[CL]《Think Fast and Slow: Step-Level Cognitive Depth Adaptation for LLM Agents》R Yang, F Ye, X We, R Zhao... [Tencent Hunyuan & Fudan University] (2026)
当前的LLM智能体正陷入一种认知僵化的困境:要么像膝跳反应一样不假思索,在复杂任务面前显得鲁莽;要么像哲学家一样对每一个琐碎步骤都过度沉思,在常规操作中浪费算力。这种僵化不仅导致了巨大的计算浪费,更限制了智能体在长程动态任务中的表现。真正的智能,不在于思考的绝对深度,而在于认知资源的精准适配。
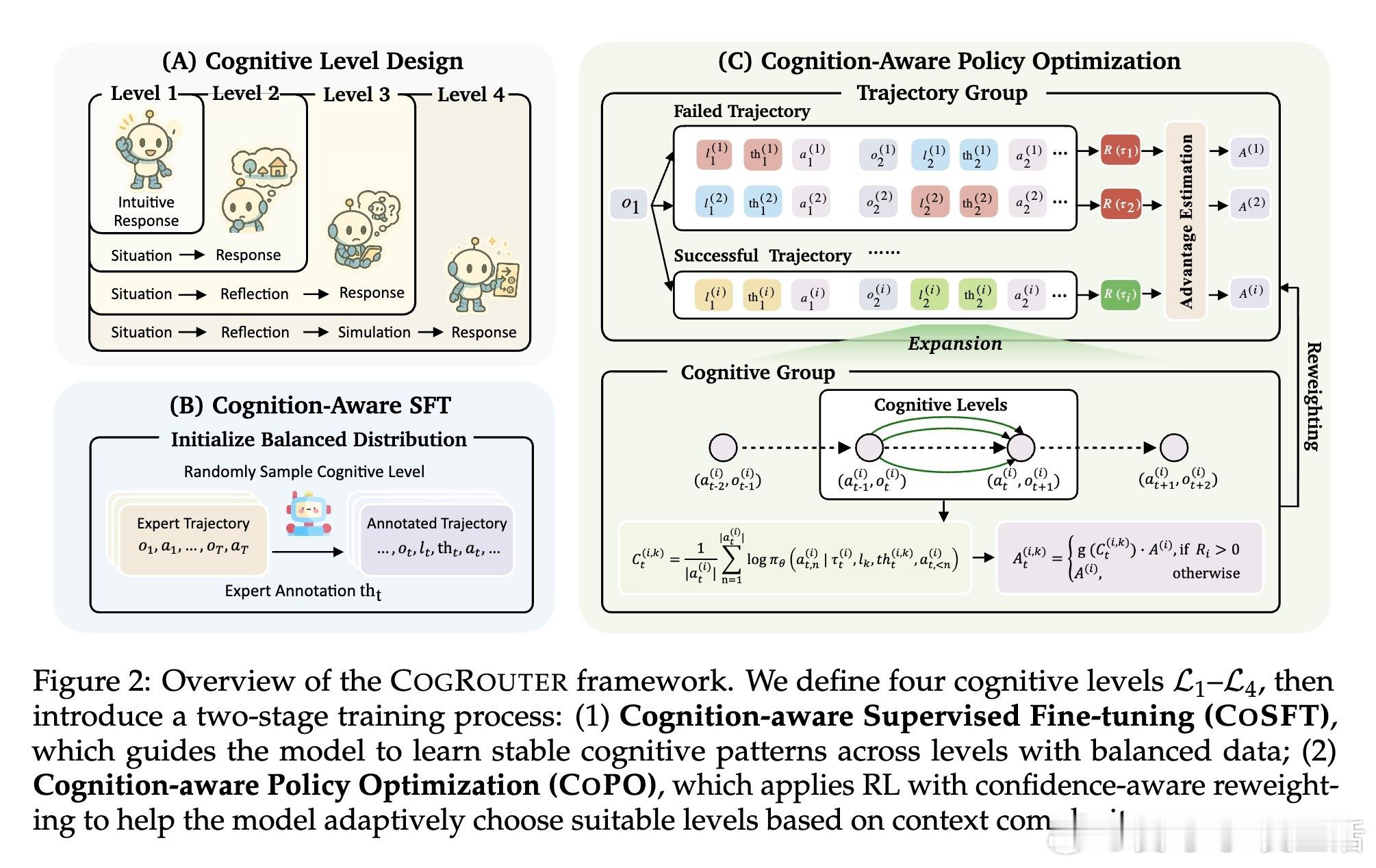
本文提出了CogRouter框架。受人类认知架构理论ACT-R的启发,他们认为智能体不应只有简单的开关,而应拥有一套认知变速箱。研究者将认知深度划分为四个层级:从无需思考的本能反应,到基于情境的感知,再到整合历史经验的反思,最后是模拟未来的战略规划。
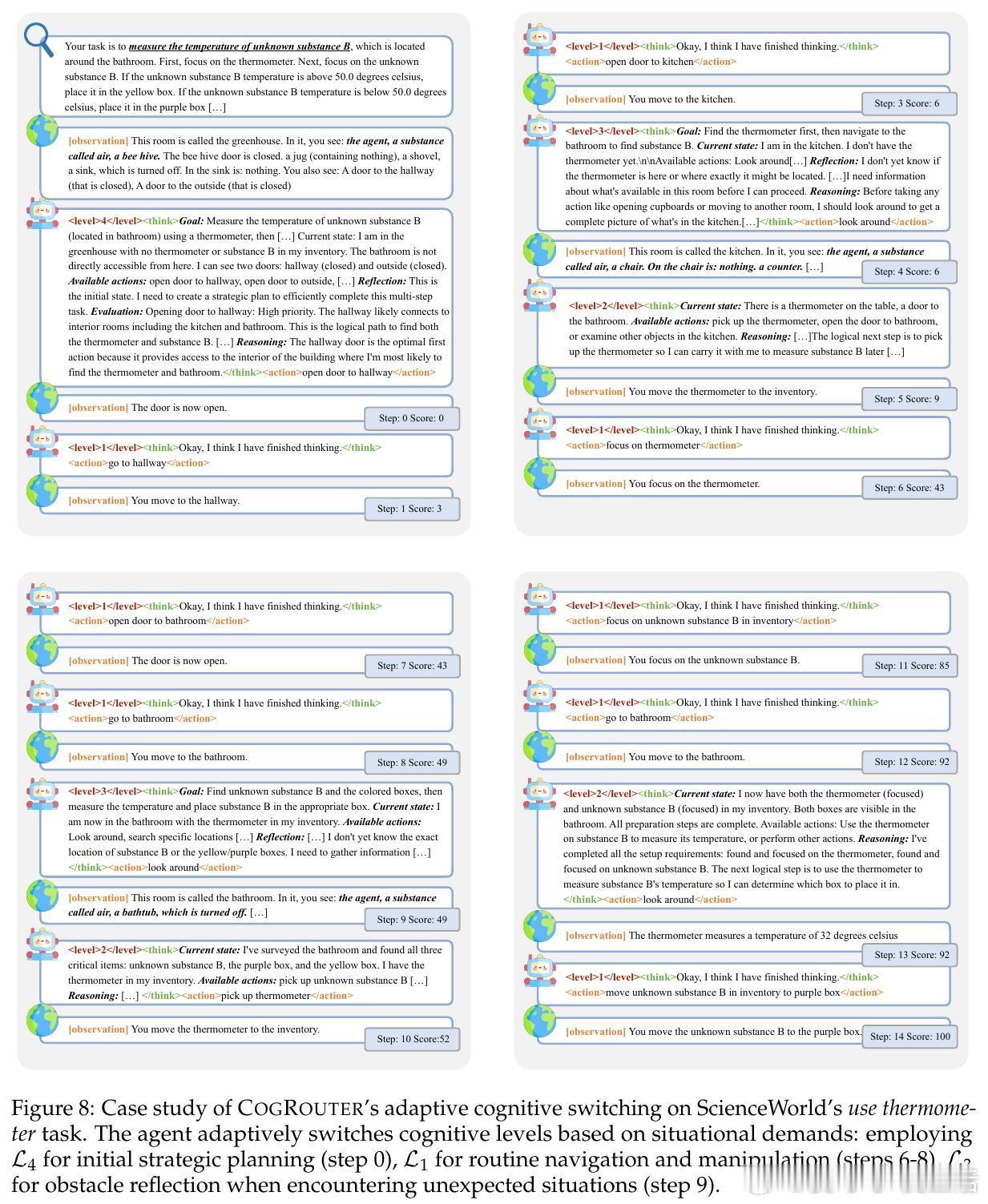
这套认知变速箱的四档设计逻辑清晰:L1层级处理常规动作,优化速度;L2层级在行动前评估状态与可用动作;L3层级引入回顾性推理,将过去的经验转化为当下的决策;L4层级则是最高负荷的预测性模拟,通过评估候选动作的未来影响来寻找最优解。