
什么样的思维链,能「教会」学生更好地推理?
许多人都有这样的学习体验:内容过于熟悉,难以带来新的收获;内容过于陌生,又往往超出理解能力,难以消化吸收。
类似的现象同样出现在大语言模型的推理蒸馏中。来自能力更强的教师模型的思维链,可能过于晦涩,学生模型难以掌握其推理模式;而与学生认知相近的教师模型,其推理轨迹又常常缺乏新信息,难以带来实质提升。
因此,要获得理想的蒸馏效果,关键在于为不同学生模型选择恰好合适的数据,在「熟悉」与「陌生」之间找到最佳平衡。然而,现有基于概率的筛选或度量方法(如Perplexity)难以刻画这种细粒度的适配关系。
那么,是否存在一种直观且易于计算的数据适配度指标,能够量化这种平衡?
来自复旦大学和上海人工智能实验室的研究者提出了一种简单而有效的度量方法,Rank-SurprisalRatio(RSR):
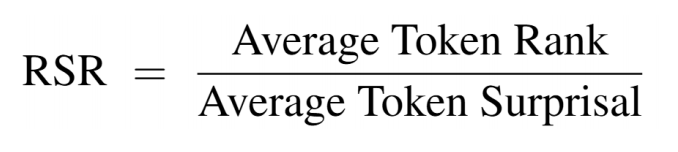
RSR从学生模型的视角出发,综合考虑样本的信息量与对齐程度,旨在找出那些既足够「新」,又未超出学生认知边界的推理数据。
在大规模蒸馏实验中,RSR与学生模型后训练性能的相关性高达0.86,并且可以直接用于筛选推理轨迹以及选择教师模型,无需实际训练即可找到更合适的思维链数据。

反直觉的现象
长思维链(CoT)的生成被普遍认为是大模型推理能力的核心。相应地,包含长思维链的推理轨迹常被视为高质量的监督信号,可以用于有监督微调(SFT)训练学生模型,或助力强化学习的冷启动。
但越来越多的实验呈现出一个反直觉现象:教师模型越强,学生模型未必学得越好。
在这篇工作中,作者系统性地构建了11个teacher(教师模型)×5个student(学生模型)的蒸馏实验,覆盖从4B到671B的主流推理模型。结果显示:
teacher的参数规模、推理准确率与student的推理提升相关性很弱;
同一个teacher的数据在不同student上的训练效果差异显著;
跨模型家族的teacher(如GPT-OSS→Qwen)往往效果更差;
推理数据是否「适合」当前student是关键。
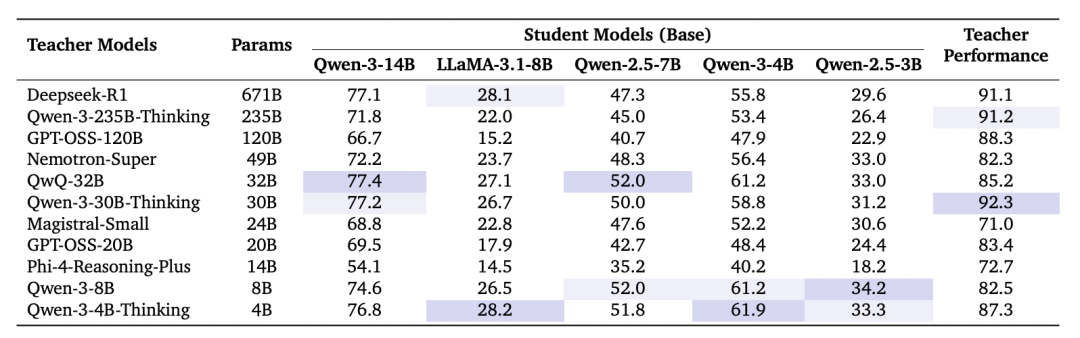
表一:蒸馏实验结果,在多个数学benchmark上评测student模型使用teacher数据训练后的性能。
现有数据筛选方法的问题
当前主流的数据筛选或评估方法,大多依赖一个信号:student模型生成该数据的概率(perplexity/log-likelihood/surprisal),认为student觉得「自然」的数据就更容易学。
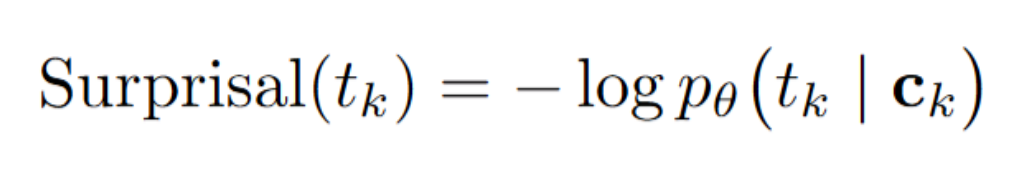
但问题在于:
太「自然」的推理数据,往往信息增量有限;
真正有价值的推理数据,恰恰是student尚未充分掌握的部分。
这就引出了论文试图解决的核心矛盾——InformativeAlignmentChallenge:如何在提供新知识的informativeness与符合学生当前认知的alignment之间取得平衡?
