[LG]《SLA2: Sparse-Linear Attention with Learnable Routing and QAT》J Zhang, H Wang, K Jiang, K Zheng... [Tsinghua University] (2026)
视频生成领域迎来了一次效率与质量的深度博弈。本文发布了 SLA2,通过可学习路由与量化感知训练,在保持甚至提升视频质量的前提下,实现了 18.6 倍的注意力机制提速。这不仅是工程上的优化,更是对注意力机制底层逻辑的一次重新发现。
视频生成的长序列计算一直是算力的黑洞。传统的稀疏注意力虽然能减负,但往往依赖硬性的启发式规则,这就像是给精密的机器套上了粗糙的模板。SLA2 的出现,旨在解决前作 SLA 在数学表达上的不匹配以及路由策略的低效。
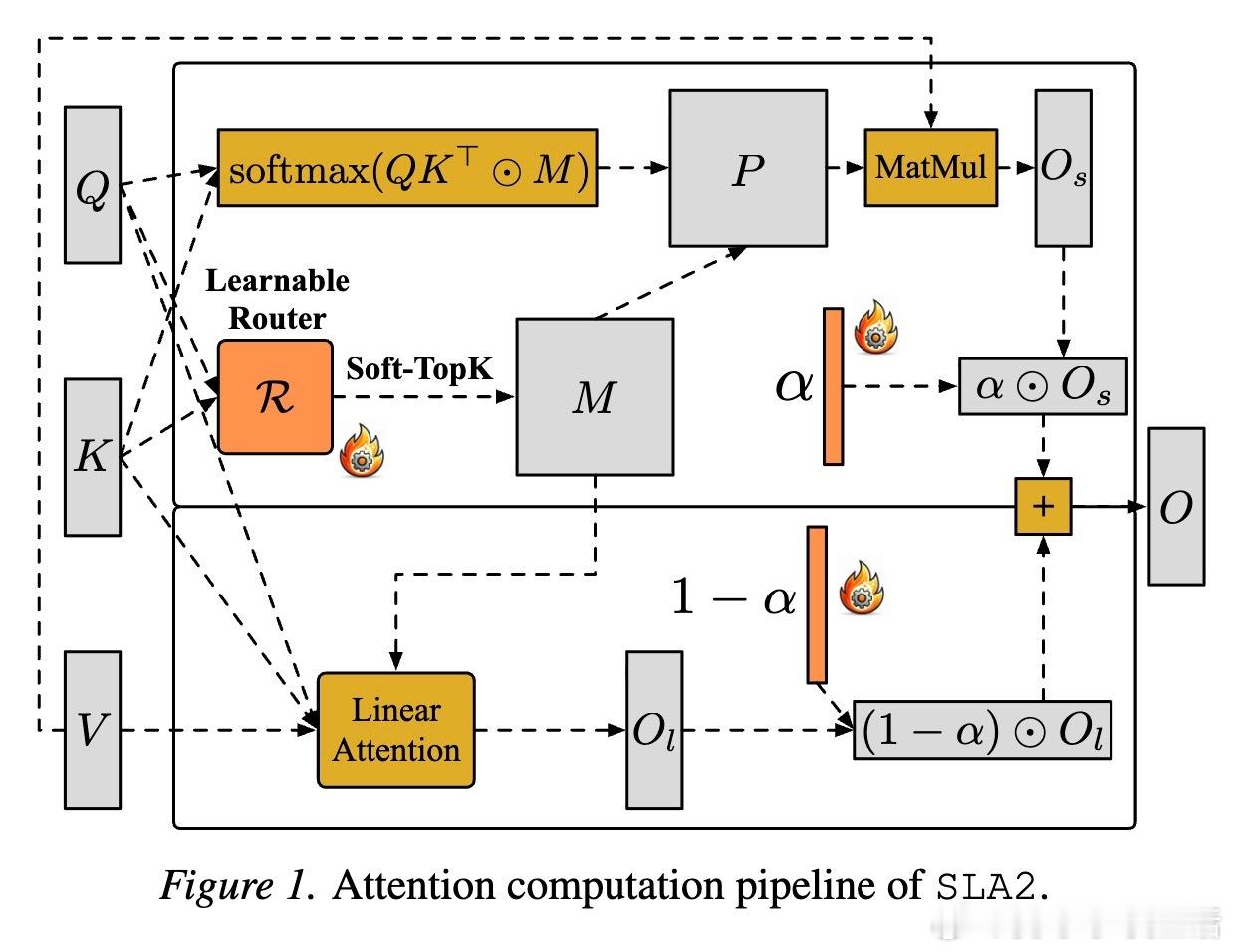
第一个核心思考:计算的分配不应是死板的规则,而应是动态的艺术。SLA2 引入了可学习路由器。它不再简单地根据权重大小进行筛选,而是通过轻量级的投影与池化,动态预测每一项计算应该走稀疏分支还是线性分支。这种任务自适应的表示学习,让模型学会了在复杂场景中精准分配算力。