平庸的智能体在机械重复,而卓越的智能体在动态适配。
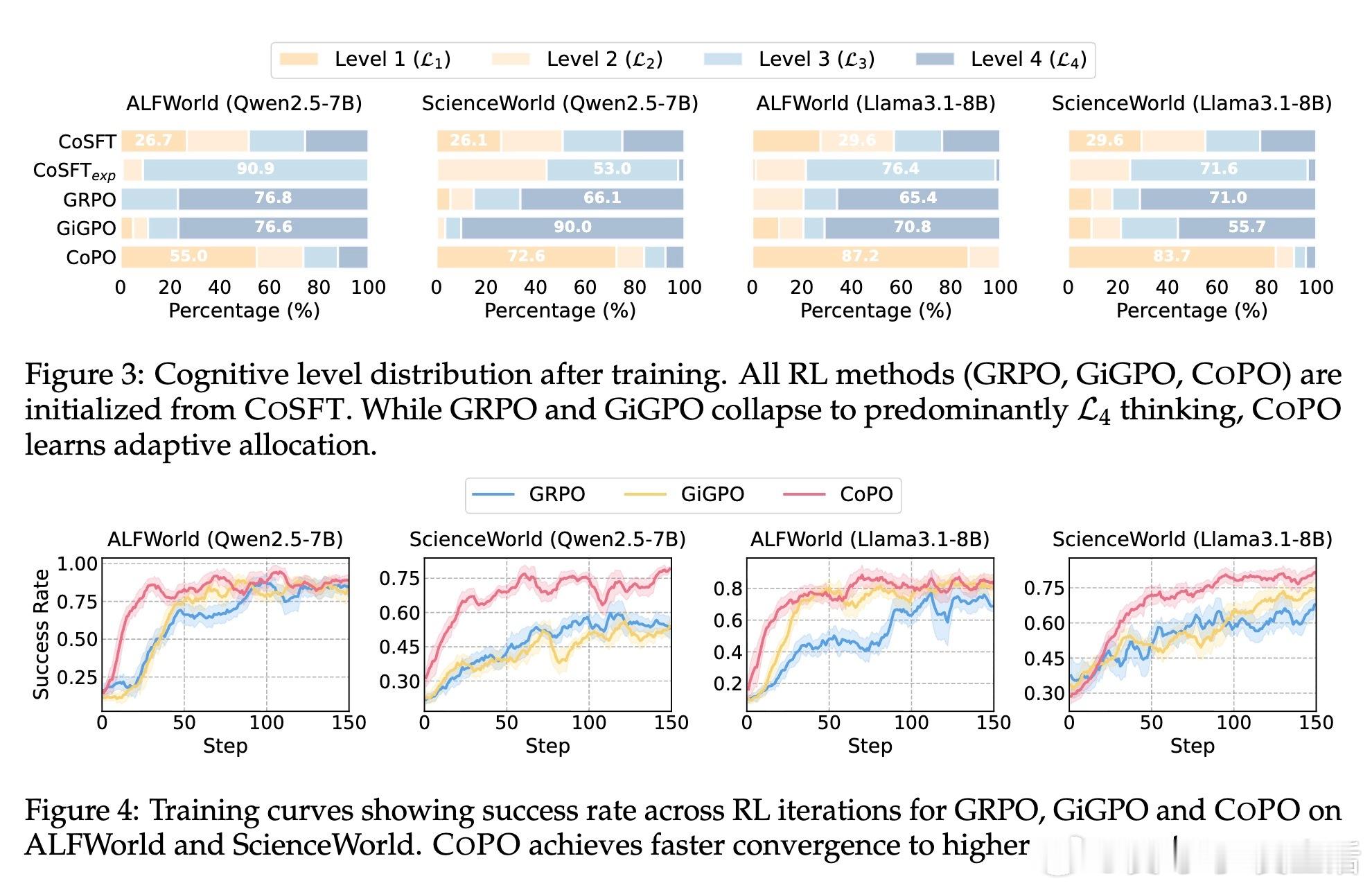
为了训练这种适配能力,CogRouter采用了两阶段方案。首先通过认知感知微调(CoSFT)为智能体植入稳定的认知模式,防止模式坍缩。随后引入核心创新:认知感知策略优化(CoPO)。其核心洞察在于:合适的认知深度应当能够最大化后续动作的置信度。如果深思熟虑后依然无法果断行动,说明认知资源的分配出现了偏差。
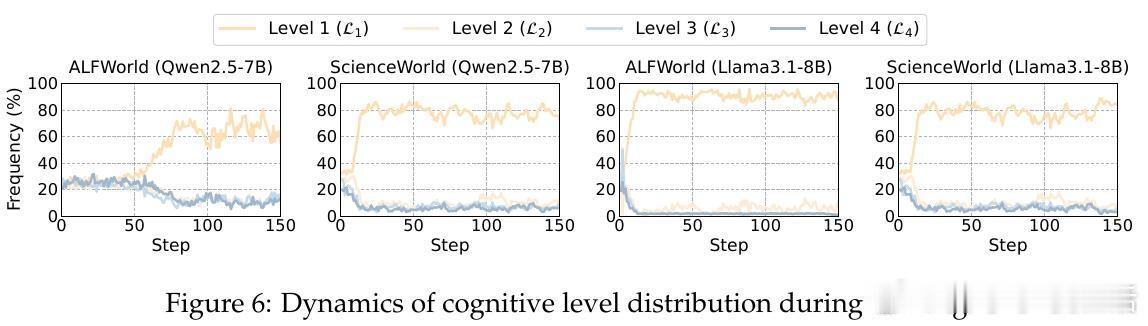
