编辑|Sia、Panda
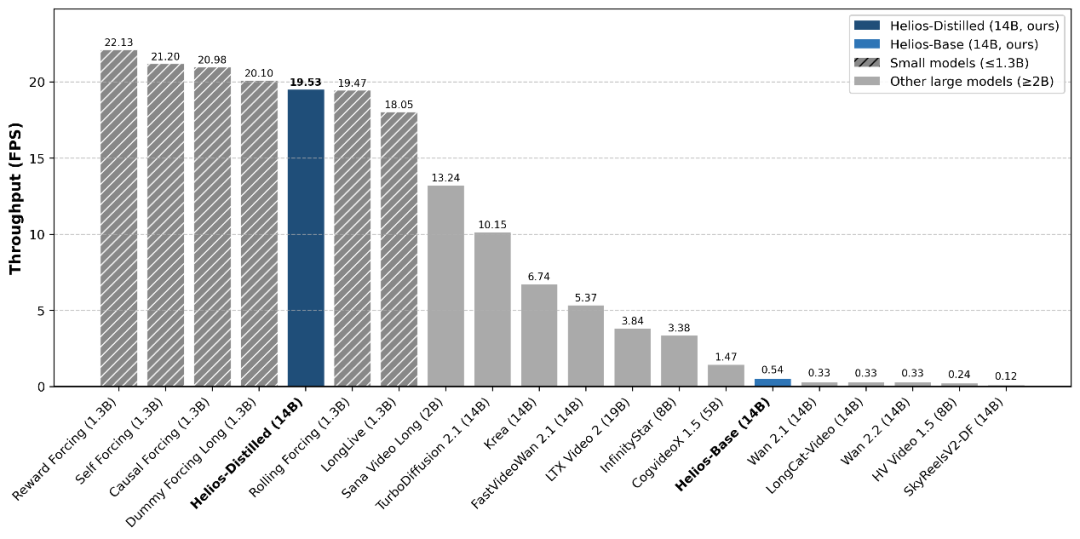
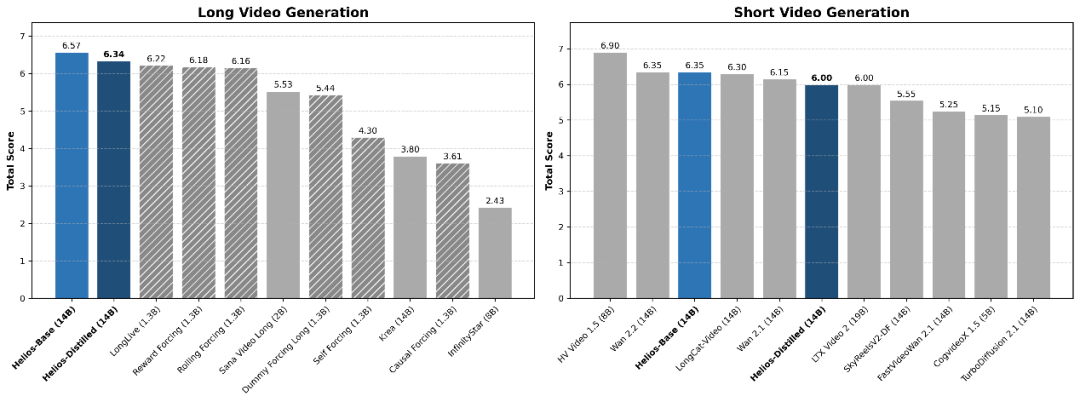
春节期间,Seedance2.0爆火,堪称现象级,这也再次把视频生成推上风口。前两天,字节跳动又携手北大、安努智能和Canva共同开源了具备实时生成能力的视频模型Helios家族。该系列包含了Helios-Base、Helios-Mid与Helios-Distilled三个版本,全面覆盖了T2V、I2V、V2V以及交互式生成任务。其能以14B参数量之躯,实现高达19.5FPS的单卡生成速度,可以说是真正做到了「质量」与「速度」齐飞。
值得一提的是,该项目在发布首日即实现了对昇腾NPU的Day-0级别支持,并同步兼容了Diffusers、vLLM-Omni、SGLang-Diffusion等主流推理框架。
左右滑动查看
如此卓越的表现和强劲的生态支持,也让Helios成功登顶昨天的HuggingFaceDailyPapers。而在GitHub上,这个刚刚发布一两天,还没得到广泛宣传的开源项目的star数已经超过了520!
