[LG]《Beyond Single Tokens: Distilling Discrete Diffusion Models via Discrete MMD》E Hoogeboom, D Ruhe, J Heek, T Mensink… [Google DeepMind] (2026)
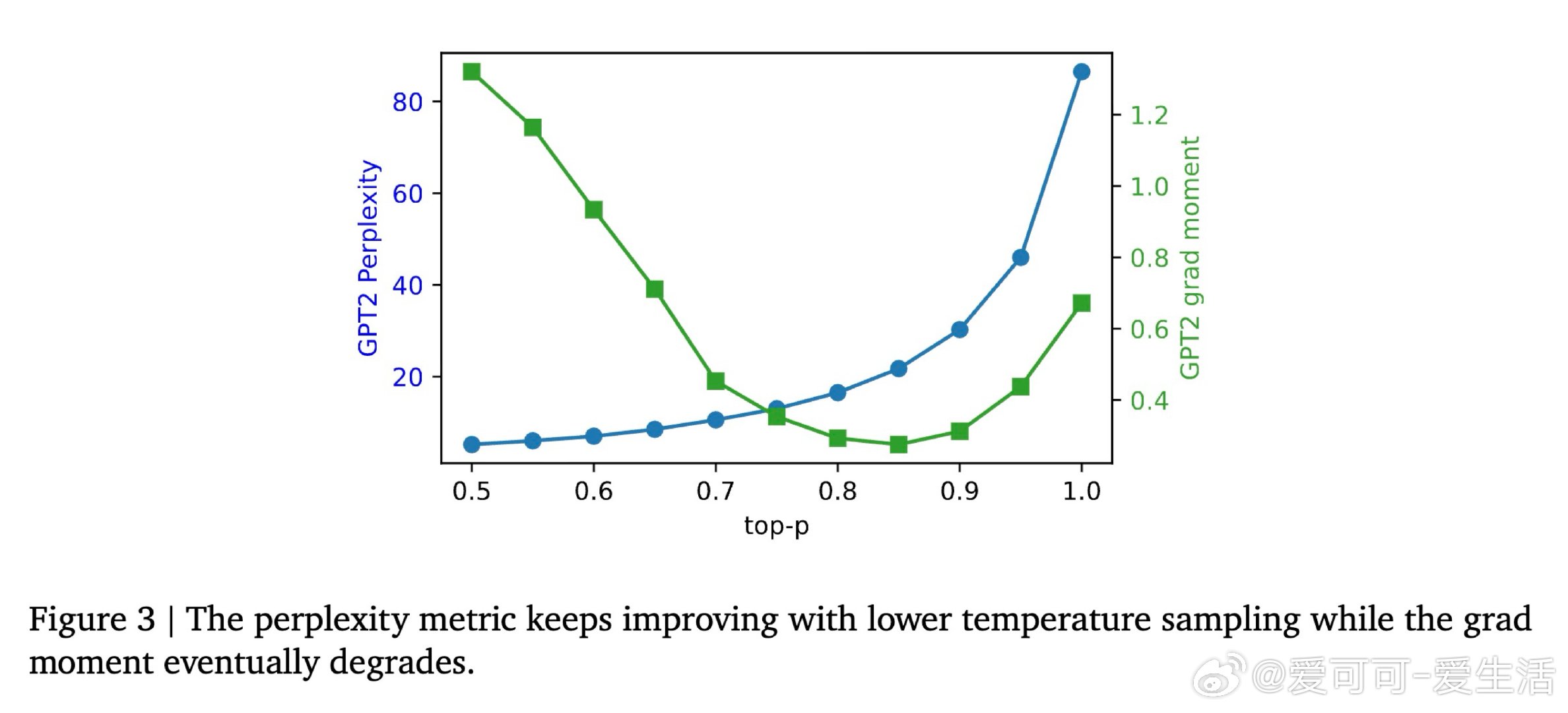
在离散扩散模型领域,将多步采样压缩为少步生成是一个悬而未决的难题。