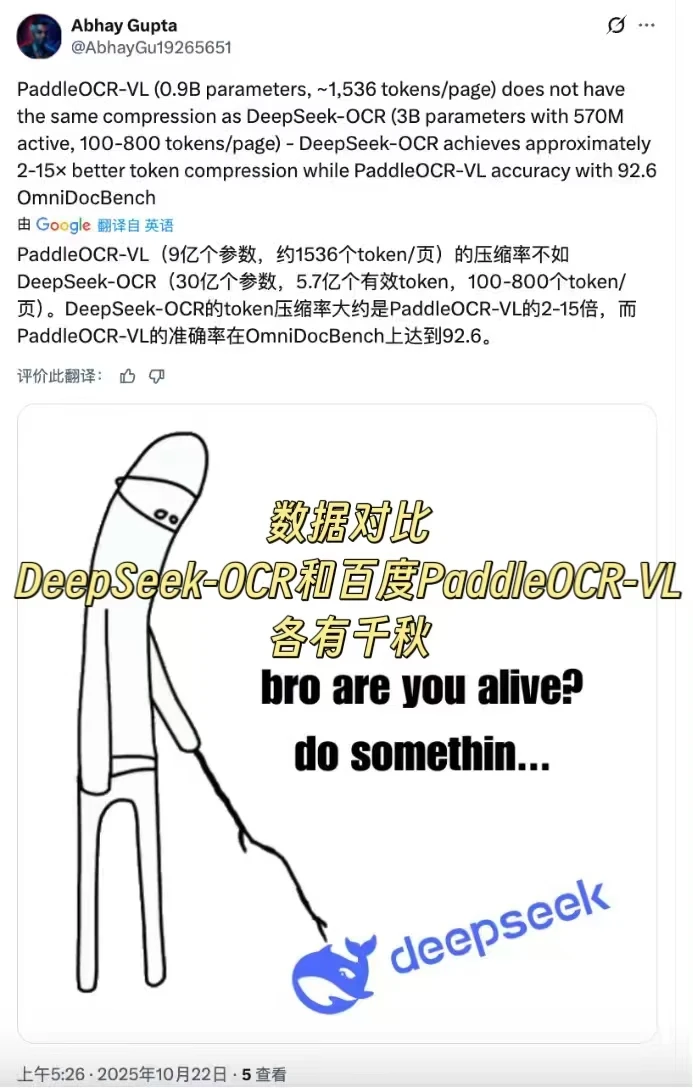
百度的 PaddleOCR-VL 热度简直了,10 月 16 号开源后直接霸榜:HFTrending 全球di一连霸 5 天,ModelscopeTrending、HuggingPaperTrending 也都是全球di一,GitHub 上更是冲到 Python 总榜di 3、全球总榜di 9。这波热度可不是虚的,X 上的官宣直接引爆 Reddit 社区,还被 Discord 推荐上了全球热榜,上百位海外 AI 研究员、KOL 都主动转发实测,连 HuggingFace 的研究员和十万粉科技博主都在安利。
而 DeepSeek-OCR 走的是另一条技术路线,主打“上下文光学压缩”创新——把文本转成图像再压缩视觉 token,10 倍压缩率下准确率还能维持在 95%以上,处理长文档时计算量能降低 87%,显存占用和速度都很有优势。不过实测下来也发现了一些短板,竖排文字、手写体识别错误率较高,处理表格容易错位,复杂公式的识别能力不如 PaddleOCR-VL准确,极端压缩时信息丢失还会加剧。
两款对比下来,DeepSeek-OCR 的压缩技术确实亮眼,适合追求长文本处理效率的场景,但要是落地生产,PaddleOCR-VL 显然能打。这个 0.9B 大小的模型,在权威测试里综合分高达 92.56,表格识别尤其领先,处理公式、多表格时特别稳。我自己上手体验后印证了这点,面对 PDF、扫描书籍、实验室数据这些格式混乱、数据量大的工业场景,它的表现堪称强大,确实是靠谱的选择。