作为企业数字化转型与智能运维的核心方向,OperationIntelligence正成为AI原生时代提升业务稳定性、降低运维成本的关键抓手,其技术发展与工程化落地始终围绕数据处理、语义理解、异常检测等核心环节展开。
阿里云可观测团队持续深耕,近期联合复旦大学、清华大学、同济大学等高校共同发表的OperationIntelligence领域系列研究成果接连被国际顶级学术会议ICLR2026、TSE2026、ISSTA2025收录,系统性攻克时序数据增强、大规模语义解析、跨系统异常检测等领域的核心技术难题,构建从数据基础设施到语义理解,再到工业级可部署的完整OperationIntelligence技术体系,进一步推动大模型在AIAgent自动巡检、辅助根因分析、智能故障自愈等场景的工程化落地,为规模化应用筑牢技术根基。
智能运维工程化落地三大挑战
难题一:语义鸿沟
传统工具处理运维数据,本质上是在做“形式匹配”。日志解析器把相似的字符串归到一类,时序分析套用图像领域的通用方法,异常检测只看单一指标。这些方法不理解timeoutafter30s和timeoutafter0.01s在运维语境下的本质差异,不懂时序数据的趋势、周期、平稳性等统计语义,也不知道日志、指标、调用链路之间的深层关联。语义的缺失,直接导致漏检和误报居高不下。
难题二:泛化瓶颈
真实运维系统从不静止。微服务频繁发版,日志模板持续演化;新业务系统上线,历史标注全部失效;数据分布随时间漂移,昨天训练好的模型今天就可能失灵。更棘手的是,工业级系统标注成本极高,每标注一套新系统,往往需要数月的人力投入。现有方法在稳定的实验室环境里表现优秀,一到动态演化的生产环境就水土不服。
难题三:工业可用性
学术界追求精度,工业界要求精度和效率并重。每秒10万条的日志流、100毫秒内的异常响应要求、有限的内存和算力预算——这些硬约束让很多“论文上的好方法”止步于实验室,无法真正落地。
阿里云可观测系统性破局
(1)AutoDA-Timeserie:突破时序建模局限,让AI用更少数据预判故障
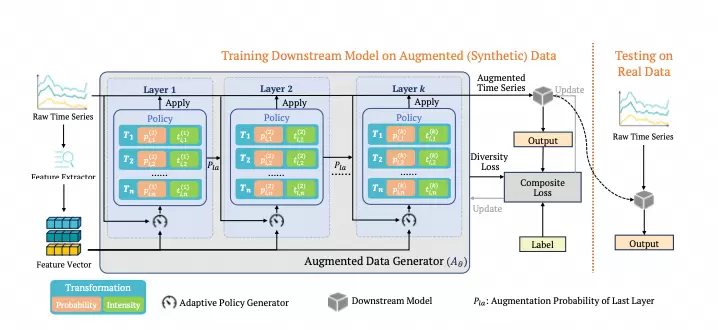
没有好的增强策略,就挖不出时序数据的真实潜力。长期以来,时序数据增强受限于图像域范式迁移、时序特征被忽视、增强策略无法自适应,现有AutoDA框架盲目套用图像变换,破坏自相关性与时间依赖关系,严重制约分类、预测、异常检测等下游任务性能。
ICLR2026录用论文《AutoDA-Timeseries:AutomatedDataAugmentationforTimeSeries》(清华大学&阿里云)首次提出面向时序数据的通用自动化数据增强框架,提取24维时序统计特征融入堆叠式增强层,通过Gumbel-Softmax可微采样以单阶段端到端方式自适应优化增强概率与强度;覆盖分类、长短期预测、回归、异常检测五大任务,在TCN上分类准确率达0.730(+6.7%)、ROCKET上达0.721(+5.2%),全面超越7种SOTA基线,为时序数据增强提供首个通用化、自动化的解决方案。
论文地址:https://openreview.net/forum?id=vTLmHAkoIW
(2)ASemanticLog:兼顾高精度与高吞吐,语义日志解析吞吐峰值128万条/秒
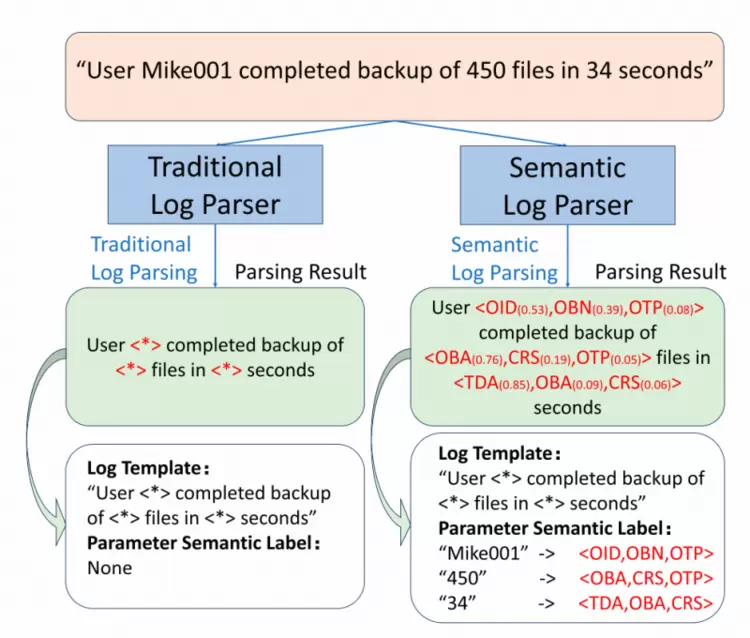