论文标题:Helios:RealReal-TimeLongVideoGenerationModel
论文地址:https://arxiv.org/abs/2603.04379
项目地址:
https://github.com/PKU-YuanGroup/Helios
https://gitcode.com/weixin_47617277/Helios
就在大家震惊于Helios高质量、高速度的生成能力时,技术社区却在底层架构里寻得了另一番玄机:这个模型的核心开发团队是北京大学袁粒课题组,而该模型也与该团队之前重磅开源的Open-SoraPlan(OSP)项目(兔展智能&北大共同发起)的技术栈高度同源——Helios与OSP团队近期开源的UniWorld-OSP2.0(基于OSP开发)存在三分之一到二分之一的代码复用。
可以说,Helios是对这一核心技术的一次有效验证,性能也比OSP团队此前基于UniWorld-OSP2.0开发的OSP-RealTime14B更胜一筹。
更值得关注的是,支撑OSP系列项目的算力引擎指向了一套庞大的国产化算力生态——鲲鹏与昇腾算力。
事实上,正是得益于北京大学鲲鹏昇腾科教创新卓越中心的赋能和算力支持,这些开源项目才得以成为现实。我们在探讨其令人惊艳的性能时,同样不能忽略昇腾底座为其提供的强大支撑。
从Seedance2.0和Helios的成功可以看出,AI视频生成社区正在凝聚一个愈发清晰的共识——
SOTA视频生成能力正快速向以DiffusionTransformer(DiT)为核心的统一范式收敛。与此同时,模型的比拼也正从基础画质的简单堆料,转向更高层级的语义理解深度与多模态协同效率。
正是在这样的技术拐点与开源生态辐射力下,Open-SoraPlan团队推出的UniWorld-OSP2.0进入越来越多研究者的视野。
这不仅仅是一次简单的版本更迭。作为业界首个开源的超百亿级视频生成大模型(21B),UniWorld-OSP2.0同时也是首个实现「双原生」(昇腾原生&自回归+Diffusion混合架构)统一范式的大模型体系。
UniWorld-OSP2.0开源地址:
https://modelers.cn/models/PKU-YUAN-Group/Uniworld-OSP2.0
https://github.com/PKU-YuanGroup/UniWorld/tree/main/UniWorld-OSP2.0
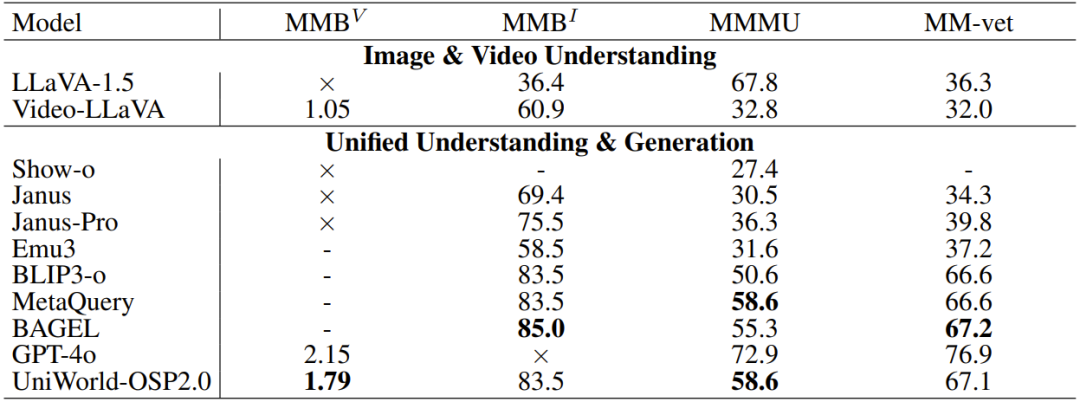
