[CL]《Measuring Reasoning Trace Legibility: Can Those Who Understand Teach?》D Roytburg, S Sridhar, D Ippolito [CMU] (2026)
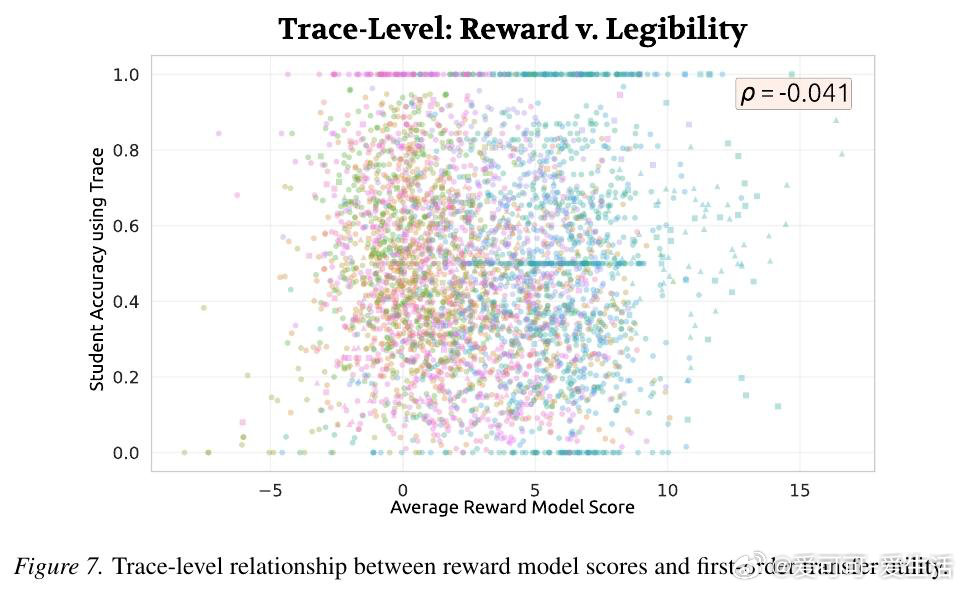
