[LG]《HyperMLP: An Integrated Perspective for Sequence Modeling》J Lu, S Yang [Georgia Institute of Technology] (2026)
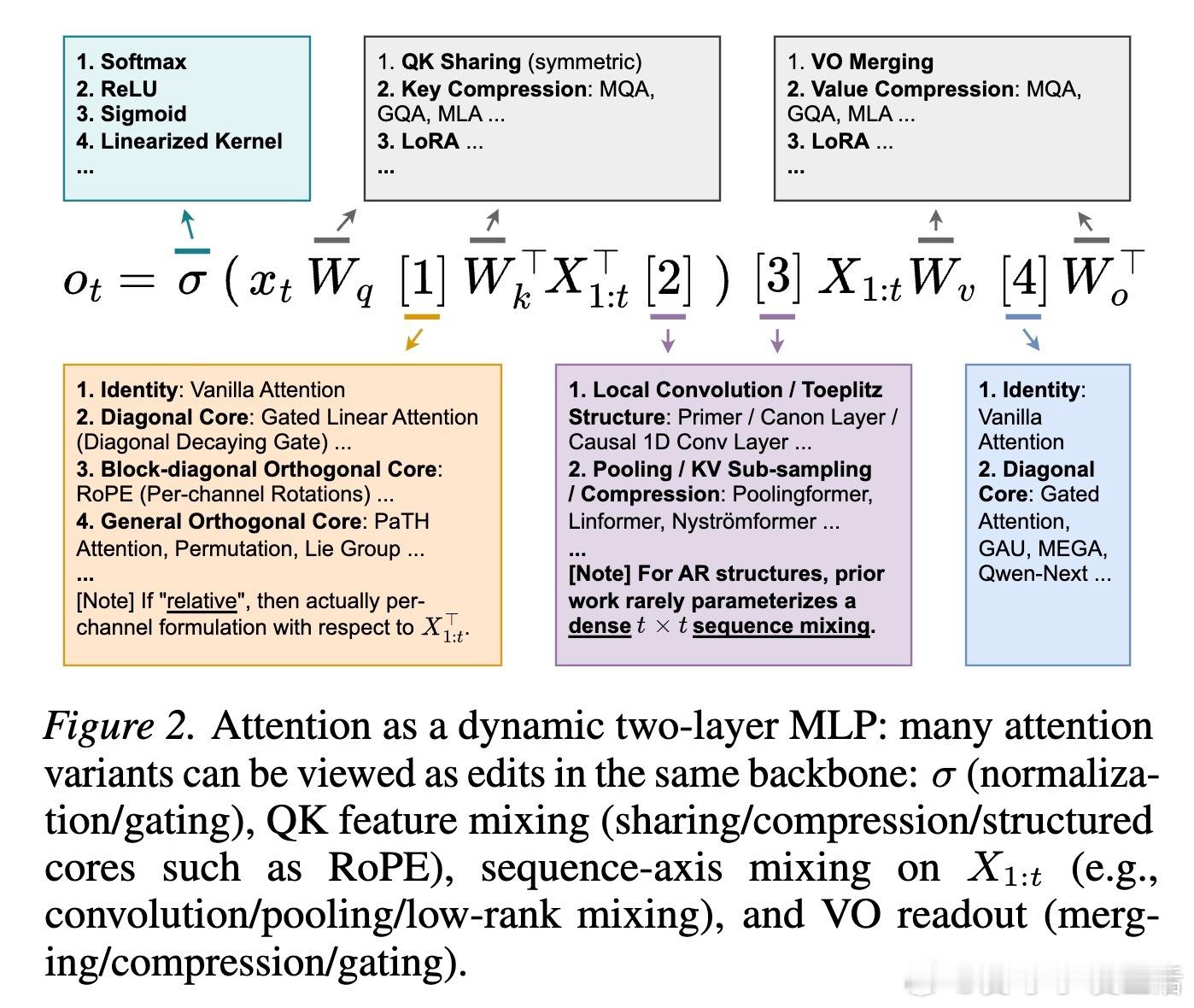
重新想象注意力机制。长期以来,我们习惯于将Self-Attention视为一种概率性的查询查找(Query-Key Lookup),这种视角虽然直观,却可能限制了我们对模型表达能力的探索。HyperMLP提出了一套更具统一性的视角:自回归注意力头本质上是一个动态的二层MLP。在这个框架下,注意力分数不再仅仅是概率,而是随上下文增长的隐藏层表示。