过去的方法受困于离散空间无法传递梯度,本质原因是令牌采样的独立性假设切断了分布匹配所需的反向信号,导致蒸馏后模型要么质量崩塌,要么多样性丢失。
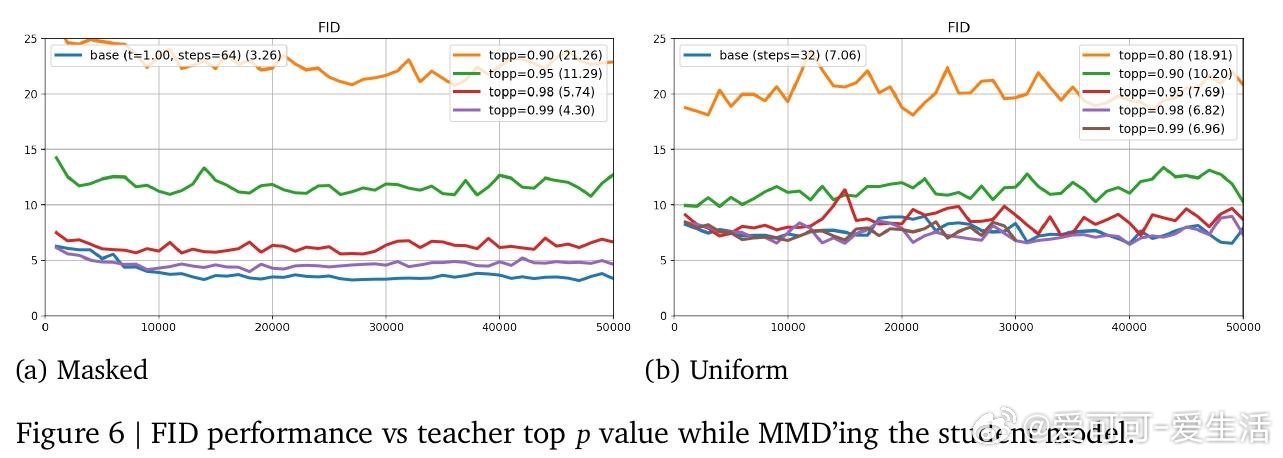
本文的核心洞见是:把"离散输出的差异"重新看作"对数概率空间中的教师-辅助模型差值信号"。由此,用软概率向量替代硬采样、并交替优化生成器与辅助模型这一关键操作使问题得以解开——生成器被迫压缩其因子化输出熵来隐式建立跨令牌相关性,而无需改变模型架构。
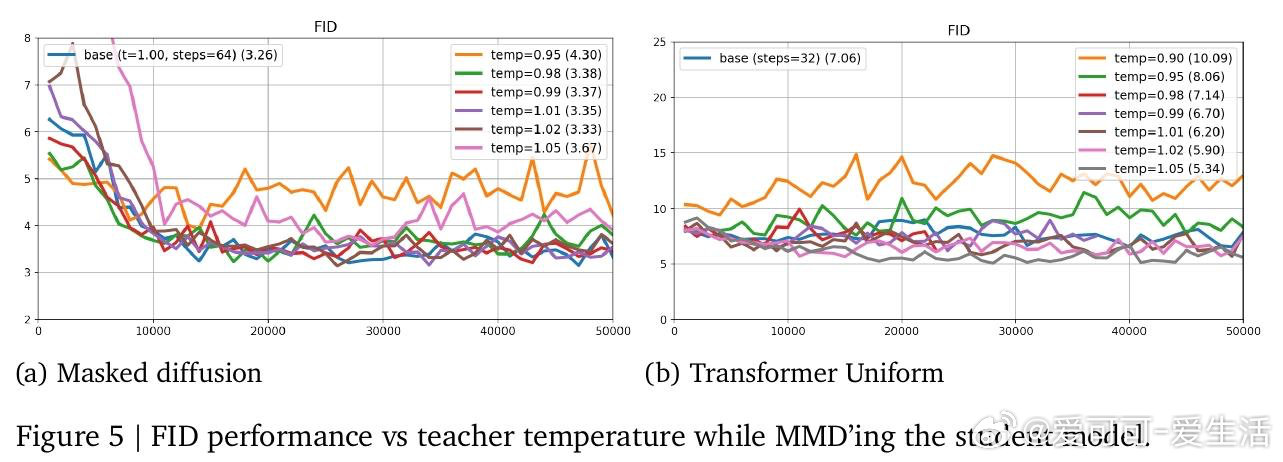