没有好的语义理解,就读不出日志参数背后的真实含义。日志解析技术在很长时间内一直停留在语法层面,即将动态参数统一替换为通配符,丢失了参数承载的对象ID、状态码、时间戳等语义信息,严重制约异常检测、根因分析等AIOps下游任务精度;现有LLM解析器多依赖ChatGPT在线API,面临隐私泄露、延迟不稳与版本不可控三重挑战,难以在生产环境落地。
TSE2026录用论文《SemanticLog:TowardsEffectiveandEfficientLarge-ScaleSemanticLogParsing》(复旦大学&阿里巴巴&同济大学)提出首个基于开源LLM的语义日志解析器,由三大核心模块协同构成:LogLLM移除因果掩码,将日志解析从文本生成重构为token分类任务以充分利用双向上下文;SemPerception模块通过多头交叉注意力聚合子词特征,实现16类细粒度语义分类(较VALB10类体系扩展60%,在企业日志上96%参数可被准确归类);EffiParsing前缀树缓存已解析模板,大幅减少重复推理开销。
基于LLaMA2-7B在LogHub-2.0基准上的全面评测表明,SemanticLog在传统与语义解析五项指标(GA93.3%、PA93.6%、FTA84.4%、SPA83.2%、SPA+55.9%)均取得最优,全面超越包括ChatGPT方案在内的11种SOTA解析器,语义解析精度SPA较同类方法VALB提升18.7%,推理速度优于所有LLM解析器;下游异常检测实验中,细粒度语义标注使检测F1最高提升4%,为语义日志解析在隐私敏感场景下的工程化落地提供了高效、可靠的开源方案。
论文地址:https://ieeexplore.ieee.org/document/11216353/
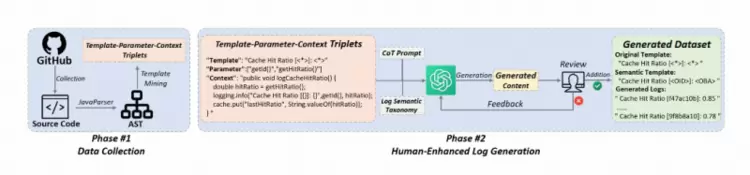
(3)LogBase:首个语义日志解析基准,让AI真正"读懂"每一条日志
没有好的尺子,就量不出真实的进步。语义日志解析领域长期面临标注稀缺、数据规模受限、评测标准碎片化等系统性挑战,主流基准LogHub-2.0仅覆盖14个系统、3,488个模板,严重制约AIOps下游任务精度。
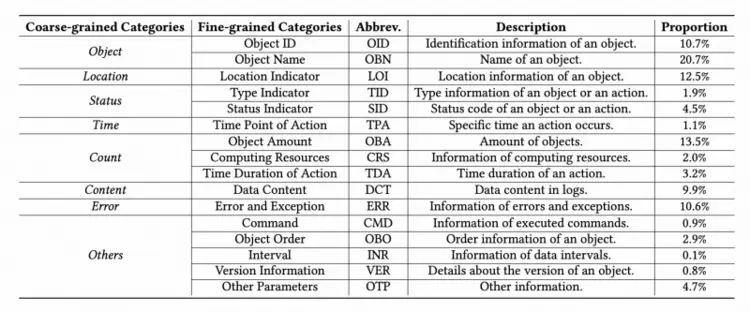
ISSTA2025录用论文《LogBase:ALarge-ScaleBenchmarkforSemanticLogParsing》(复旦大学&阿里巴巴&同济大学)构建了首个大规模语义日志解析基准,覆盖130个开源项目、提供85,300个高质量语义标注模板,相较LogHub-2.0数据源规模提升约9倍、模板数量扩大24.5倍;配套8+16层次化语义分类体系与自动化构建框架GenLog,首次实现从语法解析到语义理解的评测范式升级,对15种主流解析器的全面评测暴露了现有方法在复杂场景下的真实短板,为语义日志解析走向工程化落地提供统一标准与可靠基座。
论文地址:https://dl.acm.org/doi/10.1145/3728969
目前,阿里云可观测团队已将上述创新技术融入云监控CMS、日志服务SLS、应用实时监控ARMS等产品体系,实现精准智能告警、深度日志理解、低门槛运维智能化,帮助企业打破运维效率瓶颈、降低成本、提升业务稳定性。
大模型与AIAgent技术加速迭代,可观测数据作为连接AI与生产系统的关键纽带价值持续凸显。阿里云可观测团队将持续以学术创新驱动技术突破,完善OperationIntelligence技术体系,参与行业标准建设,推动AIOps规模化落地,为企业数字化转型提供更坚实的智能运维支撑。