在核心评测指标上,其在VBench-I2V基准上的表现已全面超越Wan2.1,迅速成为开源视频生成生态中最具风向标意义的技术坐标之一。

UniWorld-OSP2.0与其它开源视频模型在VBench-I2V基准上的表现对比
在关键评估指标上的对比中,UniWorld-OSP2.0在运动质量、图像保真度和语义一致性方面均表现出优越性,其整体表现已稳步进入开源阵营第一梯队。
伴随着新版本的发布,社区层面的势能同样如火如荼。
Open-SoraPlan已累计获得约1.2万GitHubstar和千万级下载量,多次登上Trending榜单,并在实际代码活跃度上进入开源视频模型第一梯队。
Open-SoraPlan开源项目已在GitHub收获超1.2万star
同时,这样一个高性能、低成本且自主可控的视频大模型底座,正加速演化为产业侧可复用的视频生成基础设施。
目前已有包括字节、腾讯WXG、阿里达摩院、小红书、哔哩哔哩等多家团队,基于该框架展开二次开发,海外多家AI公司亦同步跟进。
随着团队宣布将进一步开源12类风格化数据集及完整模型权重,视频生成领域或许正迎来属于自己的「视觉版LLaMA时刻」。那么,问题也随之变得更有意思:
这个正在开源视频生成生态中持续演进的技术框架,究竟做对了什么?
下面我们就基于UniWorld-OSP2.0的官方技术报告进行一番解读。

整体架构
三大核心组件的无缝协同
在深入探讨UniWorld-OSP2.0的具体技术突破之前,有必要先从宏观视角拆解其整体架构。这有助于我们理解该模型是如何支撑起「双原生」统一范式并实现高质量生成的。
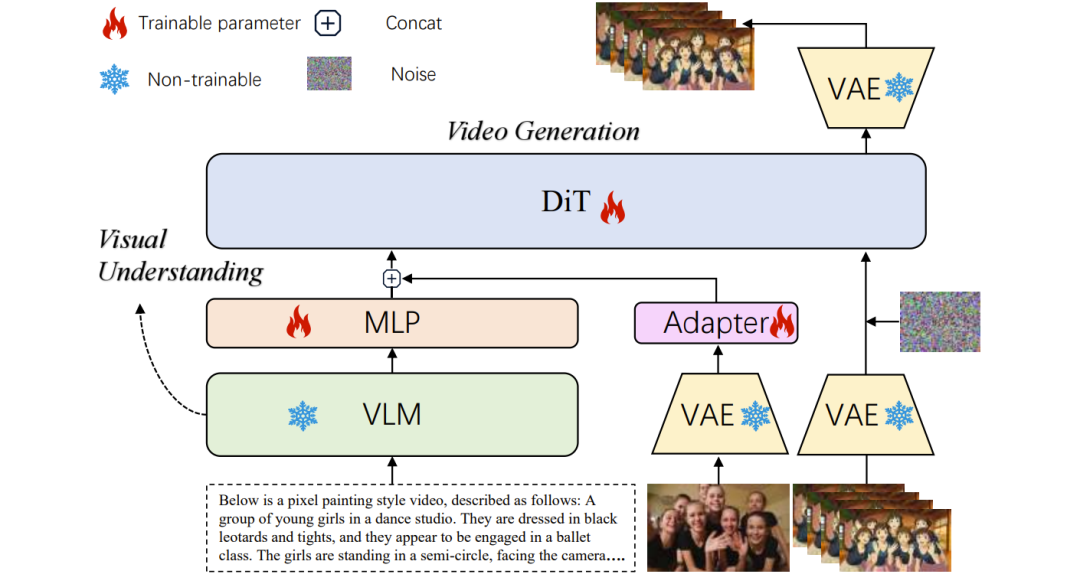
UniWorld-OSP2.0架构概览
根据技术报告,UniWorld-OSP2.0的系统框架在底层逻辑上主要由三个核心组件构成:
因果变分自编码器(CausalVAE):作为视频像素空间与潜在空间之间的桥梁,它负责将高维的视频序列压缩为紧凑的、具有因果结构的潜在表示,确保在保持时间因果关系的同时提升处理效率。
VLM增强的多模态条件模块:这是该架构的认知中枢。它利用一个冻结状态下的VLM(视觉-语言模型)来提取多模态特征,随后通过一个可训练的Adapter模块将这些特征进行适配与映射,从而为后续的生成过程提供深度的语义指导。
扩散Transformer(DiT)主干网络:作为视频生成的核心引擎,DiT接收上述经过Adapter处理的语义特征,并在VAE提供的潜在空间中执行条件去噪,最终合成在时间上高度连贯的视频流。