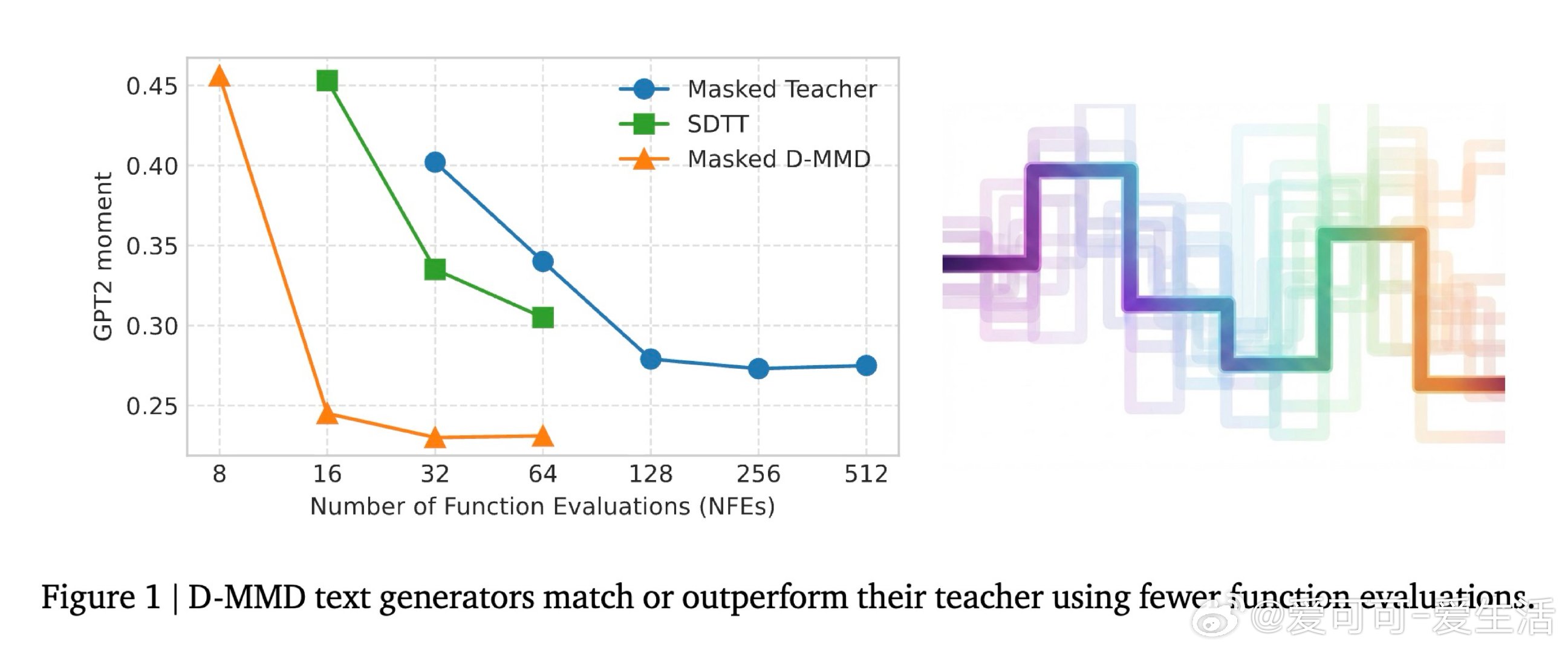
这项工作真正留下的遗产是:一套将连续MMD蒸馏原理迁移至离散空间的通用框架,以及一个比生成困惑度更可靠的评估指标——梯度矩。它为后来者打开的新门是:离散扩散模型可在十余步内超越其教师,使扩散语言模型的推理成本首次与自回归模型具备可比性。但尚未跨过的门槛是:蒸馏后的模型质量最终仍受限于教师上界,且与标准自回归模型之间的性能差距依然存在。
arxiv.org/abs/2603.20155
机器学习 人工智能 论文 AI创造营