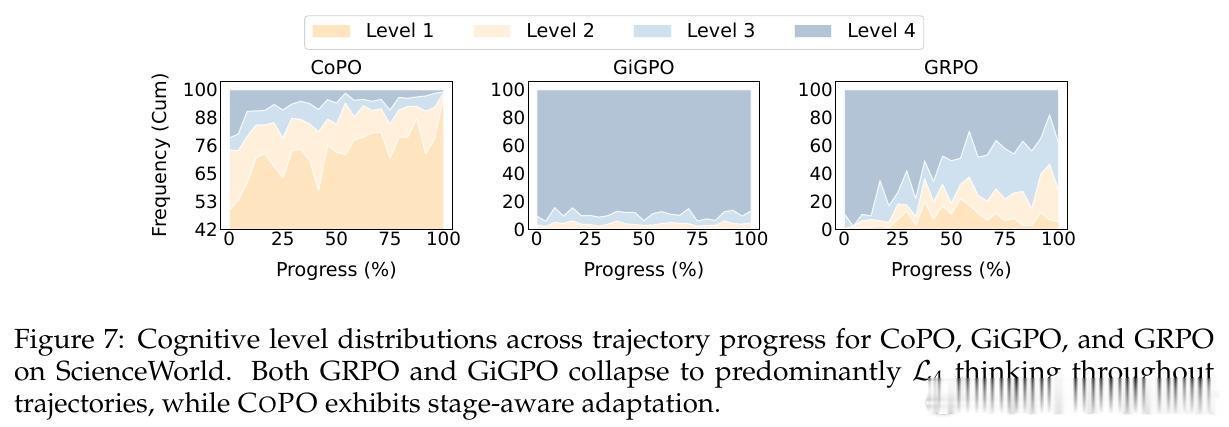
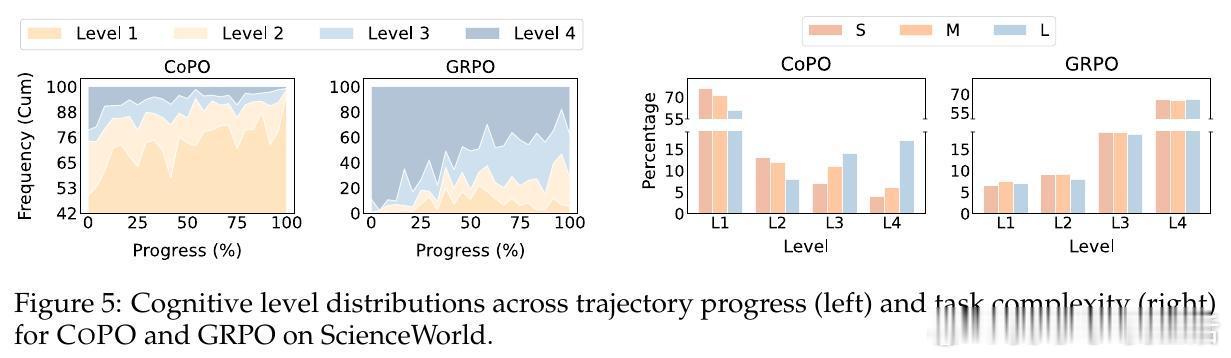
传统的强化学习方法(如GRPO)在处理这类问题时极易出现认知坍缩:模型往往会发现深思熟虑通常伴随更高的总奖励,从而演化成在所有步骤都盲目开启最高档位思考。CoPO通过置信度感知的优势重加权,实现了步骤级的信用分配。它能精准识别哪些步骤需要深挖,哪些步骤应当疾行,从而在提升性能的同时大幅压降成本。
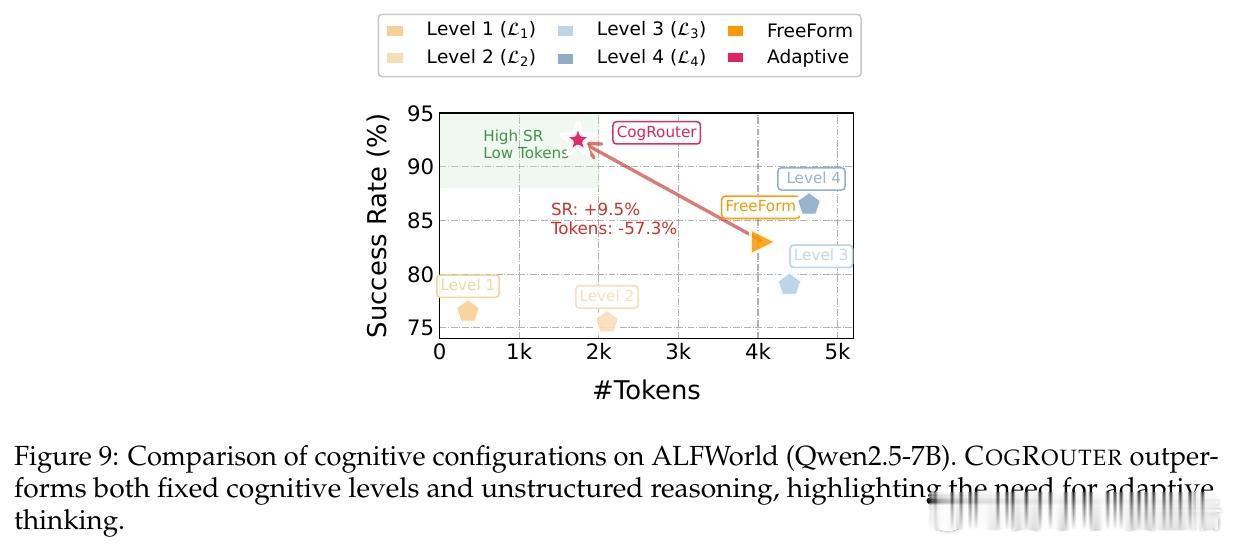
实验数据证明了这种动态深度的威力。在ALFWorld和ScienceWorld等复杂交互测试中,基于Qwen2.5-7B的CogRouter达到了82.3%的平均成功率。这一结果不仅大幅超越了GPT-4o和OpenAI-o3,更在Token消耗上比传统的强化学习方法减少了62%。效率是智能的另一面镜子,CogRouter证明了更聪明的大脑往往更懂得节约。
CogRouter的意义在于它打破了AI推理全量开启的迷思。它向我们展示了未来高效智能体的图景:它们不再是只会堆砌推理长度的算力黑洞,而是具备认知自觉的行动者。在混沌与未知的关口深思熟虑,在明朗与常规的路径上大步流星。这种对认知深度的掌控力,正是通往通用人工智能的关键一步。
论文详情:arxiv.org/abs/2602.12662