这套「VAE+VLM+DiT」架构构成了UniWorld-OSP2.0强大性能的基石,同时也为模型深度适配昇腾算力、实现真正的「昇腾原生」打下了系统级的结构基础。建立在这个全局架构认知之上,我们再来细看研究团队是如何在具体的生成与理解环节中精准落刀,解决行业痛点的。
一大核心技术优势
FlashI2V,物理一致性的定海神针
UniWorld-OSP2.0的第一刀,精准落在了视频的物理一致性上。
长期以来,I2V(图像生成视频)生成的视频常常让人觉得不太对劲,动作僵硬或画面崩坏时有发生。其核心症结在于条件图像泄漏(ConditionalImageLeakage)。

条件图像泄漏。(a)如Wan2.1-I2V-14B-480P在VBench-I2V上的结果所示,条件信号的泄漏会导致生成质量下降。(b)分块式FVD在领域内数据上增长,但在领域外输入上保持高位,表明传统I2V模型的泛化能力较差。
在现有的I2V范式(例如SVD或早期的各类模型)中,常规做法是将完整的条件图像数据直接拼接到去噪器中。去噪器往往会把这种直接拼接当作一条「捷径」,对其产生过度依赖。这种过度控制带来的后果,就是生成的视频经常出现动作幅度极小或者色调不协调等性能退化问题。为了解决这一行业难题,研究团队提出了FlashI2V核心机制,通过隐式引入条件来破局。
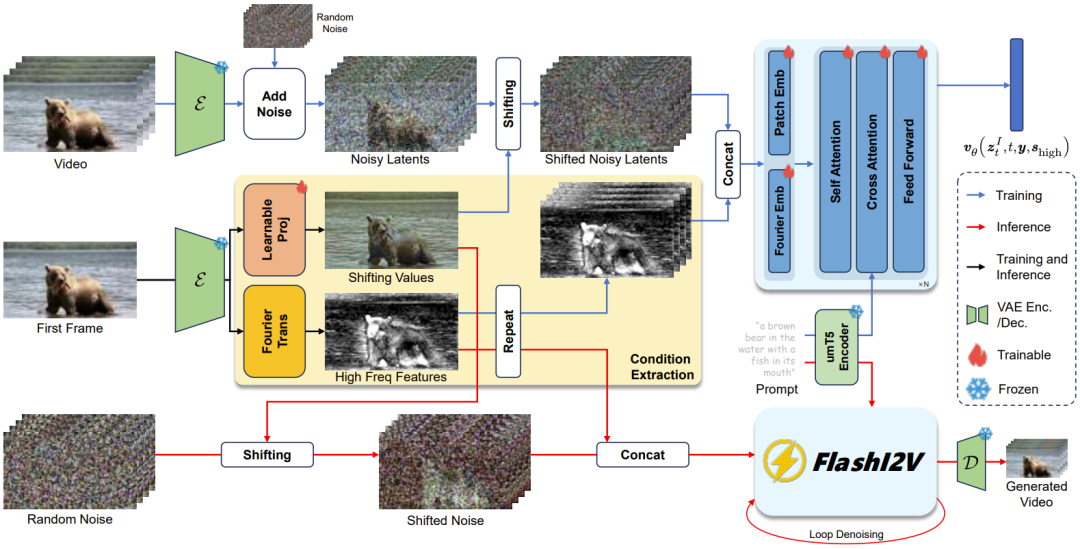
FlashI2V架构示意图:条件图像潜在变量首先被投影和偏移,以形成隐式编码条件信息的中间表示。同时,图像经过傅里叶变换后的高频幅度与带噪潜在变量拼接,并输入到DiT主干网络中。在推理过程中,去噪从偏移后的噪声开始,并沿着常微分方程ODE轨迹进行,直到重建出最终视频。
对其进行技术深度剖析,FlashI2V的杀手锏主要体现在两个相互配合的关键设计:
潜空间偏移(LatentShifting):这相当于在扩散链路中引入了一个「运动自由度阀门」。在具体的实现中,它通过修改流匹配的分布,将条件图像信息隐式地整合进去。模型利用一个可学习的投影模块,将原始潜变量转换到一个包含丰富结构和高频特征的空间中。这从根本上减少了去噪器对条件图像的过度依赖,有效缓解了泄漏问题,避免了对首帧的控制过度,从而让视频真正动起来,保证了高保真的动态运动。