关键洞察
「绝对陌生(Absoluteunfamiliarity)+相对熟悉(Relativefamiliarity)」的推理数据最有学习价值
面对看似难以兼顾的「熟悉-陌生」的平衡,作者从token级别重新审视student的预测分布,提出一个直观、但之前被忽略的视角:
Informativeness关注的是当前token在概率层面的绝对陌生度,可由Surprisal(−logp/负对数似然)刻画;
Alignment关注的是当前token对比其它候选token的相对熟悉度,可由Rank(在词表预测中的名次)衡量。
在这一视角下,一个token可以同时满足:
被student生成的概率不高(informative)
但在候选词表中排名靠前(aligned)
因此,informativeness与alignment并非天然冲突。恰恰是同时满足这两点的token,构成了最适合student学习的推理数据。
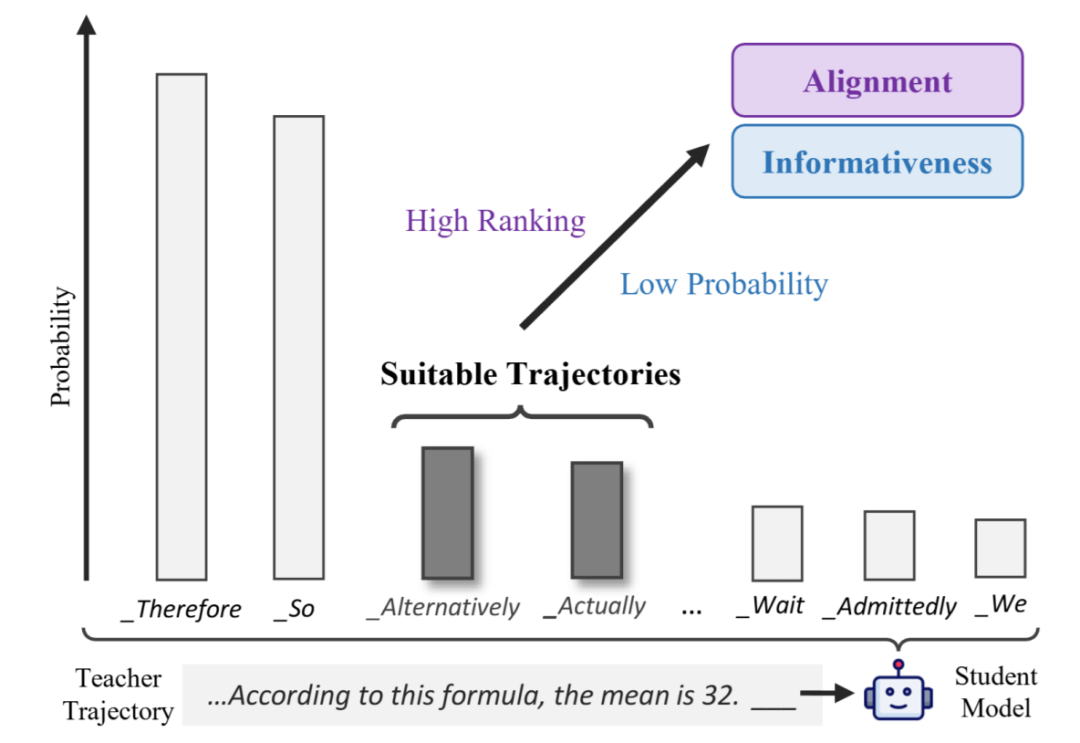
图一:Rank-SurprisalRatio的设计动机——合适的推理数据应当兼顾informativeness与alignment
直观的指标:Rank-SurprisalRatio
基于前文在token级别的观察,以及相关仿真分析与数学推导,论文提出了一个形式上极其简洁的样本级指标:
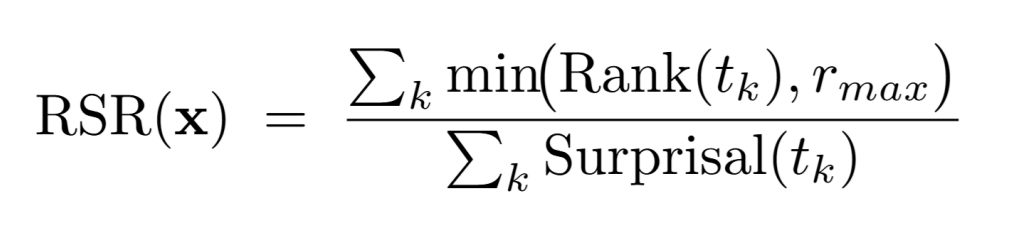
直觉解释:
分子(Rank)越小,表示当前样本越符合student的行为模式,对齐程度(alignment)越高;
分母(Surprisal)越大,表示当前样本提供的信息量越充分,信息性(informativeness)越强;