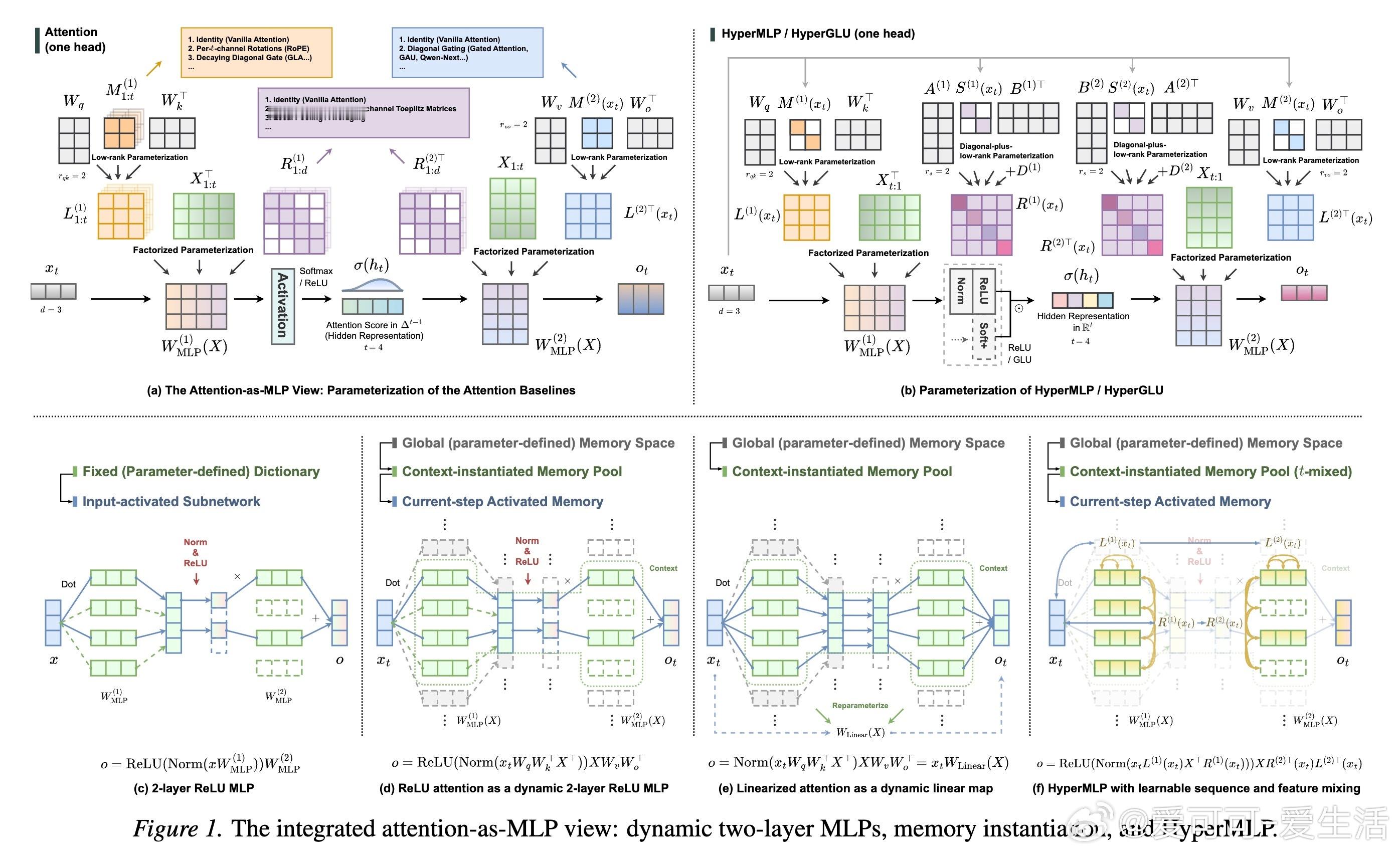
从第一性原理出发,注意力头可以被拆解为动态实例化的权重矩阵。这意味着模型在处理每一个Token时,都在根据当前上下文实时构建一个微型神经网络。ReLU或GLU等激活函数在其中的作用,是实现一种基于输入条件的子网络选择,而非简单的概率归一化。这种视角的转变,让我们能够直接借用MLP领域的成熟经验来优化序列建模。
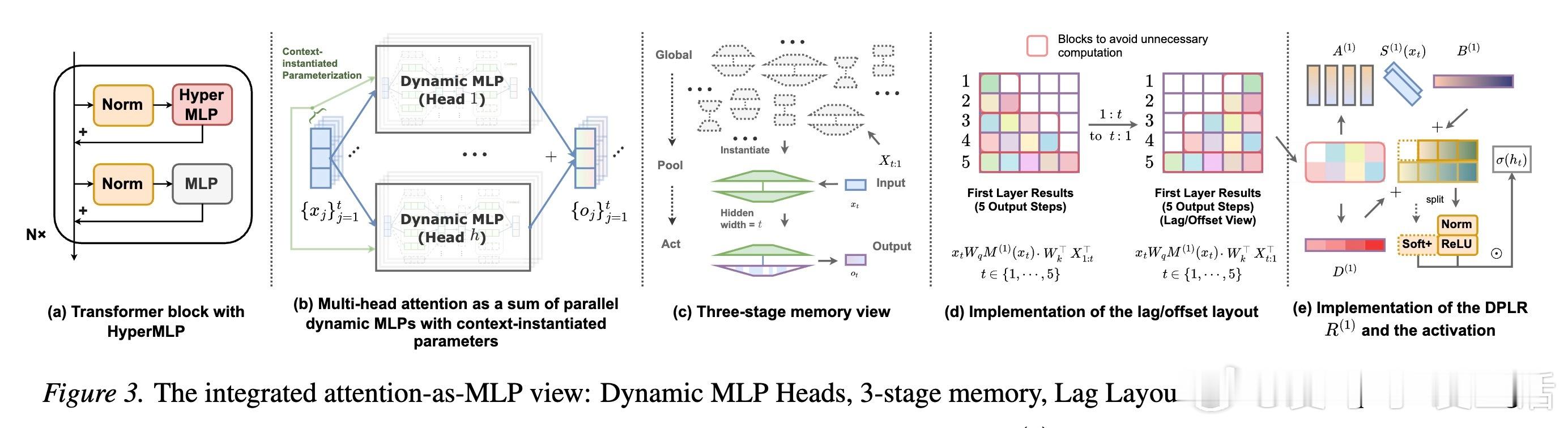
打破固定位置基底的束缚。传统注意力的一个核心局限在于其隐藏空间是基于固定位置的。HyperMLP引入了可学习的序列混合(Sequence Mixing),让模型能够学习如何跨时间维度有效地提取特征。通过在特征空间和序列空间同时进行动态混合,模型不再被动地等待位置编码的指引,而是主动构建适应任务的上下文槽位。
