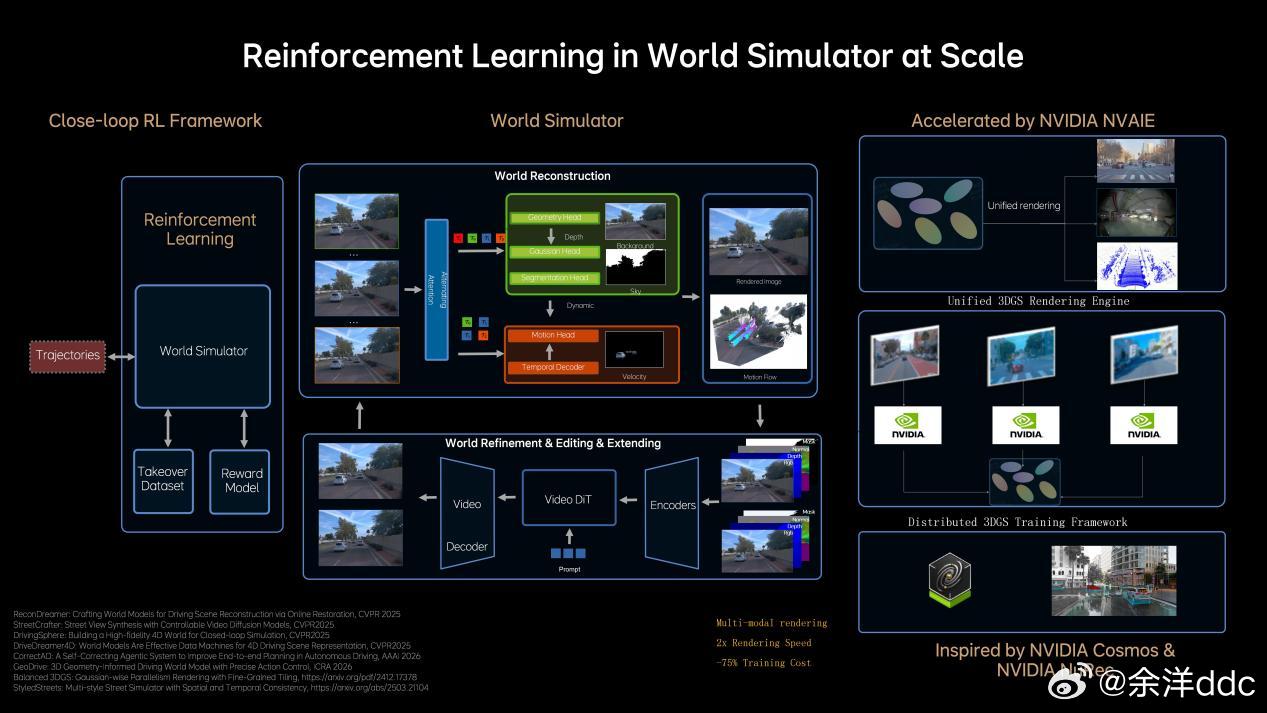
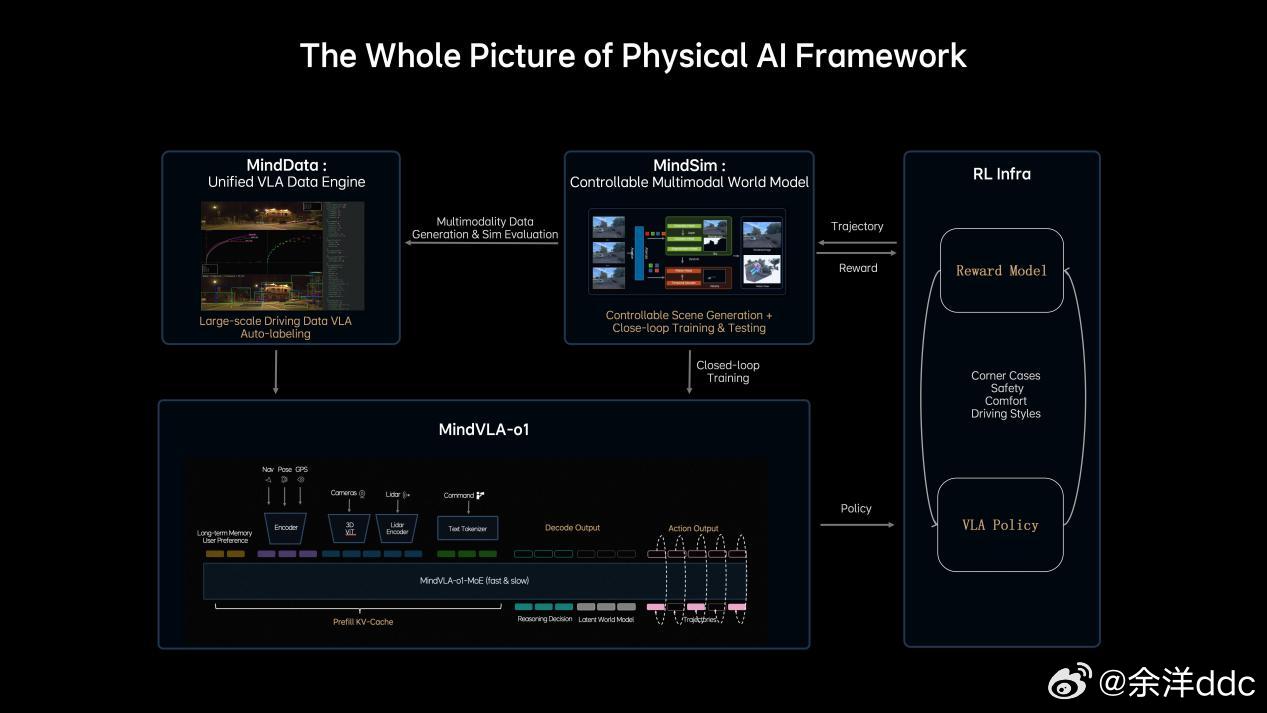
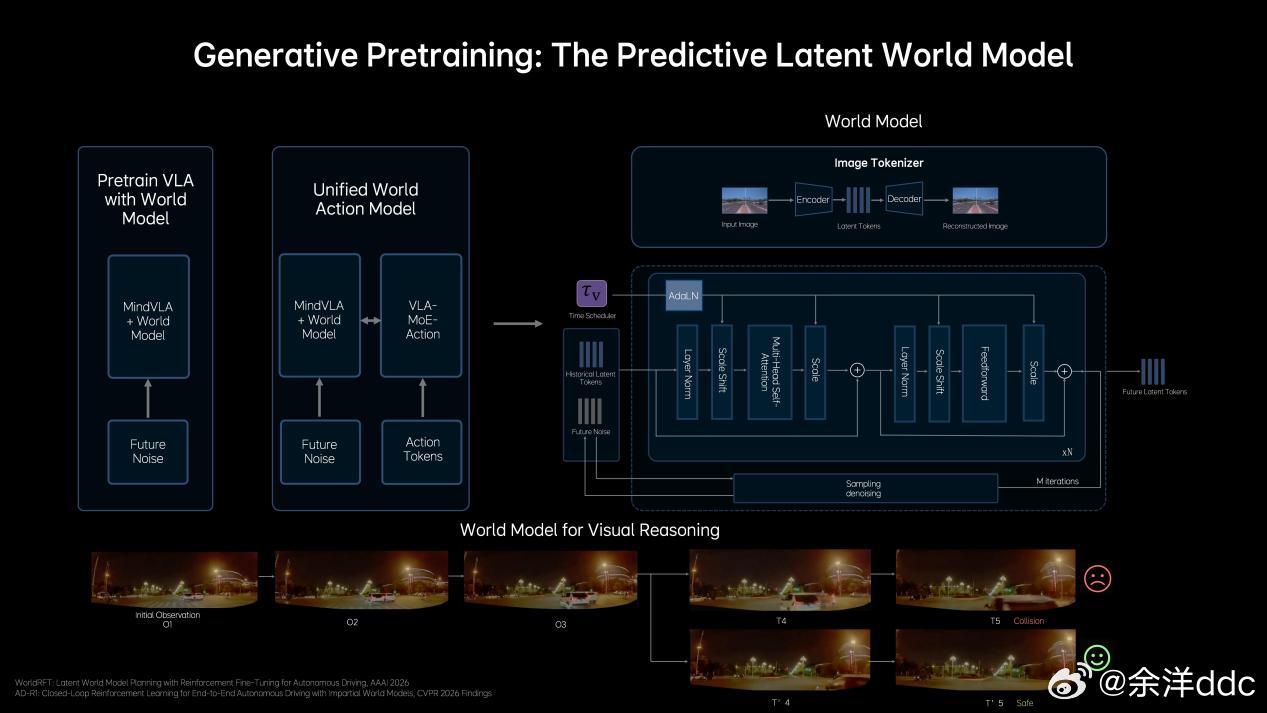
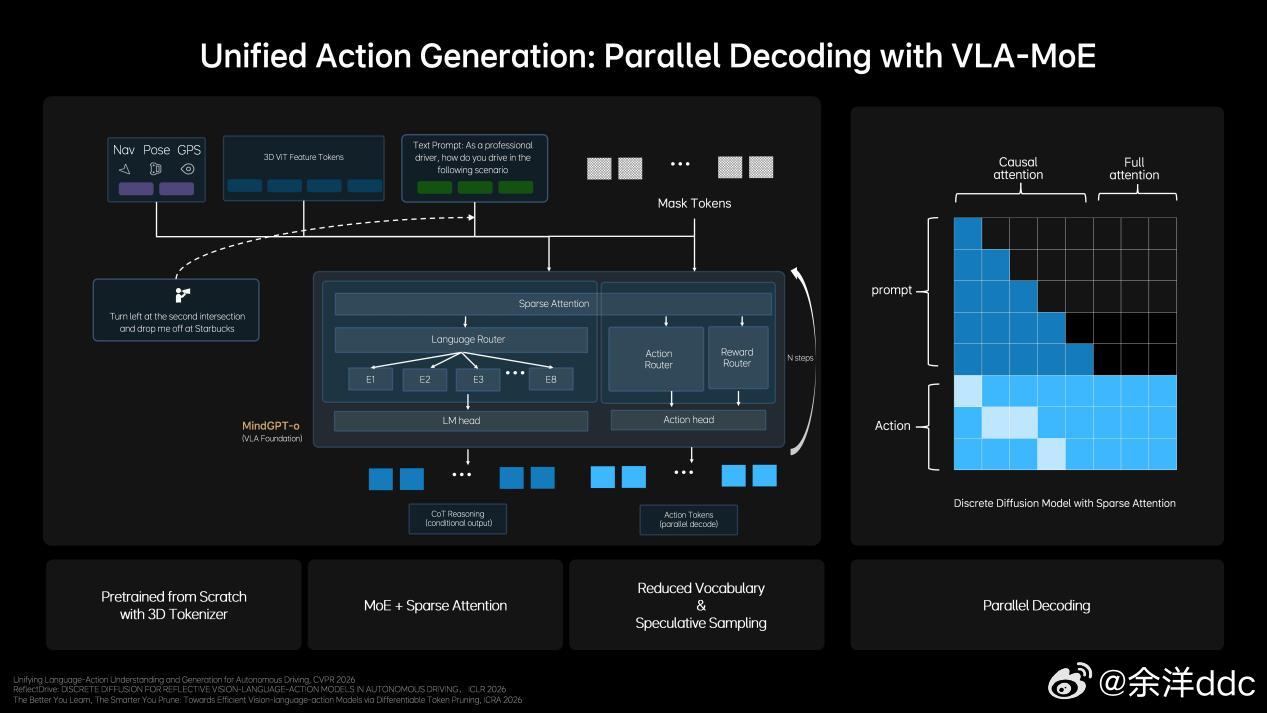
