[LG]《Causal Evidence that Language Models use Confidence to Drive Behavior》D Kumaran, N Daw, S Osindero, P Velickovic… [Google DeepMind] (2026)
大型语言模型是否真正利用置信度信号来驱动自身行为,而非仅仅输出置信度——这一问题悬而未决。既有研究止步于"模型能否产生校准的置信度估计",却未追问这些内部信号是否实际参与决策控制。以"答题还是弃权"为切入点,正面挑战这一盲区。
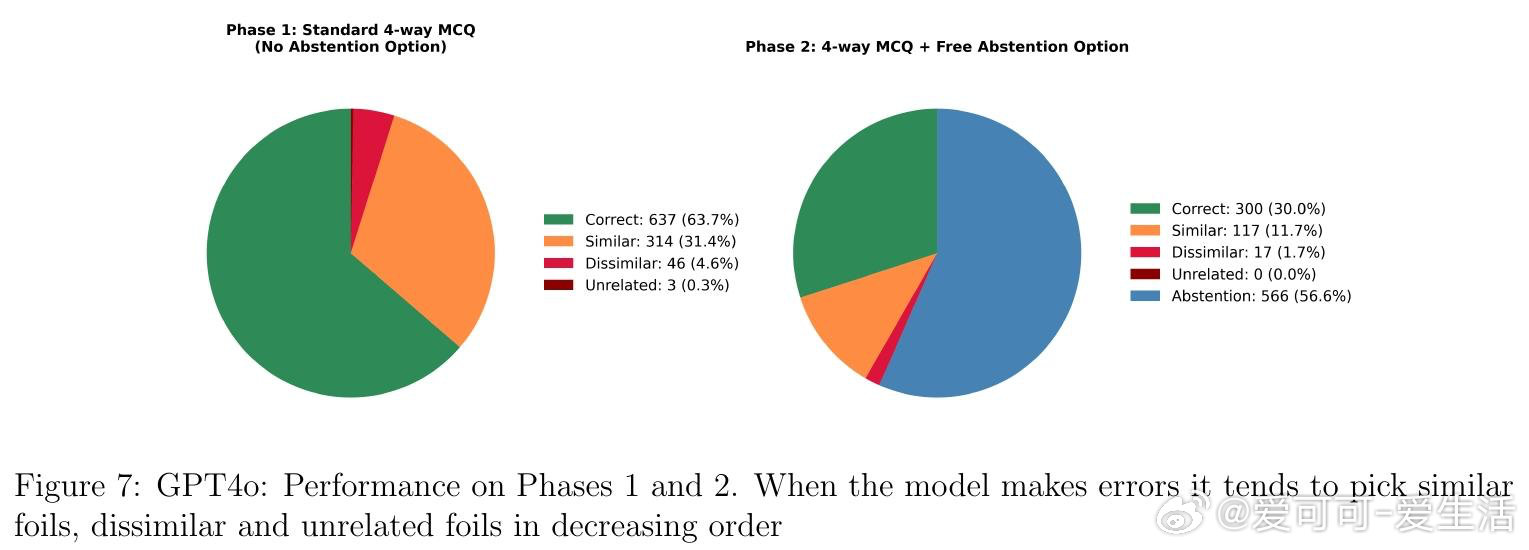
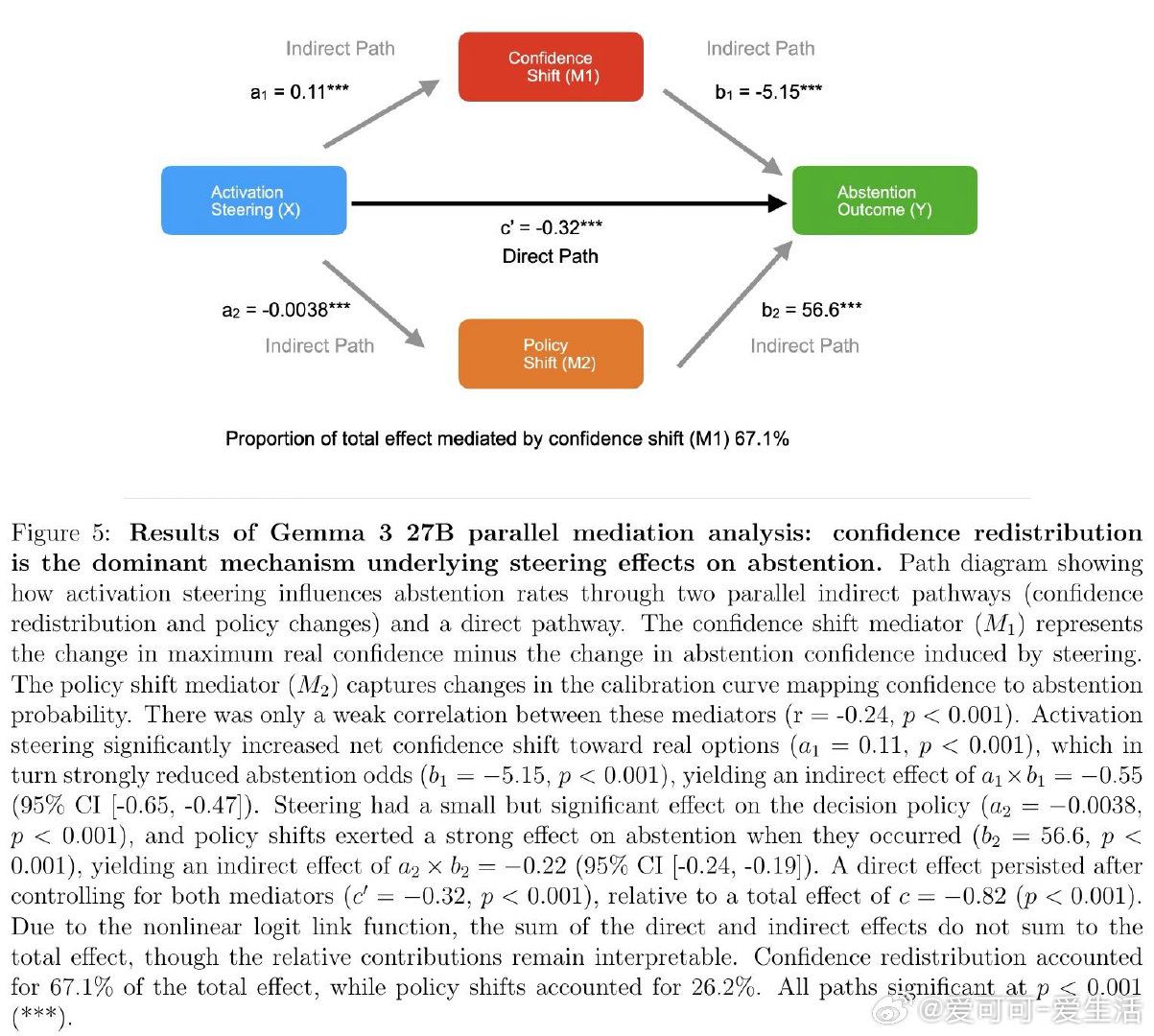
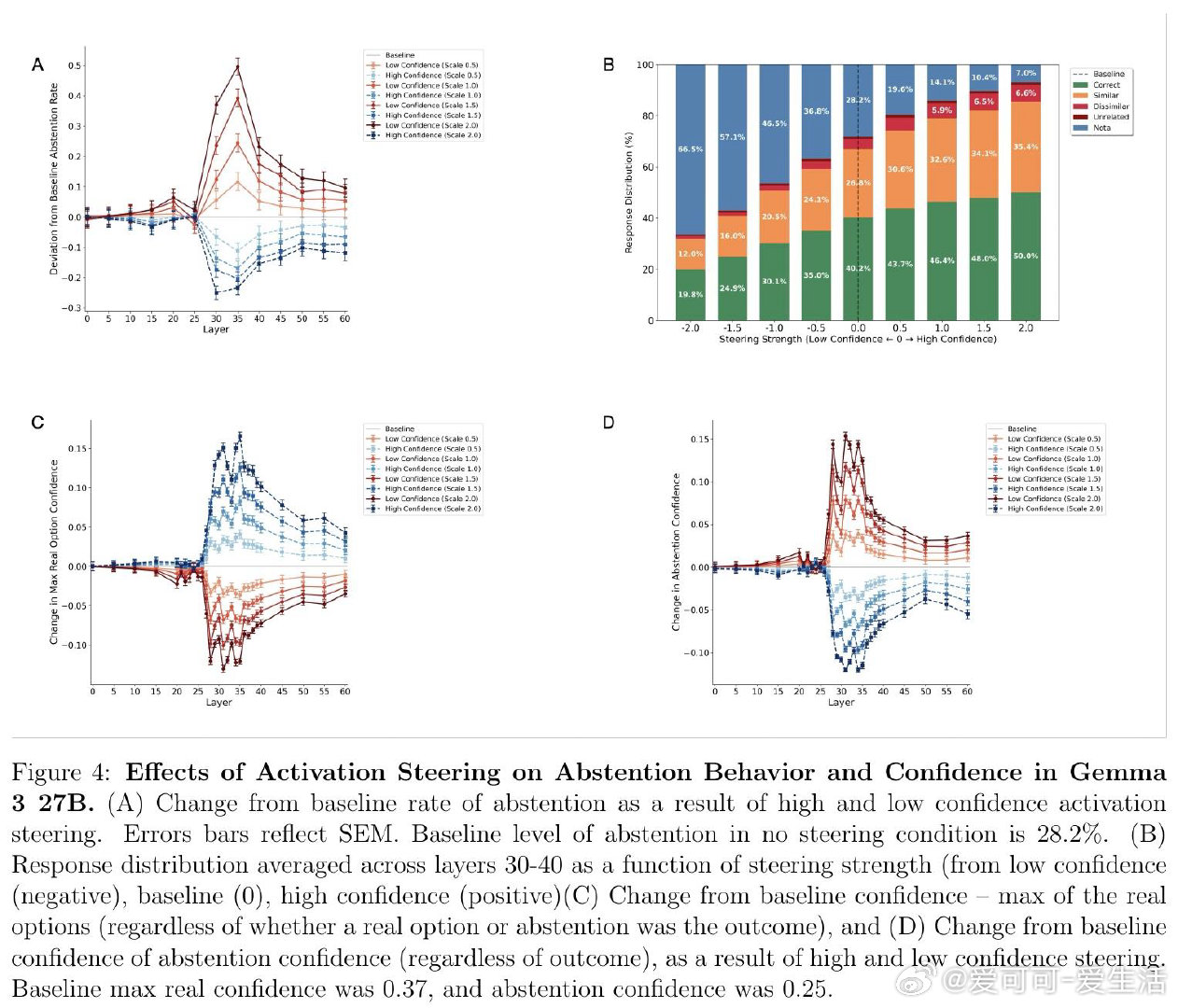