第二个核心思考:数学上的严谨性决定了模型能力的上限。研究团队发现,之前的稀疏-线性结合方式在数学上存在缩放失真。SLA2 提出了一种更忠实于原始分解的公式,通过引入可学习的比例系数,完美融合了稀疏分支的精确性与线性分支的全局观。这确保了输出结果的行归一化,避免了长序列生成中的数值漂移。
第三个核心思考:低比特计算不应以牺牲画质为代价。为了追求极致速度,SLA2 将量化感知训练(QAT)引入注意力机制。在训练阶段就让模型适应低比特的量化误差,使得推理时即便使用 INT8 或 FP8 精度,依然能保持纹理的细腻。这种训练与推理的一致性,是实现 97% 极高稀疏度的关键。
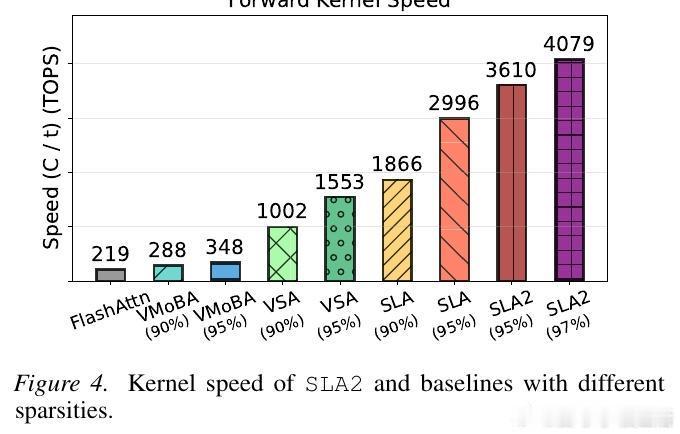
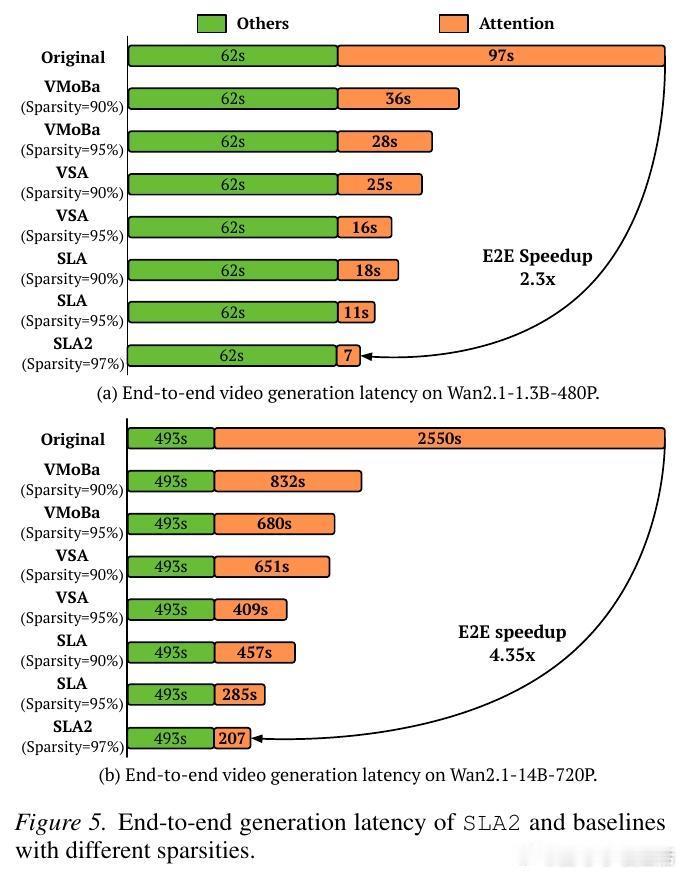
实验数据极具说服力:在 Wan2.1 这一顶尖视频模型上,SLA2 在节省 96.7% 计算量的同时,生成质量竟然超越了全量注意力模型。这揭示了一个深刻的洞见:注意力机制中存在大量冗余,而学会如何优雅地修剪这些冗余,往往能释放出模型更深层的潜力。
智能的本质不仅在于连接,更在于有选择地忽略。SLA2 证明了,当算法能够自主决定哪里需要精雕细琢、哪里可以大笔挥就时,效率与美感可以达成完美的统一。
更多技术细节请参考:arxiv.org/abs/2602.12675