2026年2月21日,一家名为Taalas的芯片初创公司正式揭开面纱,发布了它的第一款产品:一颗将Meta的Llama3.18B大语言模型几乎完整“刻进”硅片的推理芯片HC1。按照该公司公布的数据,这颗芯片在单用户场景下可以跑到17,000tokens/s的输出速度,大约是目前市面上最快竞品Cerebras的近9倍,是NvidiaBlackwell架构GPU的近50倍。构建成本据称只有同等GPU方案的二十分之一,功耗低一个数量级。

不过这颗芯片的局限也非常明显,那就是它只能跑Llama3.18B。要想换个模型?就只能再造一颗芯片。
这是AI芯片行业迄今为止最激进的专用化尝试,没有之一。
当前主流的推理部署依赖GPU,尤其是Nvidia的H100/H200和最新的Blackwell系列。GPU的优势在于通用性和成熟的软件生态,但它的架构天然存在一个瓶颈:计算单元和存储单元是分离的。模型的参数存储在HBM(HighBandwidthMemory,高带宽内存)中,计算核心每次运算都需要从HBM搬运数据,这个搬运过程消耗大量能量和时间。
为了缓解这个问题,整个行业在先进封装、3D堆叠、液冷散热、高速互联等方向上投入了巨大的工程资源。Nvidia的GB200NVL72机柜级系统就是这种路线的极致体现:72颗GPU通过NVLink互联,单机柜功耗接近120kW,需要液冷支持,造价以百万美元计。
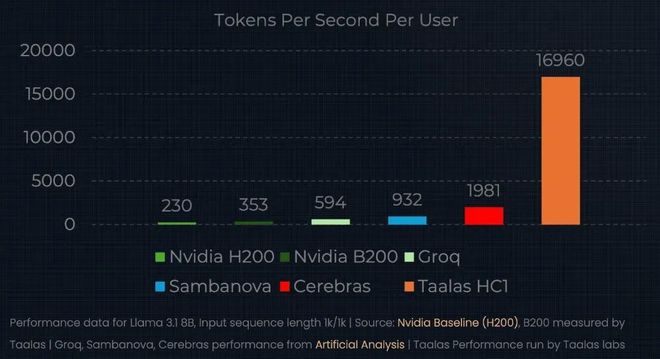
Taalas的做法是把这套复杂性连根拔掉。
他们的核心思路可以概括为三个词:全面专用化、存算合一、极度简化。HC1芯片采用MaskROM(掩模只读存储器)工艺将模型权重直接编码在芯片的金属互连层中,和计算逻辑共存于同一块硅片上,不再需要外部DRAM或HBM。芯片上保留了一小块SRAM(StaticRandom-AccessMemory,静态随机存取存储器),用于存放KVCache(键值缓存,Transformer推理时缓存历史注意力信息的数据结构)和LoRA(Low-RankAdaptation,低秩适配)微调权重,提供有限的灵活性,但整体架构的可编程性几乎为零。
据报道,HC1基于台积电N6工艺制造,芯片面积815mm²,接近光罩极限(reticlelimit),单颗芯片即可容纳完整的8B参数模型。功耗约250W,10块HC1板卡装进一台服务器总功耗约2.5kW,可以在标准风冷机架中运行。这和动辄数十千瓦、必须上液冷的GPU服务器差别很大。
Taalas的CEOLjubisaBajic是Tenstorrent的联合创始人,曾担任该公司的CEO和CTO。Tenstorrent是AI芯片领域另一家知名初创企业,走的是基于RISC-V架构的可编程AI加速器路线,后来由芯片行业传奇人物JimKeller接任CEO并继续发展。Bajic离开Tenstorrent后大约在2023年中创立了Taalas,走了一条和Tenstorrent几乎完全相反的路:不追求通用性,而是把专用化推到极端。目前,Taalas团队规模约25人,累计融资超过2亿美元,但据Bajic本人披露,第一款产品实际只花费了约3000万美元。

Taalas的芯片定制流程借鉴了2000年代早期结构化ASIC(Application-SpecificIntegratedCircuit,专用集成电路)的思路。结构化ASIC通过固化门阵列和硬化IP模块,只修改互连层来适配不同工作负载,在成本和性能上介于FPGA(Field-ProgrammableGateArray,现场可编程门阵列)和全定制ASIC之间。
Taalas的做法类似但更进一步:每次为新模型定制芯片时只需更换两层掩模,这两层掩模同时决定模型权重的编码和数据在芯片内部的流动路径。Bajic表示,从拿到一个新模型到生成RTL(RegisterTransferLevel,寄存器传输级描述)大约只需要一周的工程工作量,整个从模型到芯片的周期目标是两个月。
这个两个月的周转速度如果能稳定实现,意味着什么?意味着当一个模型在生产环境中被验证有效、用户粘性足够高、预计至少运行一年时,Taalas可以在较短时间内为它制造专用硅片,以远低于GPU的成本和功耗来提供推理服务。Bajic承认,这种模式要求客户对某个特定模型做出至少一年的承诺,“肯定有很多人不愿意,但会有人愿意”。
那么,这种极端专用化能扩展到更大的模型吗?Taalas给出了他们对DeepSeekR1671B的模拟数据。671B参数的模型需要大约30颗芯片协同工作,每颗芯片承载约20B参数(采用MXFP4格式,并将SRAM分离到独立芯片以提高密度)。30颗芯片意味着30次增量流片,但Bajic指出由于每次只改两层掩模,增量流片成本并不高。
