[LG]《Does This Gradient Spark Joy?》I Osband [Google DeepMind] (2026)
在强化学习训练中,反向传播对每个样本一视同仁——无论它是突破性发现还是无意义重复,都耗费相同算力。而反向传播的代价通常是前向传播的数倍,绝大多数样本对策略改进几乎毫无贡献,算力就此白白流失。
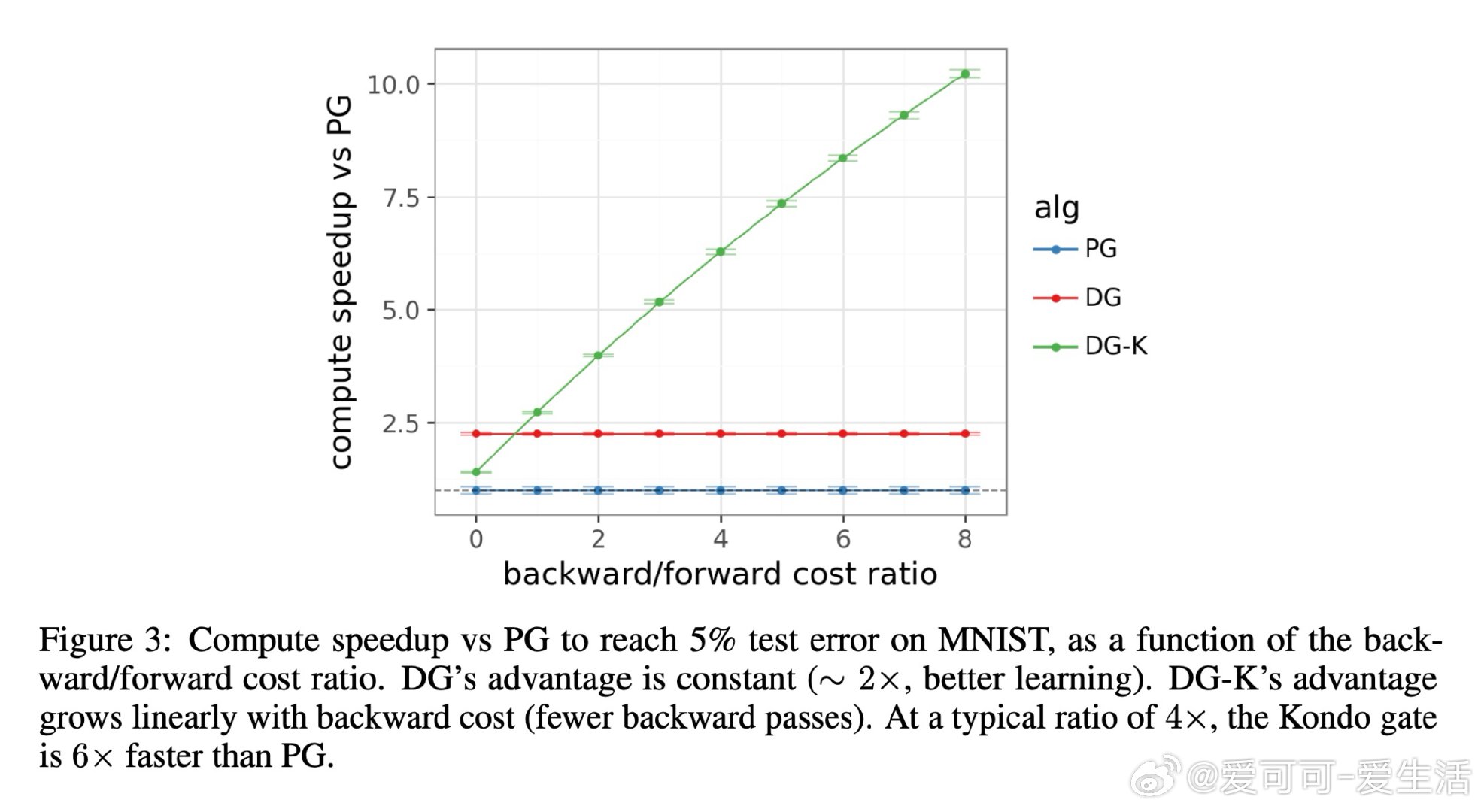
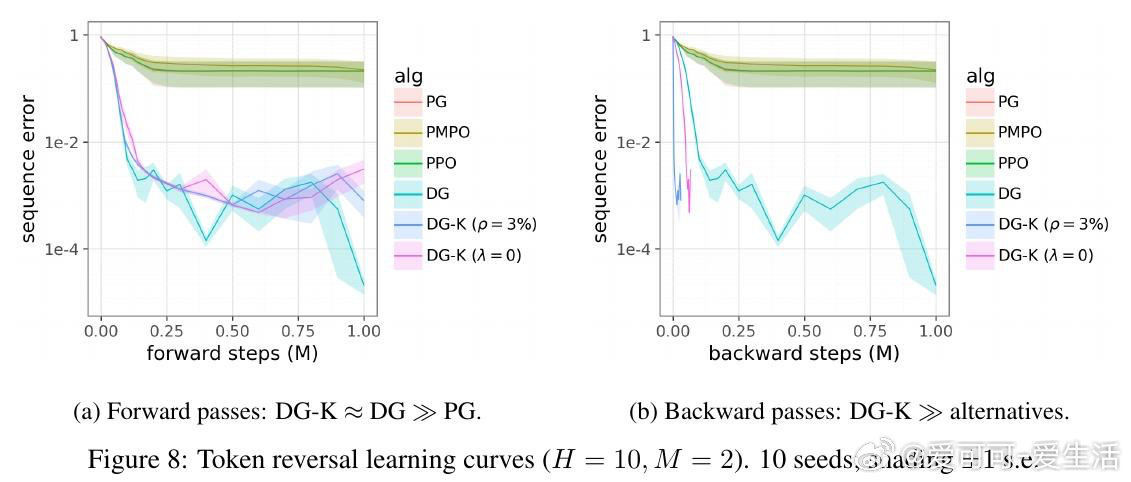
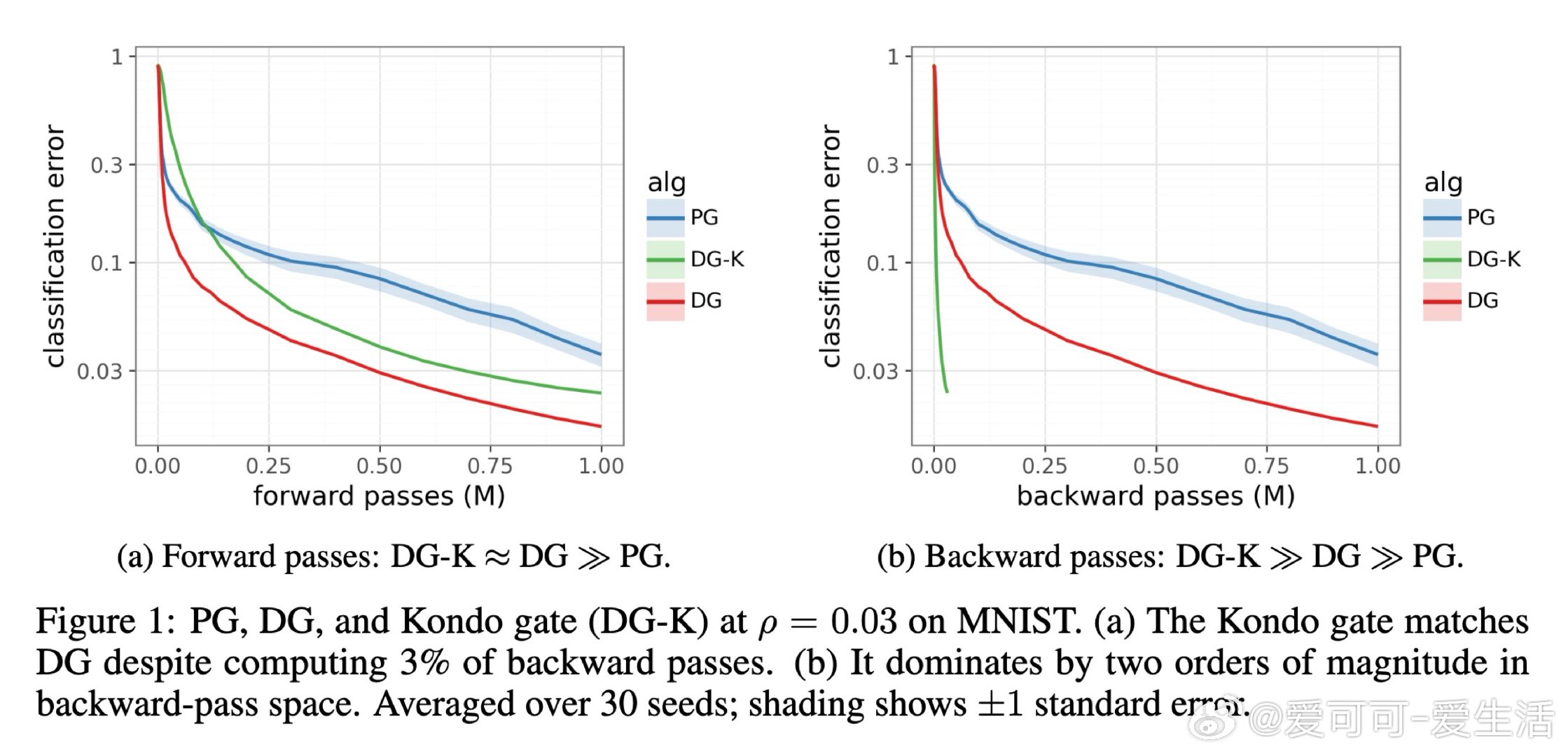
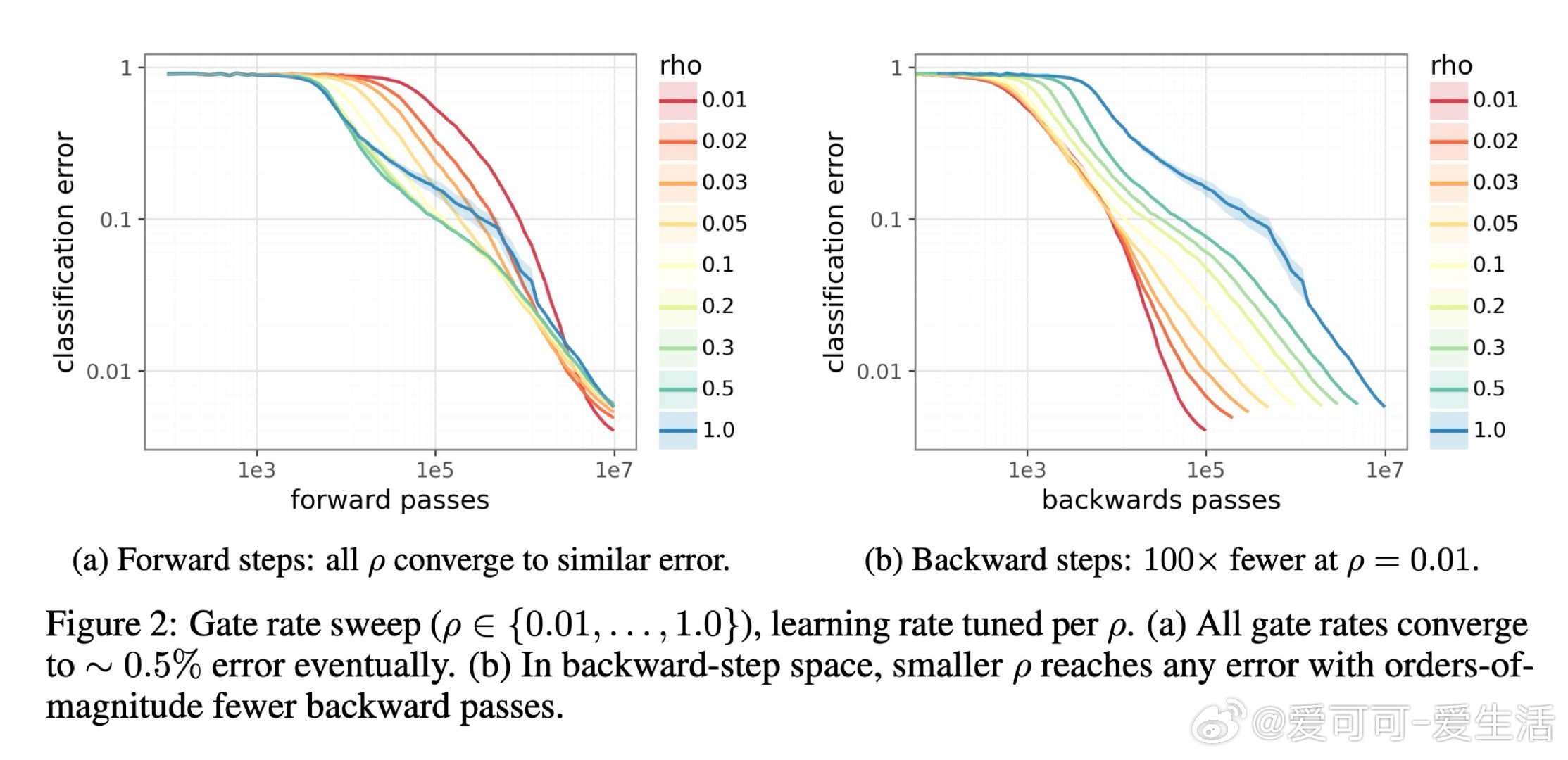