傅里叶引导(FourierGuidance):在潜空间偏移的过程中,恢复图像的边缘和纹理等高频细节往往是一项挑战。该机制精准地在频域层面补齐了短板。它通过傅里叶变换提取图像的高频幅度特征,并将其与噪声潜在空间拼接后馈入DiT主干网络中。这在频域增强了运动预测的稳定性,用于校准细节,确保生成的视频轨迹不会跑偏。此外,它还允许模型通过调整截止频率百分比,对生成视频的细节水平进行细粒度控制,例如增强文本和精细纹理等小尺度结构的清晰度。

潜空间偏移和傅里叶引导分析。(a)随着训练的进行,可学习的投射ϕ(・)逐渐强调条件图像中的详细信息。(b)当使用较低的截止频率百分位数时,会注入更多高频信息。当截止频率百分位数设为0.1时,视频末尾的图形文字保持不变,而当截止频率百分位数设为0.9时,图形文字变得无法识别。
这两项技术的协同发力带来了立竿见影的实际收益。FlashI2V使得输入参考图像不会泄露到视频的像素层面,有效避免了一张图复制成一段视频的僵硬感,同时保持了真实且流畅的运动轨迹,具备极强的时间一致性与空间结构稳定性。
从量化指标来看,研究团队观察了不同I2V范式的块式FVD(Chunk-wiseFVD)变化模式。传统的范式在域内数据上的FVD会随着时间推移而增加,但在域外数据上始终保持较高水平,这意味着它们难以泛化。只有FlashI2V能够保持一致的FVD变化模式,成功将从域内数据中学到的生成规律泛化应用于域外数据。得益于此,该项目不仅取得了最低的域外FVD,并在多项I2V关键指标上成功超越了Wan2.1。
两大主要创新
用VLM实现理解&用I2SV控制艺术表达
在利用FlashI2V解决了物理真实感之后,UniWorld-OSP2.0团队进一步在模型的认知深度与艺术审美上实现了双重突破。
其一,引入VLM重构认知理解机制。
传统的纯文本编码器(如T5)提取的特征往往只能捕获表层词汇线索,导致细粒度指令对齐面临瓶颈。
为此,正如前文所述,团队引入了一个冻结状态下的预训练VLM(例如7B参数量的Qwen2.5-VL)作为核心多模态特征提取器。该模块会综合图像与文本提示,生成富含复杂跨模态关系的深层多模态表示。
随后,通过一个专门设计的轻量级可训练Adapter模块,这些高维语义在特征维度上与DiT主干网络实现了精准对齐。
这种设计让模型直接继承了VLM强大的视觉基础知识,大幅提升了对角色、动作等细粒度信息的控制精度,让模型真正具备了「看懂」复杂场景的能力。
有了VLM加持的UniWorld-OSP2.0具备优秀的视觉理解能力
其二,推出I2SV任务拓展可控艺术表达。
仅仅还原真实的物理世界依然不够,视频生成同样需要可控的艺术加工。