模拟结果显示,这套30芯片系统在DeepSeekR1上可以达到约12,000tokens/s/user,而当前GPU最优水平大约在200tokens/s/user。推理成本约7.6美分/百万token,不到GPU吞吐优化方案的一半。
这些数字当然还停留在模拟阶段。实际多芯片系统面临的互联、同步、良率等工程挑战不可小觑,30颗大面积芯片协同工作的验证复杂度也是指数级增长的。Bajic自己也提到,因为芯片完全不可编程,“出错的余地基本为零”,唯一能建立信心的方法就是在流片前对整个模型进行完整的仿真——如何在合理时间内完成30颗芯片的联合仿真,本身就是一个巨大的工程问题。Taalas声称已经建立了可以在大规模计算集群上运行的仿真流程来应对。
还有一个值得关注的细节是,HC1使用了自定义的3-bit基础数据类型进行激进量化,结合3-bit和6-bit参数,会带来相对于标准量化模型的质量损失。Taalas对此并未回避,承认模型在质量基准测试中会有退化。他们的第二代硅平台HC2将采用标准4-bit浮点格式以改善这一问题。第二款产品预计是一个中等规模的推理模型,计划今年春季在实验室完成,随后接入推理服务。基于HC2平台的前沿大模型则计划冬季部署。
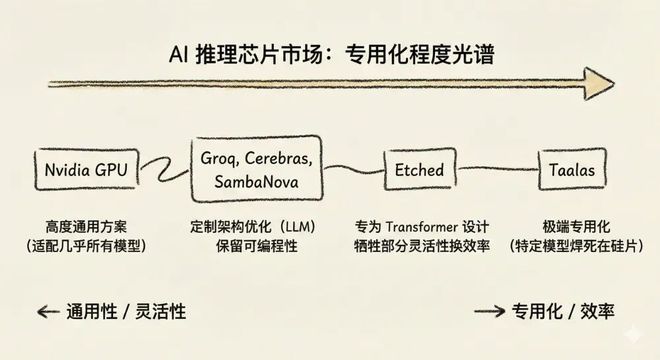
当前AI推理芯片市场大致可以按专用化程度排列成一个光谱:一端是NvidiaGPU这样的高度通用方案;中间是Groq、Cerebras、SambaNova等,它们设计了针对LLM推理优化的定制架构,但仍保留可编程性,能运行多种模型;Etched更往前走一步,专门针对Transformer架构设计芯片,牺牲部分灵活性换效率;而Taalas直接站在了最末端,把一个特定模型焊死在硅片里。
这种极端策略的风险很明显。AI领域模型迭代速度极快,去年的前沿模型今年可能就被淘汰。如果一颗芯片只能跑一个模型,而那个模型在芯片寿命结束前就过时了,投资就打了水漂。这也是Bajic所说的“为什么之前没人敢走到这个角落”。但他认为随着行业成熟,总有一些模型在实际业务中被长期使用。Taalas产品副总裁PareshKharya(此前曾在Nvidia长期任职)也对EETimes表示,对于在重要业务场景中运行的模型,用户粘性可能持续一年甚至更久。
商业模式上Taalas还在摸索。Kharya透露了几种可能方向:自建基础设施运行开源模型并提供API推理服务;直接向客户出售芯片;或者与模型开发者合作,为他们的模型定制专用芯片供其自有推理基础设施使用。哪种模式最终能跑通,取决于市场对这种极端专用化方案的接受程度。
不过从纯技术角度来说,Taalas的方案确实触及了一个被主流路线忽略的设计空间。存算分离带来的带宽墙(memorywall)是当前推理硬件的核心瓶颈,而Taalas通过将权重以MaskROM形式与计算逻辑同层集成,从根本上消除了这个瓶颈。代价是灵活性的彻底丧失,但如果应用场景允许这种刚性,换来的性能和成本优势是实打实的。
Bajic还透露,Taalas能用单个晶体管同时存储4-bit模型参数并完成乘法运算。他拒绝透露更多,但确认计算仍然是全数字的。如果属实,这意味着Taalas在电路层面实现了一种极为高效的存内计算(Compute-in-Memory)机制,虽然不同于学术界讨论较多的模拟存内计算方案,但目标一致:让数据就地参与运算,不再搬来搬去。
硬接线芯片还带来了一个意想不到的副产品:软件栈的极度简化。Bajic说“软件作为一个东西基本消失了”,公司只有一个工程师负责软件栈,而且这人还兼顾其他工作。对比当前GPU推理系统中vLLM、TensorRT-LLM、PagedAttention等复杂软件优化层的工程投入,这种简化几乎是降维式的。当然,这种简化是以极端硬件专用化为前提的,不具有一般性。
Bajic在博客中用ENIAC到晶体管的演化做类比,暗示当前以GPU数据中心为核心的AI基础设施可能只是早期的“笨重原型”,未来终将被更高效的方案取代。这个类比有一定道理,但也不宜过度引申。GPU数据中心的“暴力”不仅仅是硬件层面的,它背后是整个CUDA软件生态、成熟的开发工具链和庞大的工程师社区。颠覆硬件容易,颠覆生态难。Taalas的芯片或许在特定场景下拥有压倒性的性能和成本优势,但要成为主流路线的替代方案,需要的远不止一颗跑得快的芯片。
不过,Taalas可能也从未打算成为“替代方案”。Kharya表示:“模型最优硅片不会取代满是GPU的大型数据中心,但它会适合某些应用。”
参考资料:
1.https://taalas.com/the-path-to-ubiquitous-ai/
2.https://www.eetimes.com/taalas-specializes-to-extremes-for-extraordinary-token-speed/