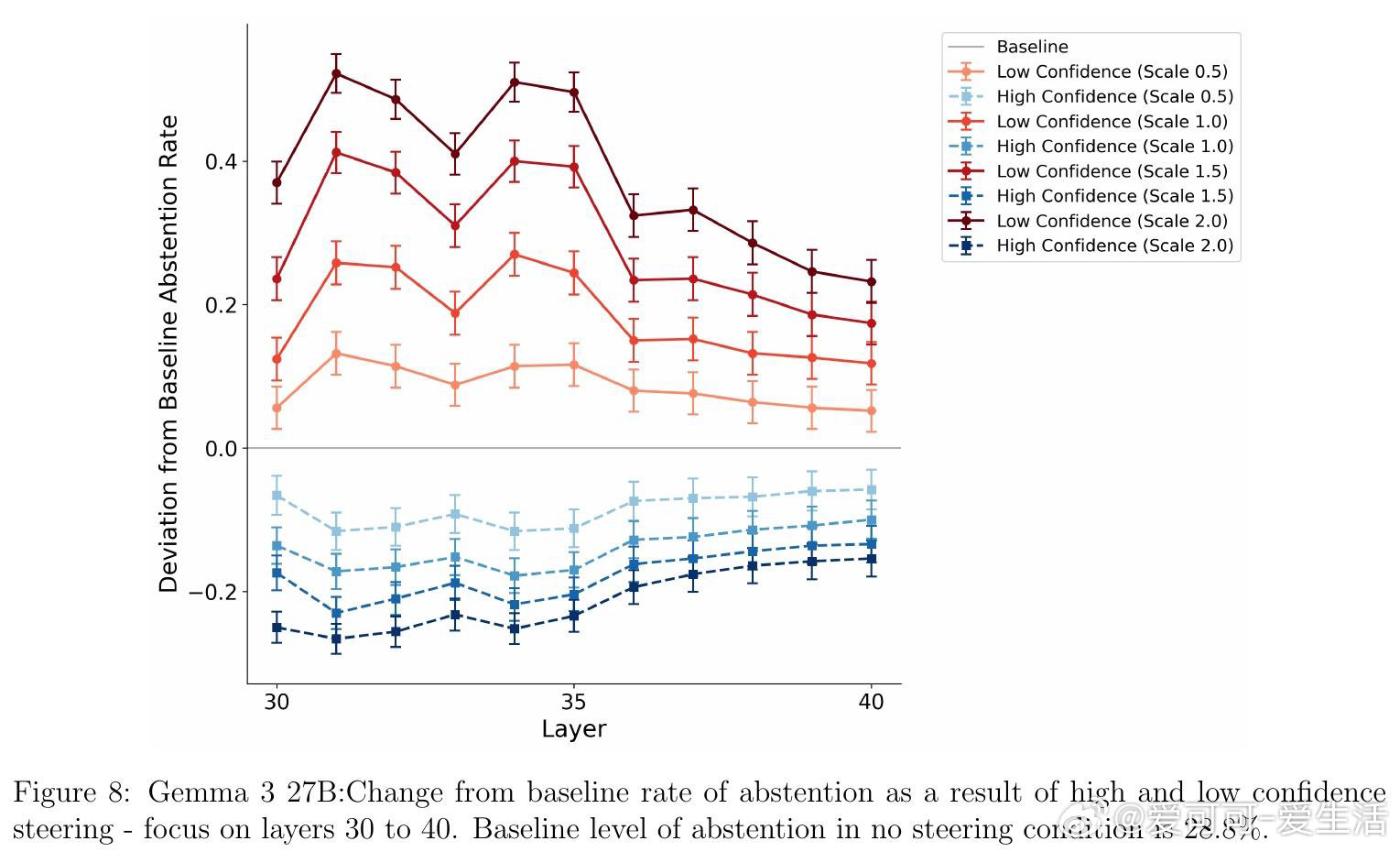
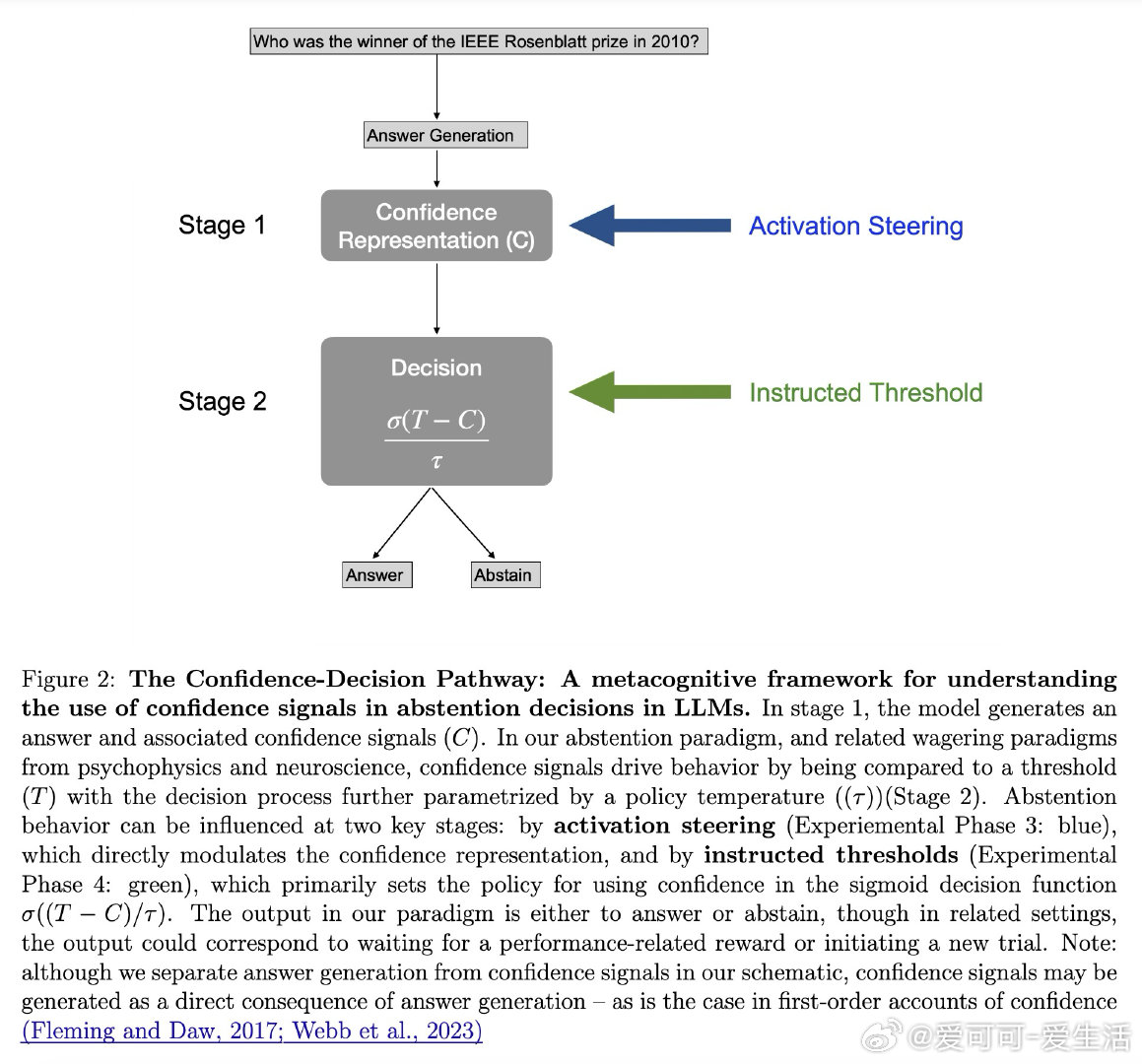
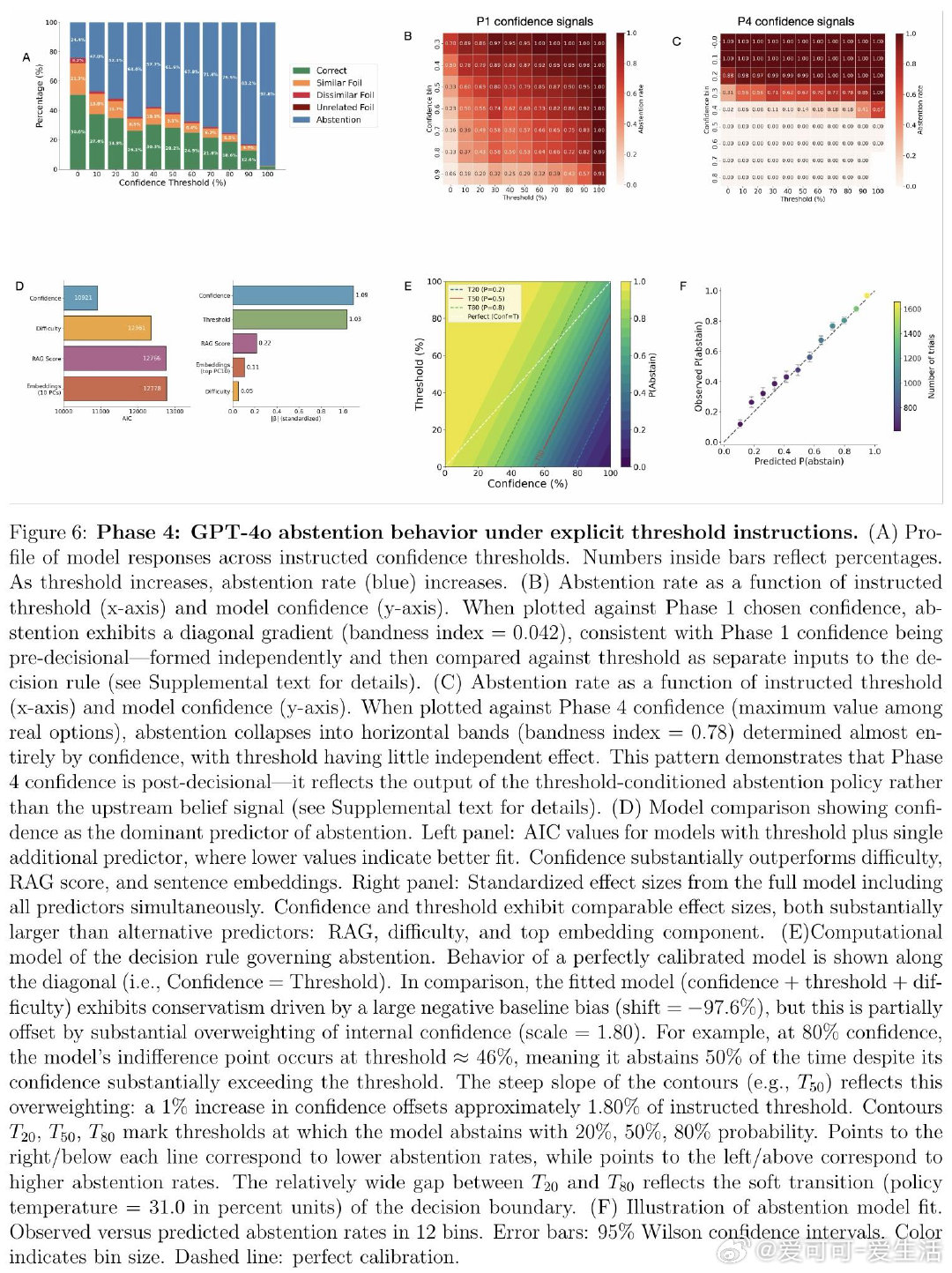
