关系。图4显示了前10个关键词的覆盖率与LLM之间的关系Pass@10. BERT 掩膜而非SHAP获得的结果表明,更准确的LLM不一定与人类程序员有更高的注意力一致性。我们进一步对这两个结果进行了Spearman秩相关检验。结果证实没有显著的相关性(p=0.553和p=0.866)。其他设置的实验(例如,不同K) 显示出类似的结果。
结果。我们进一步对CodeGen生成的20个随机采样的正确代码解决方案进行了案例研究。我们定性地分析了LLM无法生成正确代码的原因,以及这种错误是否可以用注意力错位来解释。在这篇分析中,我们重点关注CodeGen产生的代码生成错误,因为它在五种LLM中具有最好的准确性。我们确定了代码生成错误中的三种常见模式:缺失逻辑、代码幻觉和代码重复。我们在下面解释它们:
缺少逻辑是指LLM忽略任务描述中所需的条件、操作或功能的情况。代码幻觉是指LLM生成与任务描述无关的提取代码的情况。代码重复是指LLM重复生成相同或相似的代码,但重复是不必要的。在分析的20个代码生成错误中,14个是逻辑缺失,3个是代码幻觉,3个为代码重复。在仔细检查了SHAP计算的注意力后,我们发现模型注意力为这些代码生成错误的根本原因提供了有价值的见解。例如,图5显示了一个示例,其中CodeGen生成的代码只是返回一个空列表,而不考虑详细的任务描述。我们还可以观察到,SHAP选择的前5个注意力关键词没有覆盖任务描述中的任何重要单词,例如“返回单词列表”。图6显示了代码幻觉的一个示例,其中CodeGen生成了一个额外的断言语句,并导致正确输入的断言失败。最后,图7显示了一个代码重复的例子,其中CodeGen进入了一个无限循环的重复代码,该循环以前已经生成过(第16-18行与第13-15行)。对模型注意力的分析表明,CodeGen未能捕捉到对任务描述的重要远距离注意力(第3-9行),而是专注于新生成的代码(第13-15行)。

RQ3 注意力计算方法对对齐的影响是什么?
实验设计。根据我们在RQ1中的结果,与其他方法相比,基于扰动的方法持续产生更高的注意力对齐。在RQ3中,我们进一步比较了每个类别中不同方法的性能。如表4a所示,与BERT掩蔽相比,SHAP在所有情况下都产生更高的Cohen’s Kappa,在除一种情况外的所有情况下产生更高关键词覆盖率。对于基于梯度的方法,表4b显示,在所有情况下,Input×gradient_codingpro-比所有其他三种方法产生更高的对齐度。
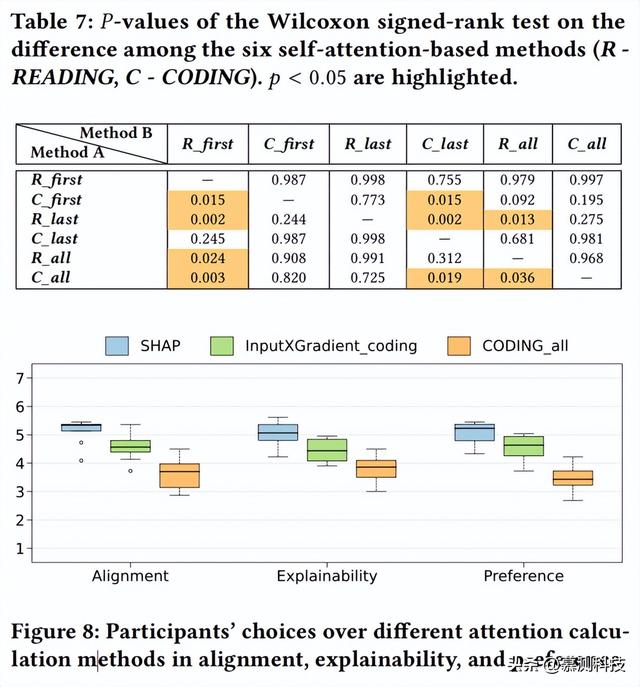
此外,对于input×Gradient_codingmethods,与在输入阅读过程中仅聚合注意力核心(即reading)相比,聚合所有生成步骤的注意力得分(即CODING)显示出更好的一致性。然而,对于基于自我注意的方法,我们没有观察到这种模式(表4c)。没有一种基于自我注意的方法比其他方法表现得更好。我们进一步进行了Wilcoxonsigned秩检验来证实这一点。如表7所示,CODING_first、READING_last和CODING_all的性能相对优于其他三种方法。然而,这三种方法之间的性能差异并不显著。
结果。表6显示了CodeGen在每个类别中使用最佳注意力计算方法时关注的不同类型关键词的分布。虽然这三种方法都倾向于名词、形容词/副词和动词的数量相似,但Input×Gradient_coding和CODING_all都更关注连词。此外,与其他两种方法相比,SHAP对数字更敏感。
RQ4 哪种注意力计算方法最受欢迎?
实验设计。图8显示了参与者对SHAP、InputXGradi_ent_encoding和coding_alling与自己注意力的一致性、计算注意力的可解释性和自己的偏好的评估(第4.4节中的Q1-Q3)。总的来说,SHAPis在所有三个方面都优于其他两种方法。
结果。SHAP的注意力对齐平均值为5.13,而InputXGradient_coding和CODING_allar的平均值分别为4.59和3.62 SHAP 和 InputXGradient_coding和SHAPandCODING_allar之间的平均差异均具有统计学意义(Welch’s t-test, p=0.05和p=0.004). 这些结果与我们在RQ1和RQ3中的发现一致,其中SHAPoutp在注意力对齐方面执行所有其他方法。
参与者认为SHAP比InputXGradient_coding,p=0.02)和CODING_all(平均差值:1.26,p=0.00001).然而,根据参与者对他们对LLM的信任的回答(第4.4节中的问题6),22名参与者中有14人表示缺乏信心和信任,即使在看到基于注意力的平面图之后也是如此。
例如,参考代码。”参与者还要求提供更精细的注意力图。具体来说,他们希望看到输入的哪些部分负责生成输出的哪些部分。例如,P10说,“[我想知道]LLM是如何决定输入和输出的,驱动不同世代的歧视性单词是什么。”参与者还表现出比其他两种方法更喜欢SHAP。SHAP与InputXGradient_coding和SHAP与CODING_all之间的平均偏好差异分别为5.04和4.56(Welch’s t-test p=0.05)和5.04对3.48(Welch’s t-test p=0.00009)。
转述:丁自民