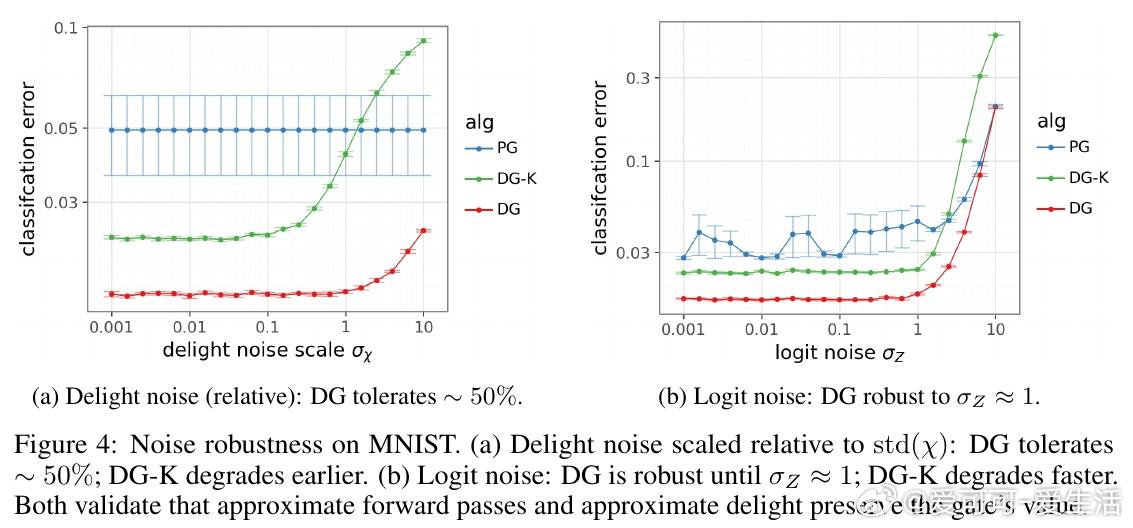
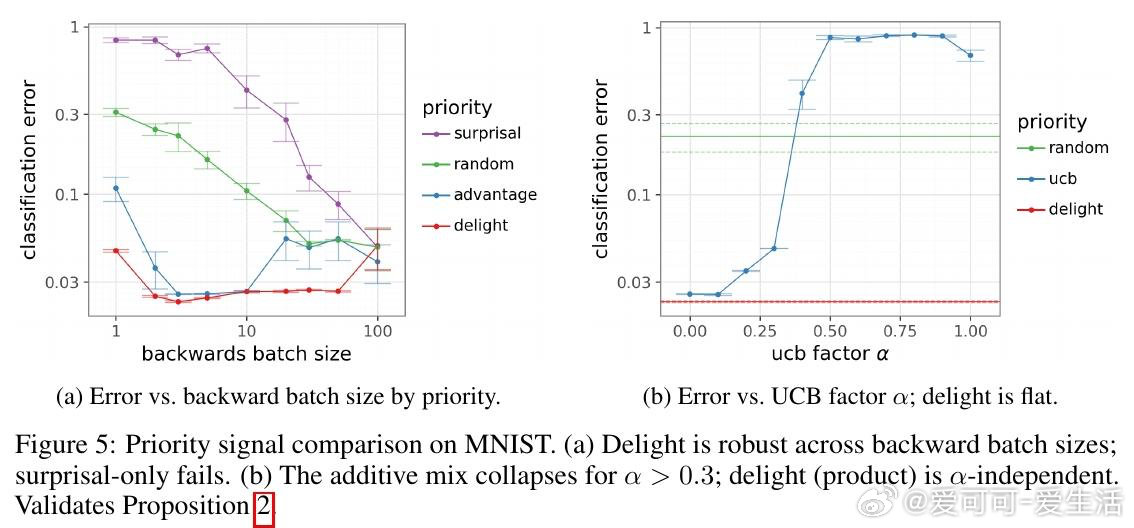
本文的核心洞见是:把"是否值得反向传播"重新看作一个可在前向传播阶段做出的决策。关键在于"喜悦度"这一信号——优势值与惊讶度的乘积,仅凭前向传播即可获得。