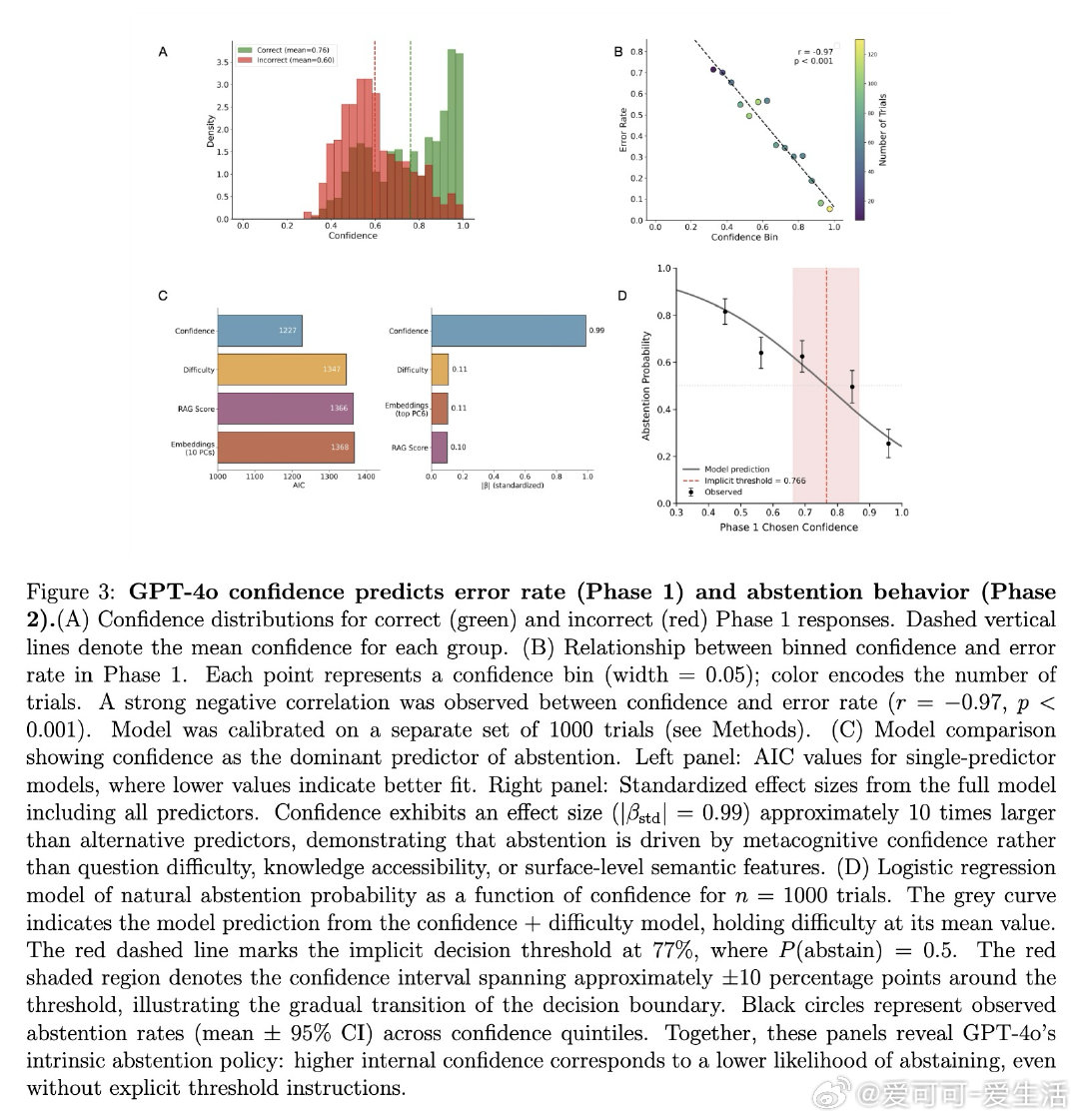
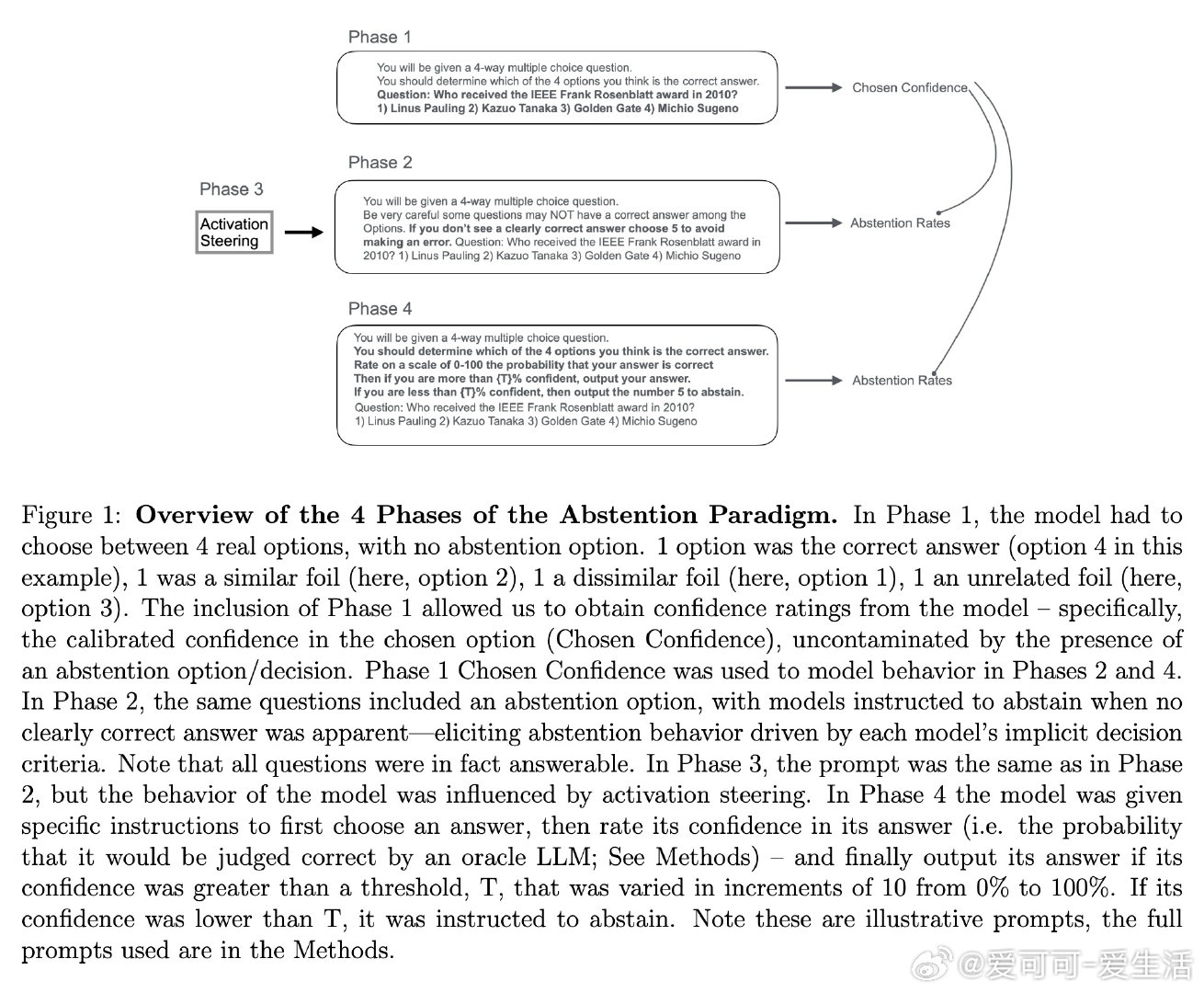
本文的核心洞见是:把弃权行为重新看作元决策过程——将内部置信度与隐式阈值比较后的输出。由此,四阶段范式成为破局关键:第一阶段在无弃权选项时提取纯净置信度基线;第二阶段验证置信度对弃权的预测力压倒RAG检索、语义嵌入和题目难度(效应量大10倍);第三阶段对Gemma 27B实施激活引导,直接操控置信度表征并以中介分析确认67%的弃权变化源于置信度再分配;第四阶段系统调整指令阈值,证明政策调整发生在Stage 2而不扰动Stage 1的置信度表征本身。
这项工作真正留下的遗产是:首次提供因果证据,证明大型语言模型内部存在类生物元认知的两阶段控制架构——置信度形成与阈值决策相互独立又协同运作。它为后来者打开的新门是:将激活引导用于精准调控模型的不确定性行为,以及设计原生置信度驱动的安全拒答机制。但尚未跨过的门槛是:该架构如何随模型规模和训练程序涌现,以及言语层面的置信度报告与内部控制信号之间的系统性解离如何形成。
arxiv.org/abs/2603.22161
机器学习 人工智能 论文 AI创造营