以往的视频风格化多依赖后期叠加滤镜,缺乏对画面内容的深度融合。为了打破这一局限,研究团队构建了一个包含12种典型艺术风格(如吉卜力、3D渲染、水墨画、乐高风等)的专属数据集,并在统一框架下推出了全新的I2SV(图像到风格化视频)范式。

包含的12种典型艺术风格
现在,模型可以在生成期直接接收原始图像、文本描述以及目标风格指令,一步输出时间连续且符合语义的风格化视频。配合严格的回环式质量监控策略,该机制可确保角色动作与语义细节得到完美保留,有效避免了角色变形与动作漂移的问题。
OSP-RealTime14B
把视频大模型带进工业阶段
过去一年大家默认的逻辑很简单:模型越大,质量越强,但速度一定越慢。能实时跑的,通常是1B级别的小模型;14B这种规模,只能老老实实离线生成。
袁粒课题组又基于UniWorld-OSP2.0训练了一个模型OSP-RealTime14B(这也是Helios系列底层的核心技术),在单块昇腾AtlasA3系列产品上直接把帧率拉到了10FPS(文生视频),成为第一个真正接近「交互式视频生成」的开源级扩散架构。
为此,OSP-RealTime14B将长视频生成,重新定义为无限的视频续写任务,最大限度保留与预训练模型一致的推理方式。
通常,现有方案会利用滑动窗口机制配合因果掩码,将双向模型转换为自回归模型。这种方式本质还是“拼接式延长”,推理模式和训练不一致,质量上限受限。
而OSP-RealTime14B通过引入时间维噪声latent的拼接策略,在时间轴上对历史噪声状态进行延续,使扩散过程在窗口切换时保持运动连续性。在不改变原有训练范式的前提下,实现时间上的无限延展,最终实现更高的质量下限。
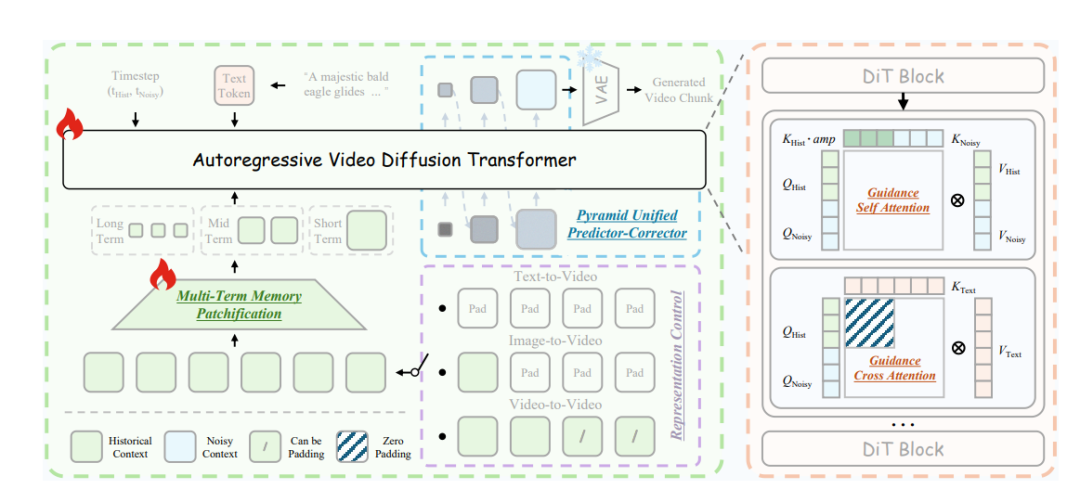
上图展示了实时长视频生成的实际架构:一个自回归视频扩散Transformer,基于GuidanceAttention模块构建。它通过Multi-TermMemoryPatchification和PyramidUnifiedPredictor-Corrector,对历史信息与当前噪声上下文进行压缩,从而降低计算开销;同时通过RepresentationControl实现对T2V(文本生成视频)、I2V(图像生成视频)和V2V(视频生成视频)任务的统一建模。
在生成加速上,袁粒团队做了三个关键优化。
第一刀砍在时间维度上,把噪声latent的帧数从21帧降到9帧。帧数减少带来的不是线性下降,而是平方级的算力节省,前向传播成本瞬间被压缩。
