中国模型调用量突然超过美国,OpenRouter数据骗不了人,这到底算不算真赢了?
上周OpenRouter后台跑出来的数据,我截图发给了好几个做AI的朋友,没人信。5.16万亿Token,中国模型一周用的量,比美国多了快一倍。不是某天高峰,是连续三周增速127%,实打实堆出来的数字。
OpenRouter这平台挺特别,它不卖模型,只当个中转接口。谁调用得多,谁就被开发者真金白银选中。没刷量,没自家流量撑腰,全是中小公司、学生、独立开发者手动填API密钥调出来的。
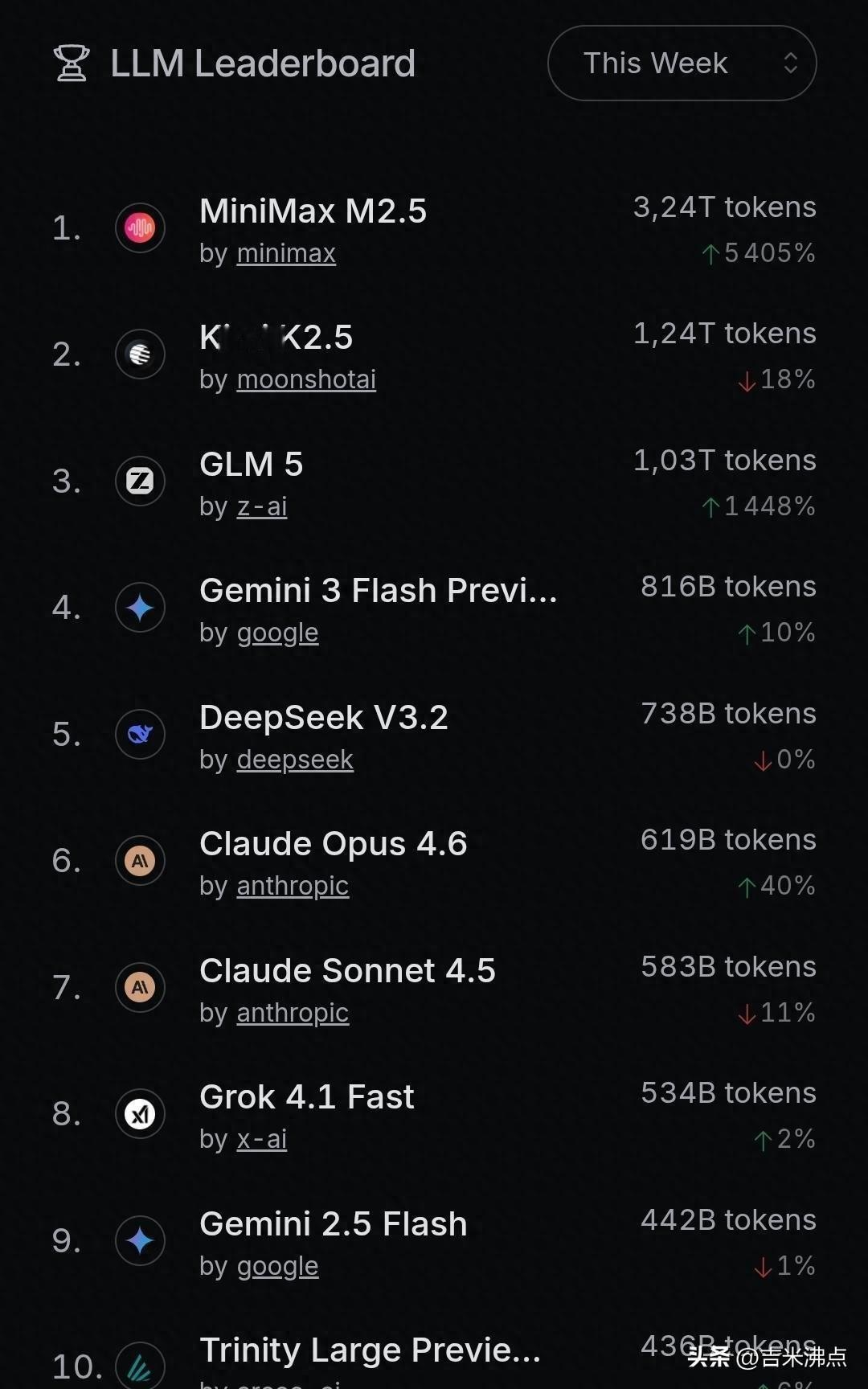
Top5里四个是中国模型:M2.5、K2.5、V3.2、GLM-5。光M2.5一个月就干了4.55万亿Token,比Gemini 3 Flash Preview还高。美国那几个大模型,排进前三的都没了。
有人说是不是春节前赶工吹出来的?其实不是。沙利文报告写得清清楚楚:2025年下半年,中国企业日均用掉37万亿Token,上半年才10.2万亿。不是突然爆发,是实在扛不住了——老模型跑不动新业务,成本压不下来,逼着大家换。
K2.5发布当天就在OpenRouter冲到第一。测试的人说,它读长文档不卡,写Python脚本能直接跑通,连中文表格解析都比以前稳。没那么玄乎,就是“能用、不折腾、文档看得懂”。
中国模型API普遍更简单,参数少,错误提示是中文,账单也支持支付宝和微信。有个做跨境电商的哥们说,他试了三个美国模型,光配token和region就折腾俩小时,换M2.5五分钟搞定。
A股算力股那天全红了,数据中心板块涨停。英伟达股价单日跌了1.77万亿——不是因为中国芯片追上了,是人家真不用你那么多卡了。开发者现在想的是:调谁更快、更便宜、更顺手,不是非得用哪个“名字响”的。
OpenRouter这类平台,把模型从神坛拉回工具箱。以前得求着API配额,现在点几下就能切模型。闭源厂商的渠道优势,正在被这种“一次接入、随时换人”的习惯一点点磨平。
技术叙事也在变。美国开发者不再是默认主角,评论区里中文提问比英文还多。有人问“GLM-5怎么接飞书”,底下直接贴出完整代码。没人再问“这模型是不是国产所以弱”。
Token量不是收入,也不是合同数。有些调用可能只是学生跑个demo,也有些是企业灰度测试。但上万次真实点击的背后,是实打实的选择。
这数据不是偶然,也不靠宣传。就是那一周,大家真的都换用了。