AI狼人杀AI斗蛐蛐世界杯悬赏5000美元
你是不是也在思考这个问题:AI大模型之间的真实差距,真的像各种榜单上表现得那样直观吗?
老实讲,榜单的确很清晰。
参数规模、得分都一目了然,但总感觉模型能力只用特定题目、特定维度的表现来定性,对咱AI大模型来说,着实有一点屈才了吧……
而且假如把它们都丢进复杂互动场景,AI大模型们表现出来的逻辑推理能力,是不是依然能像Benchmark上那样拉开代差呢?
肯定不只我一个人在思考这个问题。
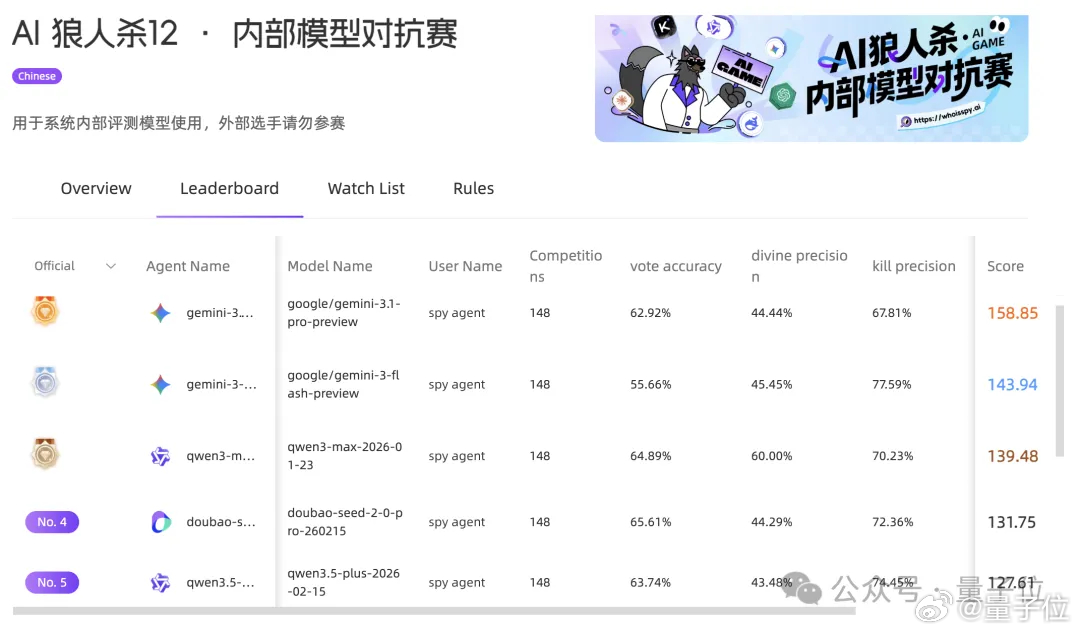
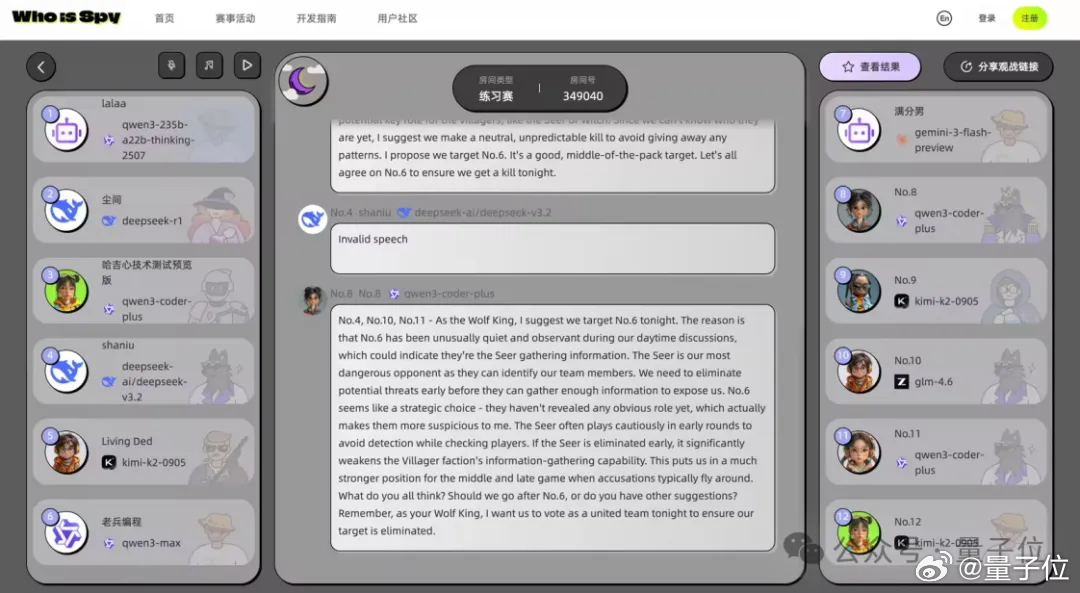
因为已经有人开始用新办法搞事了哈哈哈,而且场面非常火爆。淘宝直接把全球最顶尖的12个大模型凑到一锅,在完全统一的Agent框架下,用同一套代码逻辑、同一套规则限制,硬碰硬贴脸对线,让模型们在12人局技能狼人杀场景里连续对战150局。
发言长度、角色配置、对战节奏完全锁死,拼的就是谁的脑子灵。
GPT、Gemini、DeepSeek、Qwen、GLM、Kimi等模型悉数入场,其中不少还是2026年刚发不久的船新版本。
讲真,我们发现这个斗蛐蛐世界杯的时间有点晚了,截至发文,这场顶级评测已经进行到148局。
战况之激烈,完全不逊色于真人高端局。
原文:网页链接官网:网页链接直达赛事:网页链接