逆向偏移布局的巧妙应用。在自回归生成中,保持时间一致性是巨大的挑战。HyperMLP采用了逆向偏移(Lag)布局,将时间混合与自回归语义对齐。这种设计确保了模型在处理不断增长的历史信息时,其序列操作符的扩展与截断语义保持一致。这不仅是数学上的优雅,更是确保长文本推理稳定的关键。
HyperGLU:解耦路由与强度。研究进一步提出了HyperGLU结构,其核心价值在于将路由选择(哪些信息重要)与槽位强度(重要程度如何)进行了解耦。这种机制让模型在复杂的上下文检索任务中表现得更加游刃有余。当选择与权重不再混为一谈,模型对信息的过滤和放大就有了更高的精度。
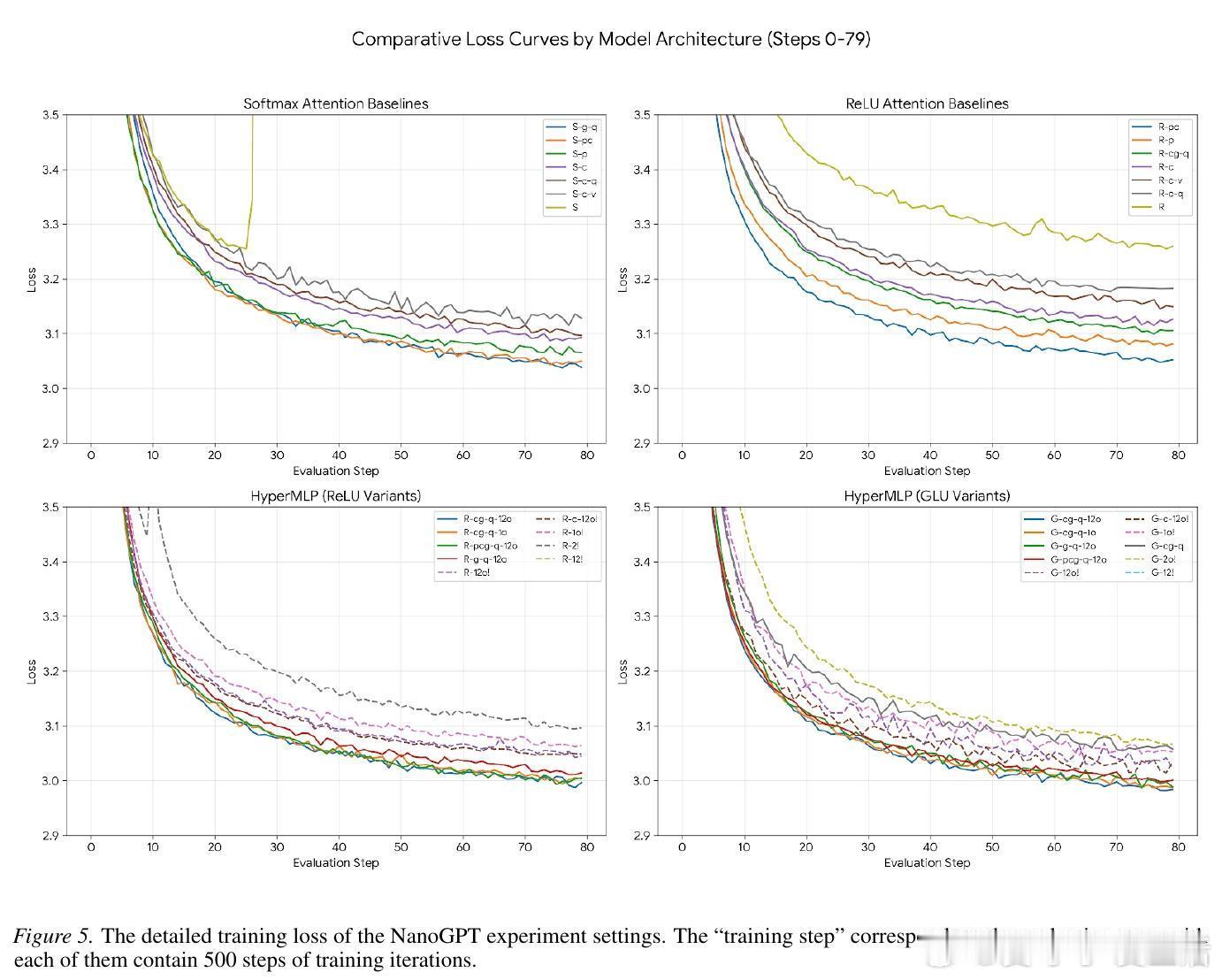
参数预算的非对称艺术。在有限的参数预算下,如何分配资源?HyperMLP给出了一个深刻的见解:与其在QK(路由侧)投入过多,不如缩小QK层以换取序列混合能力,同时全力保护VO(动作侧)的秩。保护VO就是保护模型的更新空间,而优化QK则是优化模型的思考路径。这种非对称的预算分配,在实验中证明了其卓越的性价比。
回归本质的进化。HyperMLP的成功再次印证了那个著名的苦涩教训:通用的、数据驱动的方法最终会战胜手工设计的特征工程。当我们将注意力机制从概率的牢笼中释放出来,转而拥抱动态MLP的灵活性时,模型展现出了更强的噪声抑制、模糊检索和选择性复制能力。这不仅是架构的微调,更是对序列建模本质的一次深刻回归。
论文链接:arxiv.org/abs/2602.12601