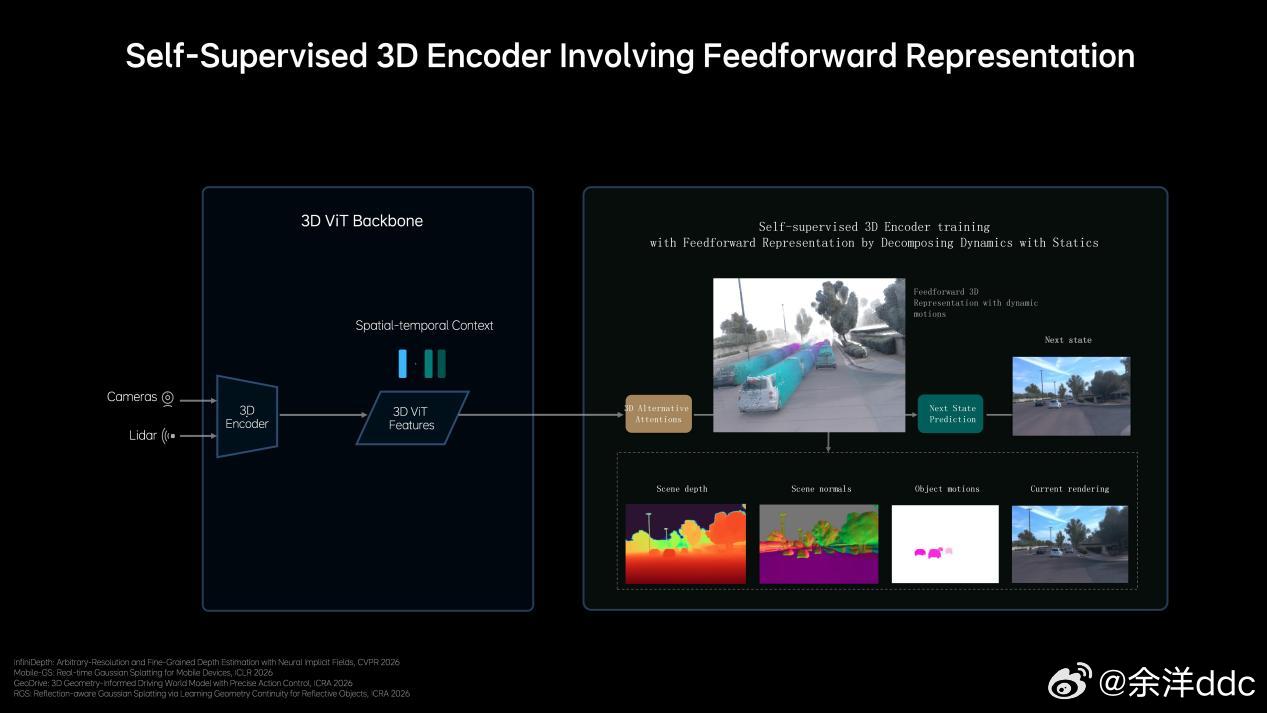
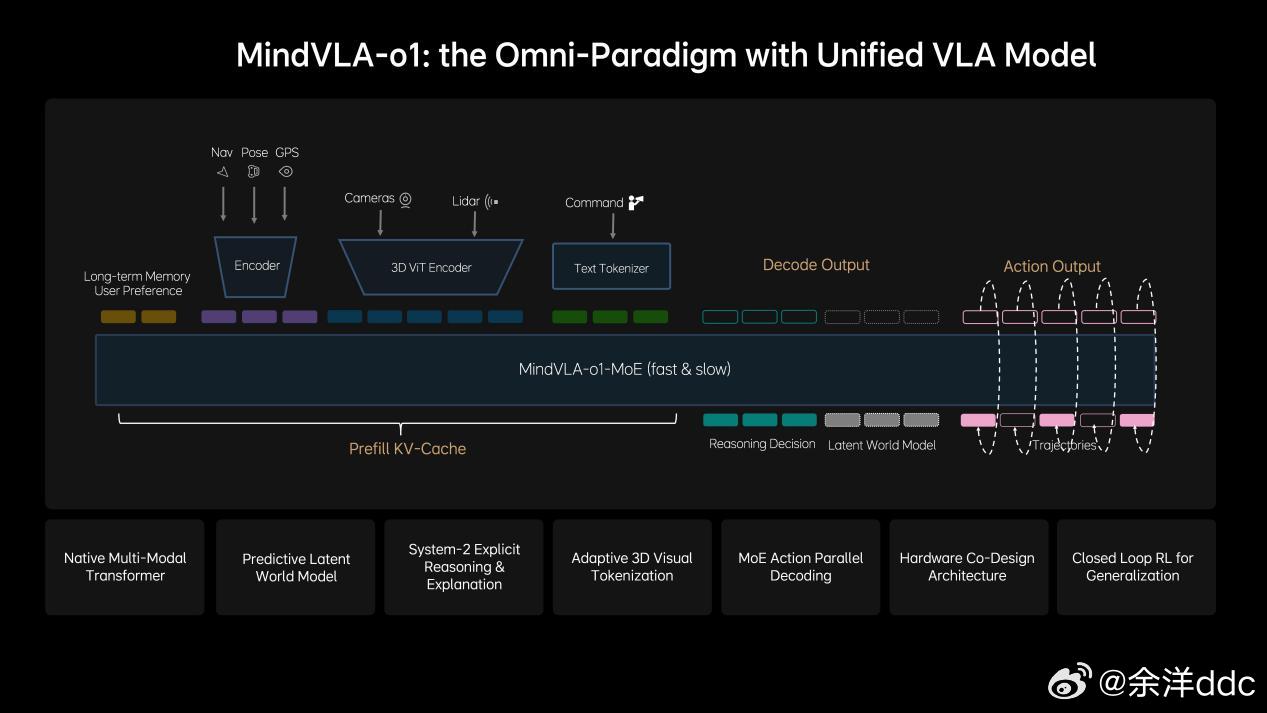
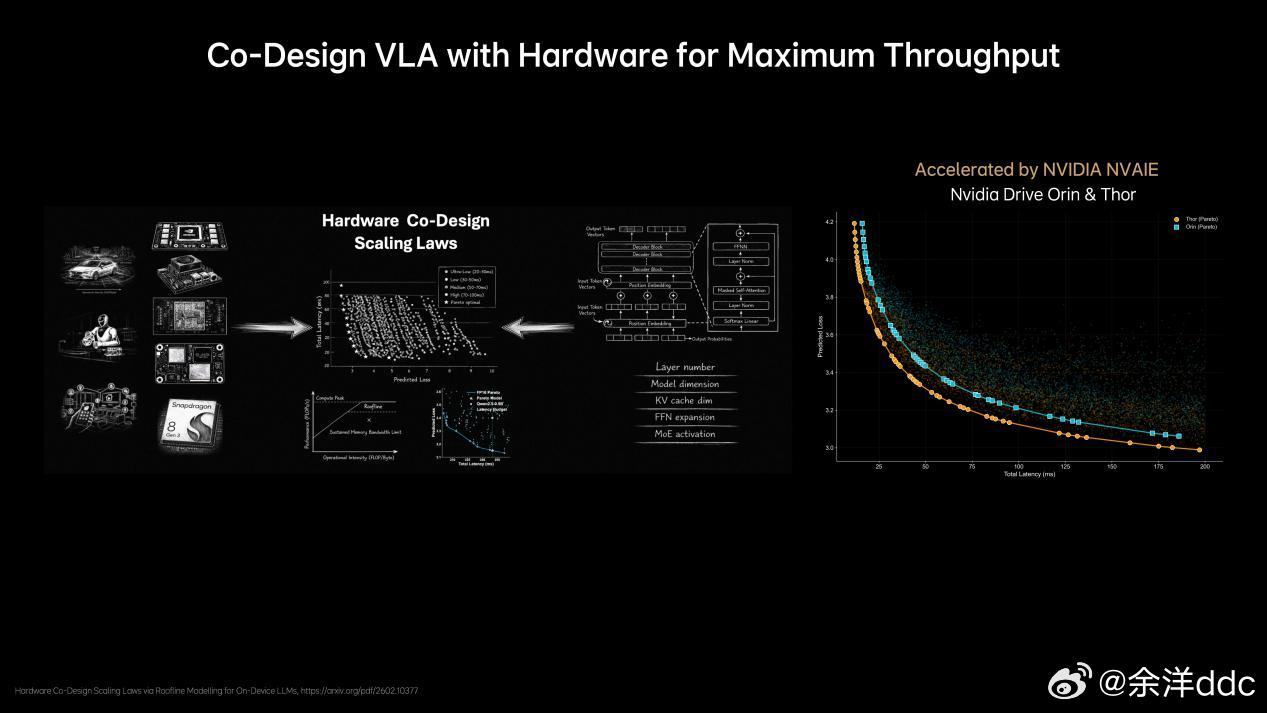
说在前面,对AI我非专业人士,业内人士的交流讲究效率,专业词汇太多,作为用户层面,第一次看见专业词汇根本看不懂,咱们就大白话讲理想汽⻋基座