第二刀砍在分辨率策略上。先在低分辨率下完成大结构生成,再逐步细化到高分辨率。早期阶段计算便宜,只有后期才进入高成本计算区间,把「多尺度思想」引入到推理流程本身。
最后一刀是采样层面的压缩,靠的是DMD蒸馏,把扩散推理步数从50步压缩到4步。这不是简单减少step,而是把整个扩散轨迹学习成一个近似的快速映射,直接把时间开销压缩了一个数量级。

OSP-RealTime14B的实时无限长视频生成示例
为了让这种系统级改造在单块昇腾AtlasA3系列产品上真正跑起来,并将帧率推进到约10FPS,团队还做了不少工程上的探索。
比如,特征缓存方案(LatentsCache),「以查代算」,预计算并存储耗时最高的引导词特征,使多轮迭代训练时间缩短约30%,并释放20%的显存资源。
模型全程在昇腾AtlasA3系列产品上完成训练与推理,深度融合了MindSpeed-MM套件的分布式训练能力(如TP、SP并行)、断点续训(MindCluster)以及SmartSwap等原生特性。
总体而言,OSP-RealTime14B让其作为其基石的UniWorld-OSP2.0有了更广泛的开源意义,也有了商用规模化潜力。
如果14B都可以进入实时区间,那视频生成的边界就开始松动。它不再只是生成几秒钟的片段,而是有可能成为持续运行的系统。互动视频、生成式游戏场景、实时虚拟世界,这些过去停留在想象层面的应用,开始具备算力基础。
定义视频生成的「公共基础设施」
在开源体系里,UniWorld-OSP2.0率先将VLM的多模态理解、FlashI2V的物理生成、I2SV的艺术表达以及14B模型的实时化能力高度整合。这不仅在昇腾算力平台上跑通了工业级视频生成闭环,更在深层技术生态上,依托昇腾底座定义了视频生成的「公共基础设施」。
袁粒课题组为整个行业蹚平了众多深坑,节约了巨大的试错成本。在探索统一架构的过程中,他们排除了多尺度自回归带来的细节模糊、简单token早融合的质量瓶颈,以及LLM叠加Flow的工程局限,最终收敛出当前的最优解。
对于以昇腾为核心的国产智算生态而言,该项目提供了一份高价值的工程落地手册。团队在适配昇腾算力时,解决了底层通信算子的精度误差与非并行切分层的推理崩溃隐患。结合「以查代算」的特征缓存机制,开发者无需从零训练高耗能的VAE或调试脆弱的DiT架构,直接获得了极具经济性的成熟工具链。
面向未来,视频生成的终局远超像素的堆叠变换。UniWorld-OSP2.0展现出的跨模态对齐与物理规律学习能力表明,它正向着真正的「通用视觉世界模型」稳步迈进。