[RO]《Tether: Autonomous Functional Play with Correspondence-Driven Trajectory Warping》W Liang, S Wang, H Wang, O Bastani… [University of Pennsylvania] (2026)
在机器人操纵领域,让机器人自主积累经验是一个悬而未决的难题。过去的方法受困于对大量人工遥操作示范的依赖,本质原因是策略泛化能力弱——稍有空间或语义偏差便告失败,导致自主采集的数据质量低劣。
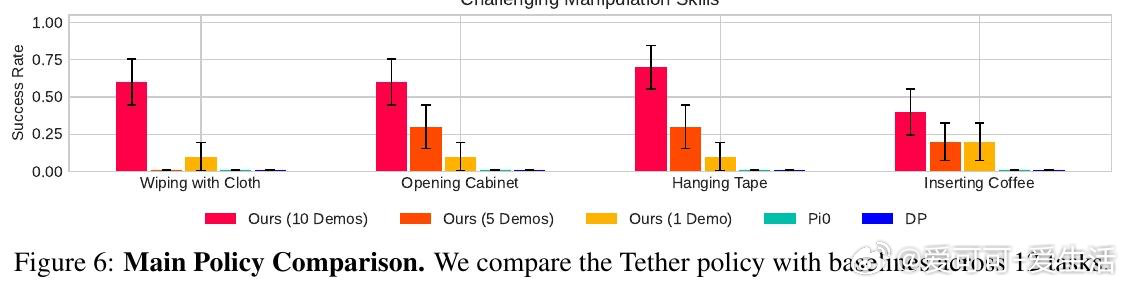