RSR越小→信息量与对齐程度的平衡越好。
在实现上:
仅需对student进行一次前向计算;
不依赖verifier或额外测试数据;
融合了rankclipping与surprisal加权平均机制,在极端情况下具有更好的数值稳定性。
实验:与训练效果的相关性
作者将RSR与多种已有指标进行了对比,包括teacher模型及训练数据的若干统计量、常用的数据质量评估方法、基于概率的指标,以及其他基于student模型计算的指标。
实验结果在5个student模型上高度一致:RSR与student模型后训练性能的Spearman相关系数平均达到0.86,显著高于其它指标。
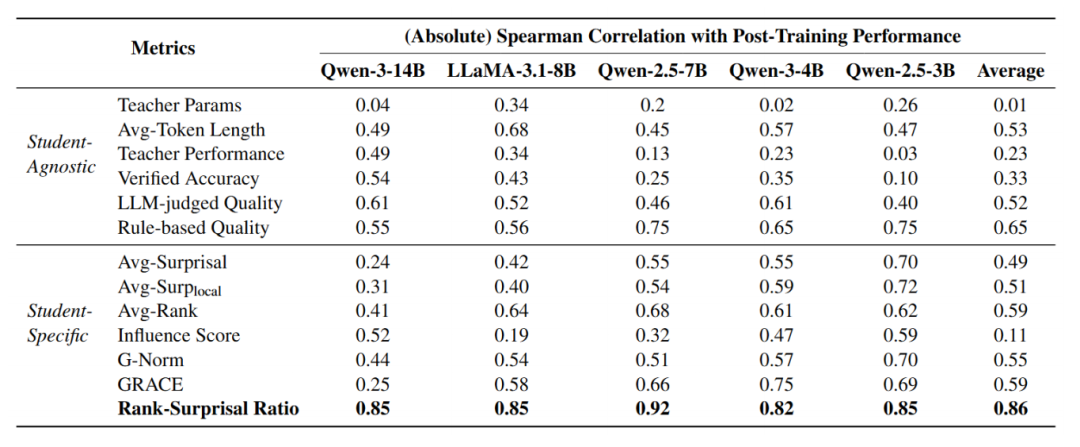
表二:不同指标与模型后训练推理性能之间的相关性
在实际场景中的应用
场景1:TrajectorySelection(选择最合适的推理轨迹数据)
在该场景中,针对训练集中的每一道题目,作者从多个teacher模型生成的33条候选思维链中,依据不同指标选择一条最合适的推理轨迹,从而构建用于训练student的推理数据集。
实验结果表明,基于Rank-SurprisalRatio筛选得到的数据,在不同student模型上训练后均取得了最优的推理性能,优于其它方法。
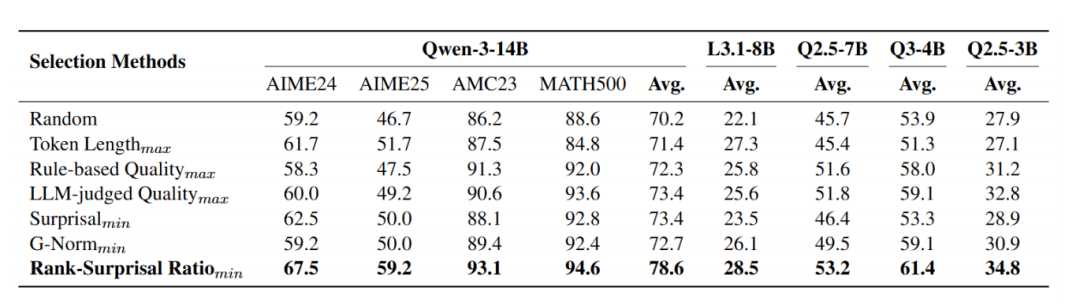
表三:不同数据筛选方法的后训练性能
场景2:TeacherSelection(选择最合适的教师模型)
在该场景中,作者仅使用每个teacher模型生成的200条推理轨迹来估计其与不同student的适配程度,从而模拟实际蒸馏前的teacher选择过程。