由此,Kondo门将喜悦度与一个算力价格比较,只对值得学习的样本触发反向传播,在学习质量与计算成本之间划出一条帕累托前沿。
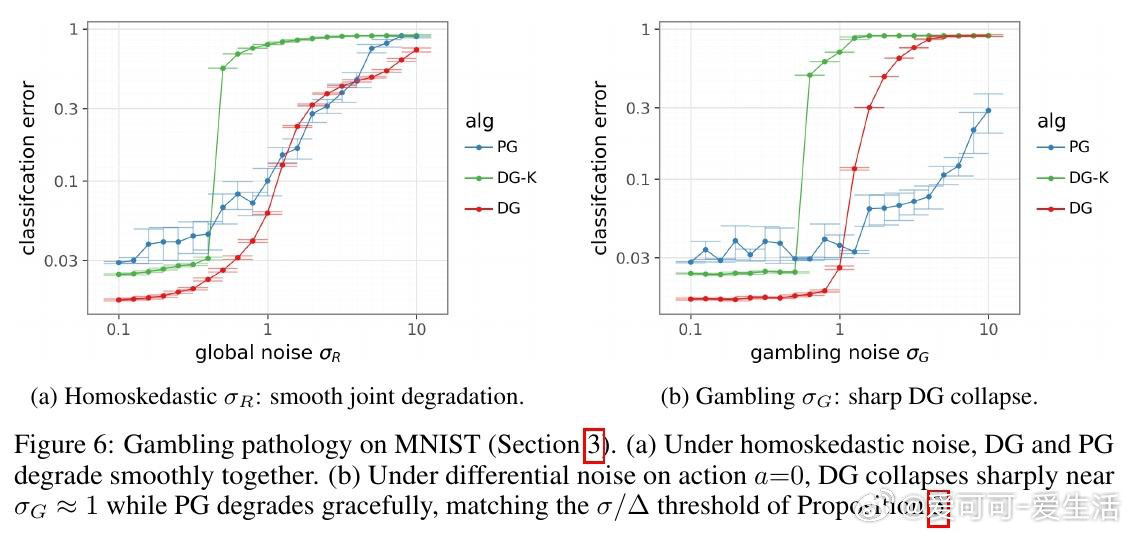
这项工作真正留下的遗产是:训练中的反向传播本身可以成为被调度的稀缺资源,而非默认的全量操作——这为"用廉价前向筛查替代昂贵反向计算"的训练范式打开了新门。但尚未跨过的门槛是:当某个次优动作的奖励方差极高时,偶然的幸运抽样会伪装成真正的突破,令喜悦度失去判别力;且该机制能否在现代大模型规模下保持优势,仍是未解之问。
arxiv.org/abs/2603.20526
机器学习 人工智能 论文 AI创造营