模型负责⼈詹锟在2026GTC⼤会(英伟达主办的聚焦AI的年度大会)上,发布了下⼀代⾃动驾驶基础模型MindVLA-o1在物理世界中,AI进展缓慢的一个重要原因,就是对于预训练的思考不够。目前绝大多数视觉训练是基于看二维图像或者视频,能看懂文字语义,但是不能真正理解真实三维世界。举例:就像我平时拿显示器玩赛车模拟器,对于路线把控,刹车点都需要适应;而如果拿头戴VR玩,他是三维的,有空间纵深感,非常容易找到空间适应能力,代入感非常强,不过很多人会晕…那对于理想来说他们的解决方案就是3D ViT+多模态,就相当于人在真实世界开,效果肯定好得多,但是这会增加大量的算力消耗,相比2D模型,3D ViT算力要增加10倍…(玩VR也知道非常吃显卡…)这就需要用到理想的马赫100芯片了,单颗1280TOPS算力,有效算力是英伟达Thor-U芯片的三倍,21年开始研发,26年随全新一代理想L9上车…再就是多模态思考能力,再举例:我这i6遇到路上左侧是公交道,路牌上限时早上7:00-9:00私家车不能走,这需要看懂图像再进行语言推理,理解哪些时候能走、哪些时候不能走(现在已经可以),不具备这个能力的车上去,看到公交车道就会直接往右变道…当然不仅仅是纯语⾔的思考,语⾔擅⻓处理抽象概念和逻辑关系,但在理解具体、形象化的物理空间关系时,还需要依赖对场景的想象和空间推演能⼒,这同样属于思考的⼀部分。理想汽⻋将语⾔推理与空间理解等能⼒融合,形成新⼀代的多模态思考框架。今年年中这⼀能⼒将与3D ViT结合,使模型能够真正理解三维空间并具备更完整的3D认知能⼒。李想称机器人也用VLA理想发布下一代自动驾驶基础模型李想回应AI时代的焦虑