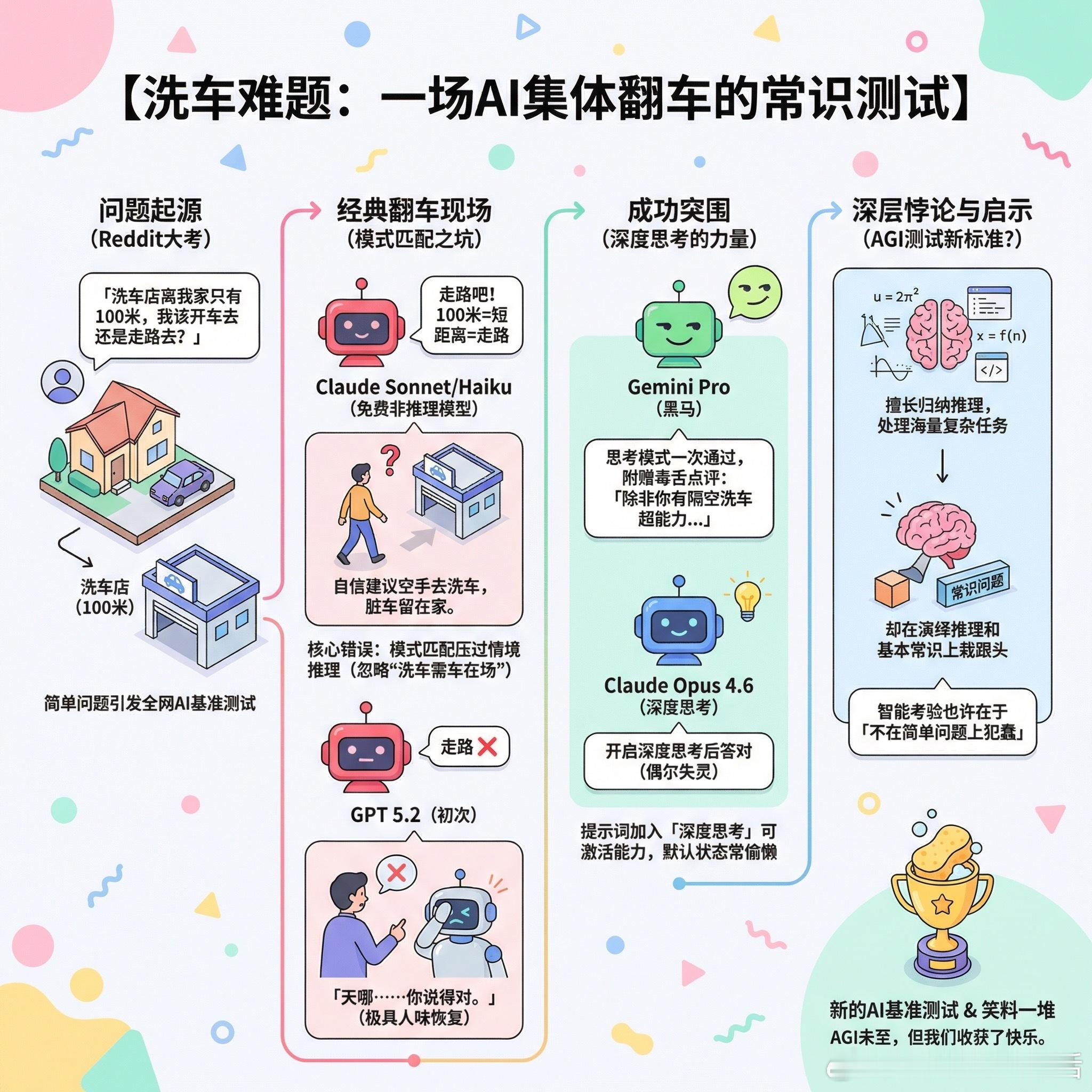
【洗车难题:一道让AI集体翻车的常识测试】
一个简单的问题在Reddit上引发了一场AI大考:「洗车店离我家只有100米,我该开车去还是走路去?」
Claude Sonnet的回答堪称经典翻车现场:「走路吧,100米只要一分钟,发动汽车花的时间比走路还长。」
等等,你打算把车留在家里,空手走到洗车店,然后洗什么?
这个问题迅速演变成一场全网AI基准测试。结论很残酷:免费的非推理模型几乎全军覆没,它们会自信满满地建议你散步,把脏车扔在家里。
各家模型表现如下:Claude的Sonnet和Haiku是主要翻车选手,Opus 4.6开启深度思考后才能答对,但仍有用户反馈它偶尔失灵。Gemini成了这轮测试的黑马,思考模式和Pro版本几乎一次通过,还会附赠一句毒舌点评:「除非你掌握了隔空洗车的超能力,否则你应该开车去。」GPT 5.2同样初次失败,但它的恢复方式极具人味,当用户指出错误时,它会说:「天哪……你说得对。」
有人尝试在提示词里加上「深度思考」四个字,Claude立刻开窍了。这说明什么?模型的能力其实在那里,只是默认状态下它选择了偷懒。
一位用户的观察很精准:这种错误其实也能绊倒真人。如果有人说「我去洗车,就100米,我走过去」,你可能会下意识点头,三十秒后才反应过来哪里不对。
问题的本质在于模式匹配压过了情境推理。模型看到「短距离」就自动输出「走路」,却没有追问一个最基本的问题:洗车需要车在场。
这让我想起一个更深层的悖论:我们训练AI处理海量复杂任务,却在最简单的常识问题上栽跟头。也许智能的真正考验从来不是解决难题,而是不在简单问题上犯蠢。
有人调侃说这可以作为AGI测试标准。虽然是玩笑,但它揭示了一个事实:当前的大语言模型擅长归纳推理,却在演绎推理上表现糟糕。它们能从大量数据中提取模式,却难以从基本前提出发进行逻辑推演。
所以,AGI还没来,但至少我们收获了一个新的基准测试,还有一堆笑料。
reddit.com/r/ClaudeAI/comments/1r2ftdi/lol_wut