实验结果显示,RSR能稳定选出接近oracle(真实最优)的teacher模型,整体表现优于其它方法。
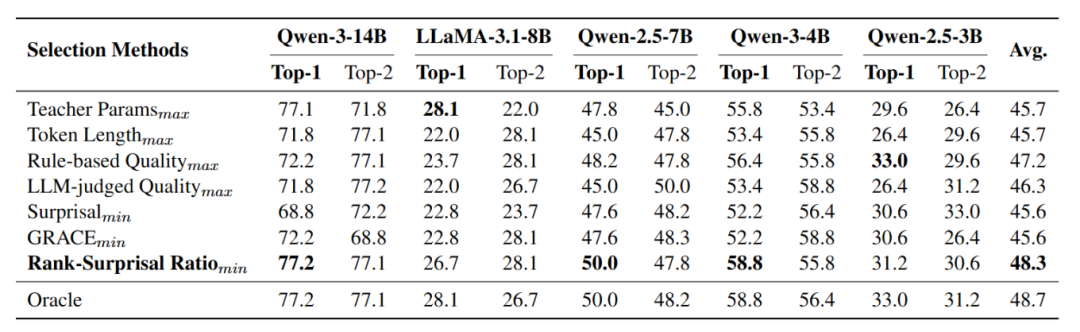
表三:不同teacher模型选择方法的表现
结语
这项工作重新审视了推理蒸馏中一个看似简单却难以回答的的问题:什么样的推理轨迹能「教会」student更好地推理。通过将token的相对熟悉度(rank)与绝对信息量(surprisal)结合,Rank-SurprisalRatio给出了一个直观、易于计算、且在大规模实验中被验证有效的答案。
更重要的是,RSR并不依赖额外的评估数据或验证器,而是直接从student的视角出发刻画数据价值。这使它不仅是一个分析工具,也具备作为实际数据工程指标的潜力。
向前看,这种「informativealignment」的视角或许可以进一步扩展到:
更通用的reasoning任务(如code、tooluse);
推理轨迹的重写与合成,而不仅是选择;
以及与On-policyDistillation、RL结合的动态数据调度。
当推理模型的瓶颈逐渐从「规模」转向「数据的高效利用」,理解哪些思维过程真正具有教学价值,可能将成为下一阶段post-training的关键问题。
作者介绍
杨宇铭,复旦大学自然语言处理实验室博士生,导师为张奇教授。本科毕业于复旦大学数学系,硕士毕业于密歇根大学统计学系。博士阶段前曾在微软担任数据科学家。研究方向为自然语言处理与大语言模型,作为第一作者或共同第一作者在ACL、EMNLP、NeurIPS等顶级会议发表多篇论文。