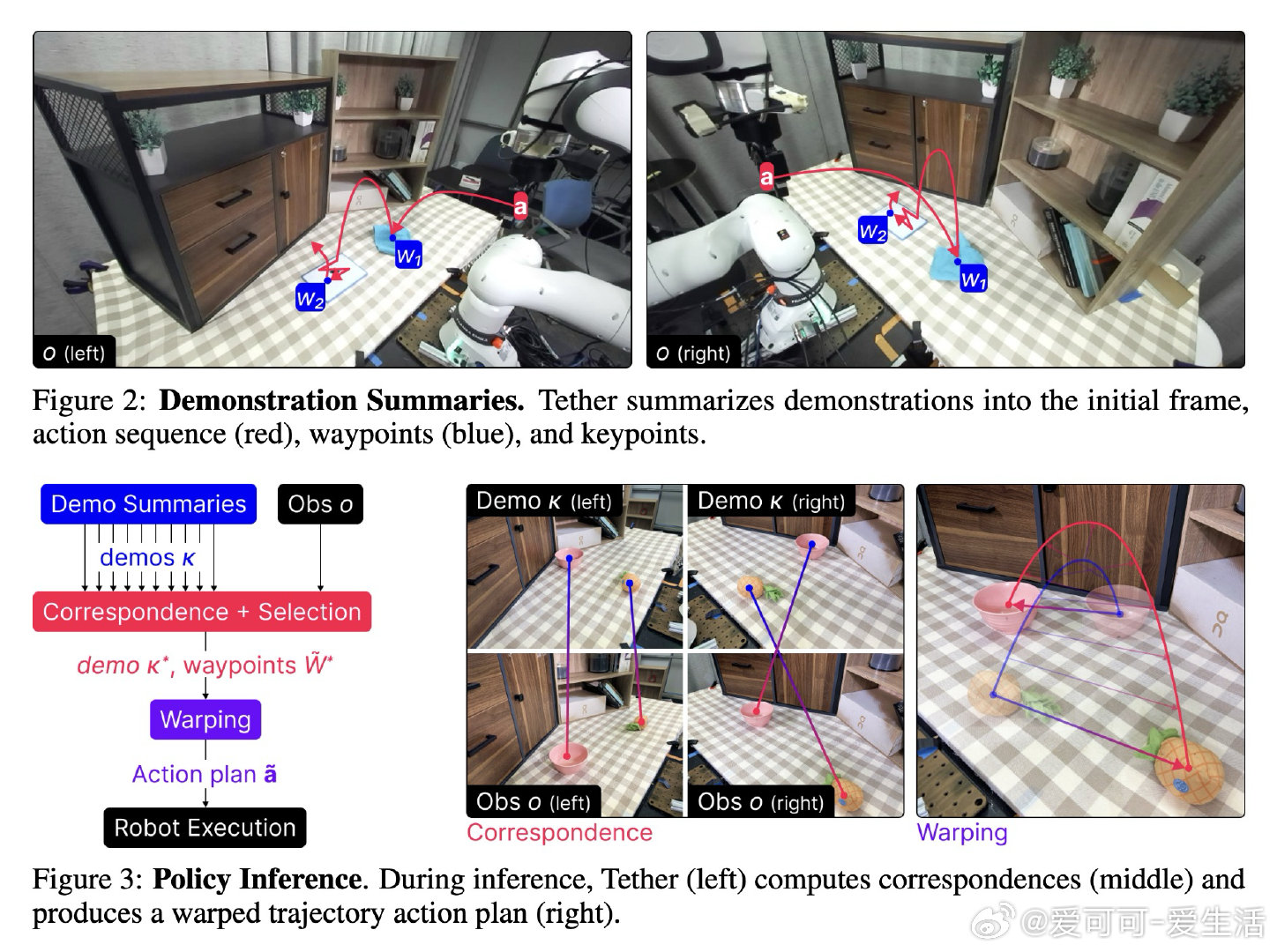
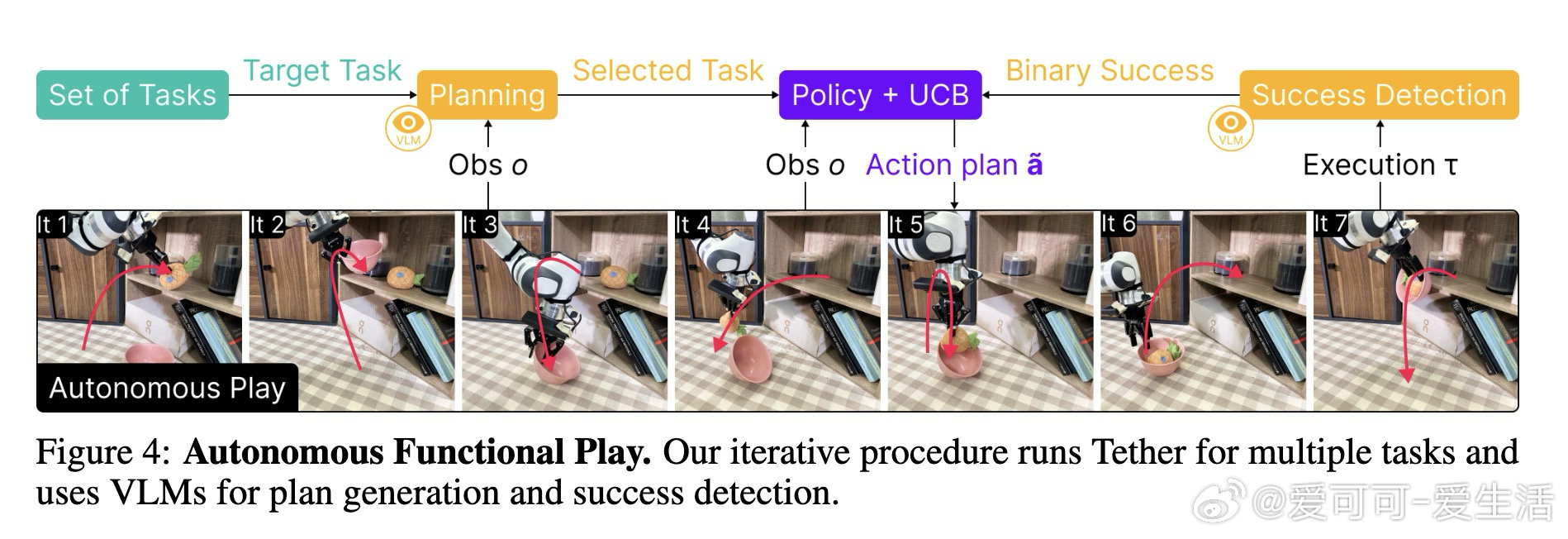
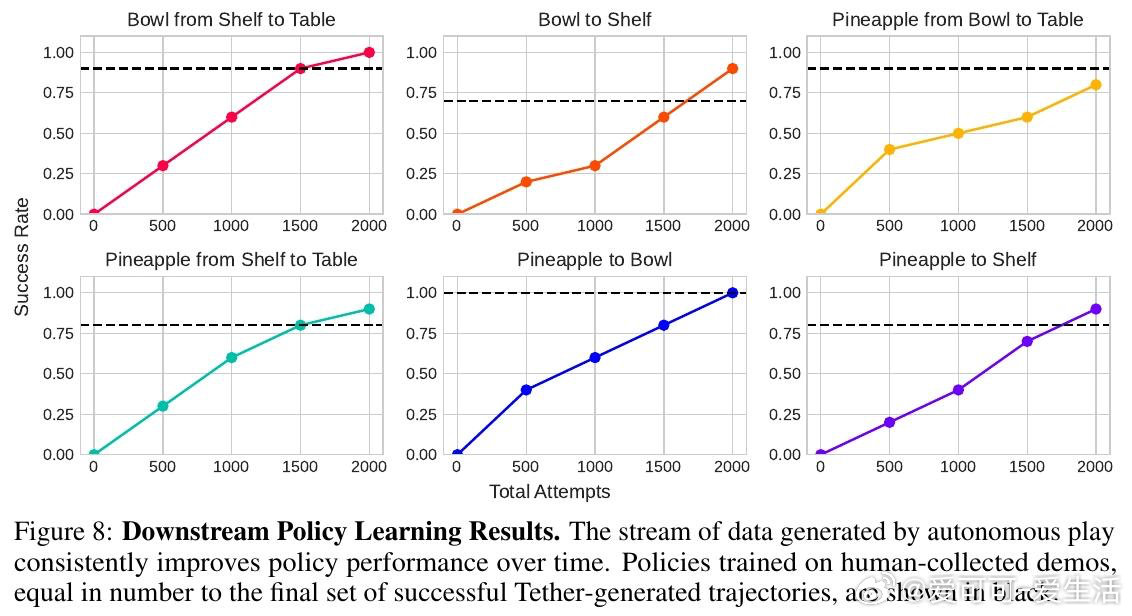
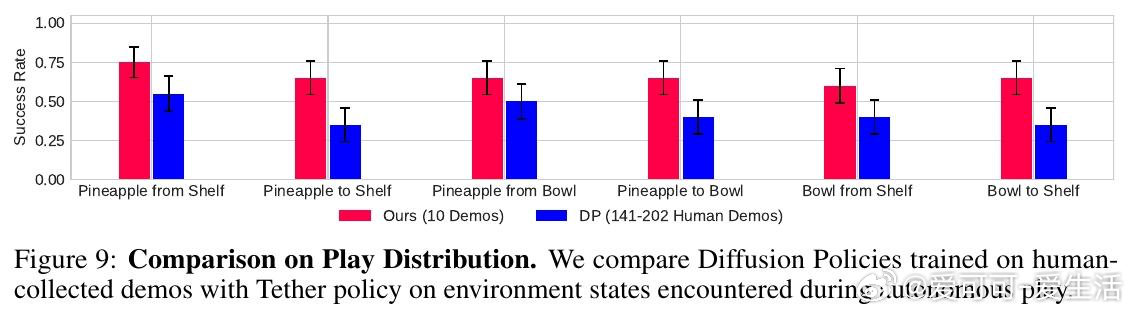
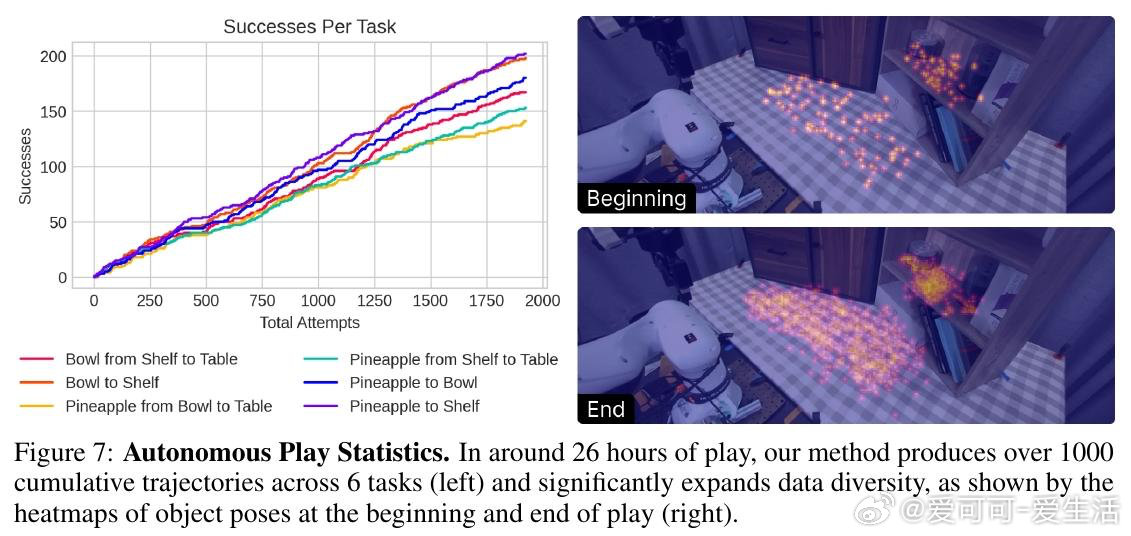
本文的核心洞见是:把机器人轨迹重新看作可被语义关键点"锚定"并弯折的弹性结构。由此,从新场景图像中找到与示范图像的语义像素对应关系、据此在三维空间中线性插值扭曲原始轨迹这一关键操作,使仅凭十条示范便能跨越物体外观与位置大幅变化的泛化得以实现。机器人以此为引擎,由视觉语言模型规划任务、评判成败,在无人干预下循环执行二十六小时,积累逾千条专家级轨迹。
这项工作真正留下的遗产是:用极少示范驱动长时自主玩耍、持续生成训练数据的闭环范式。它为后来者打开的新门是:将数据采集本身变成无需人力线性投入的自增长过程,使模仿学习策略随时间稳步逼近人类遥操水平。但尚未跨过的门槛是:开环执行天然缺乏对动态干扰的实时响应,关键点对遮挡的脆弱性也限制了其在杂乱、半可见场景中的可靠性。
arxiv.org/abs/2603.03278
机器学习 人工智能 论文 AI创造营