高准确率的推理模型,其思维链对弱模型而言往往是一本天书——读得懂,却学不会。现有框架将推理痕迹视为通往正确答案的副产品加以压缩,却忽视了一个悬而未决的问题:当强模型的推理过程需要被弱模型或人类验证、复用时,那些"高效"的思维链反而成为理解的障碍。
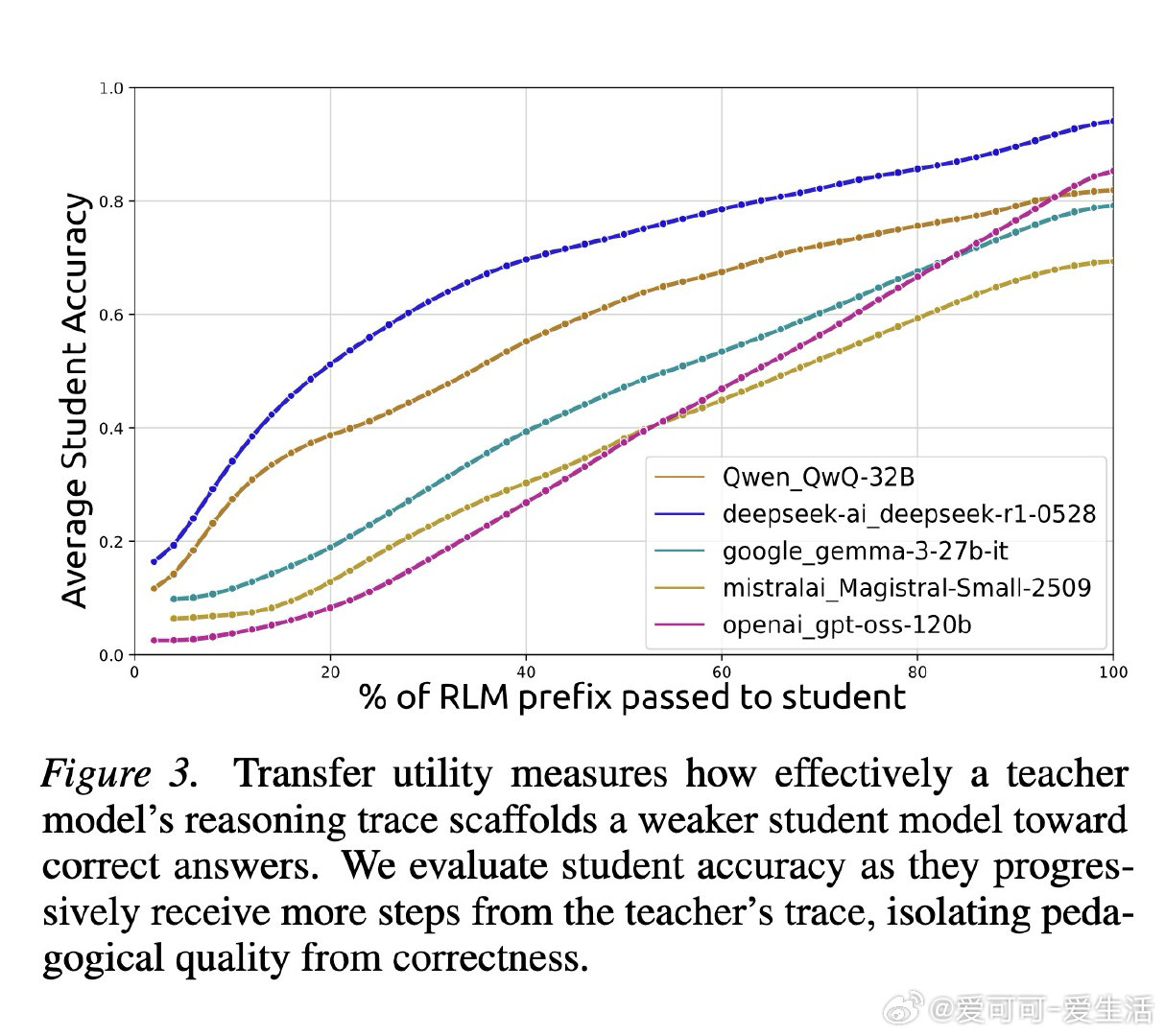
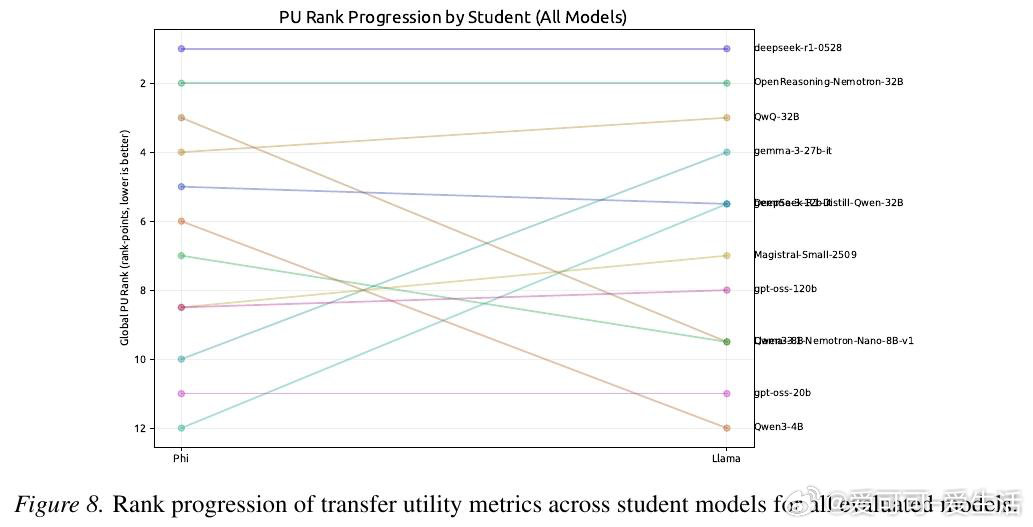
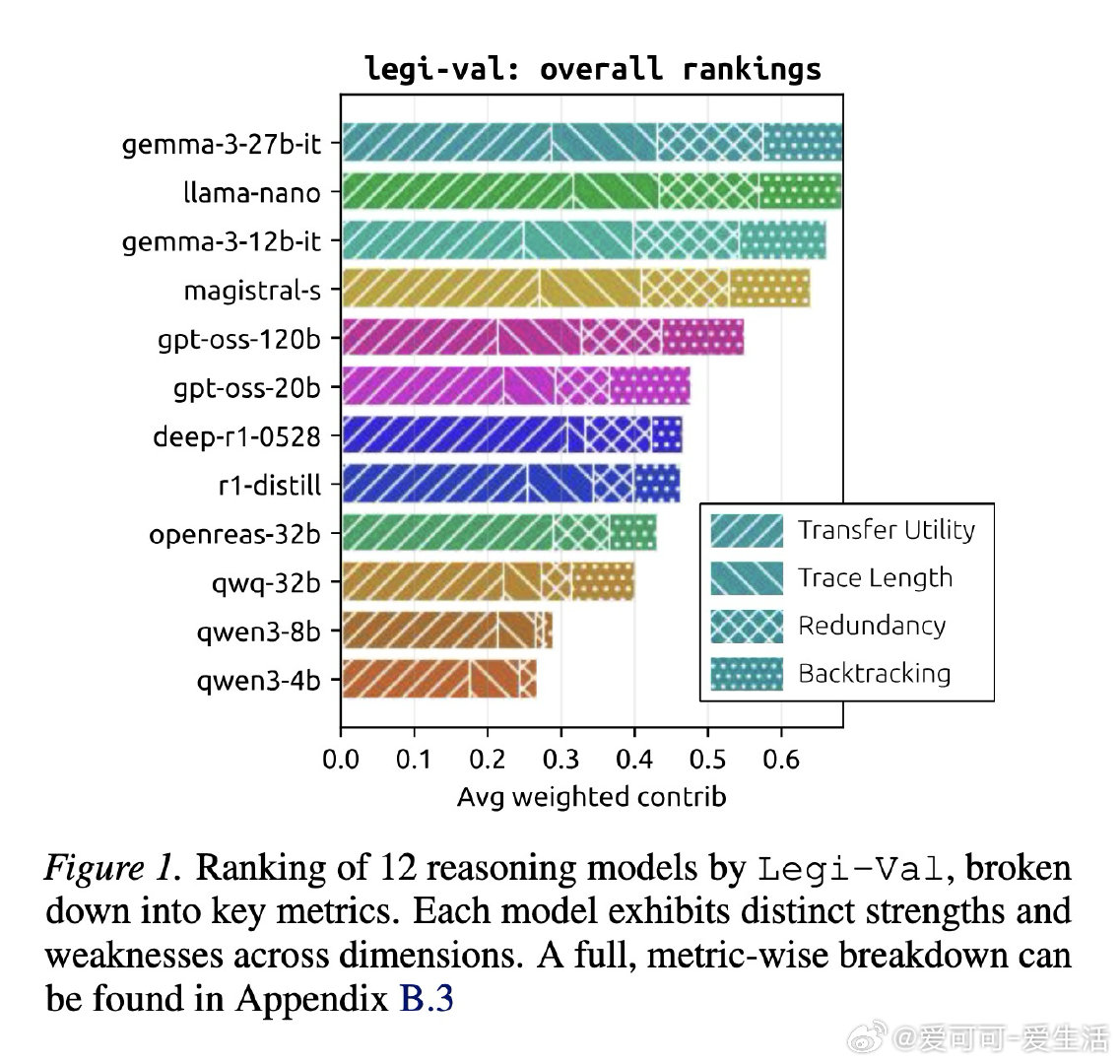
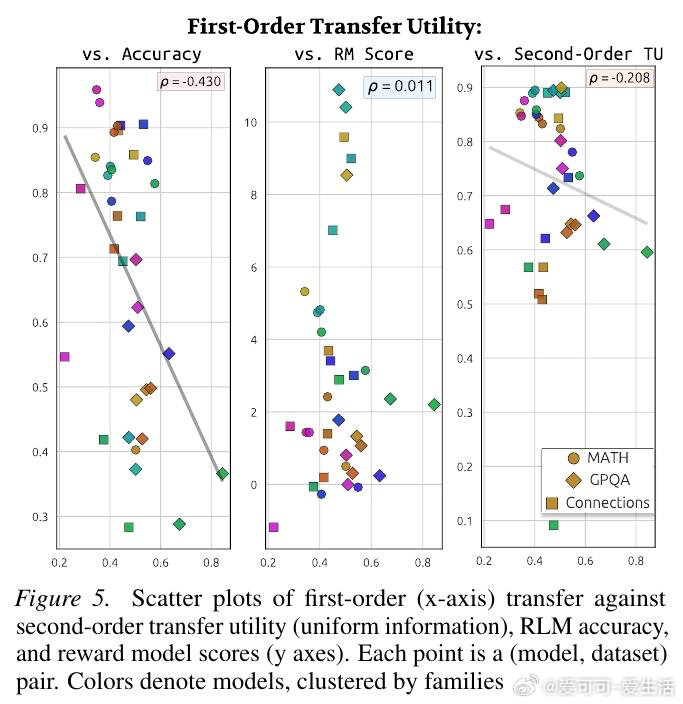
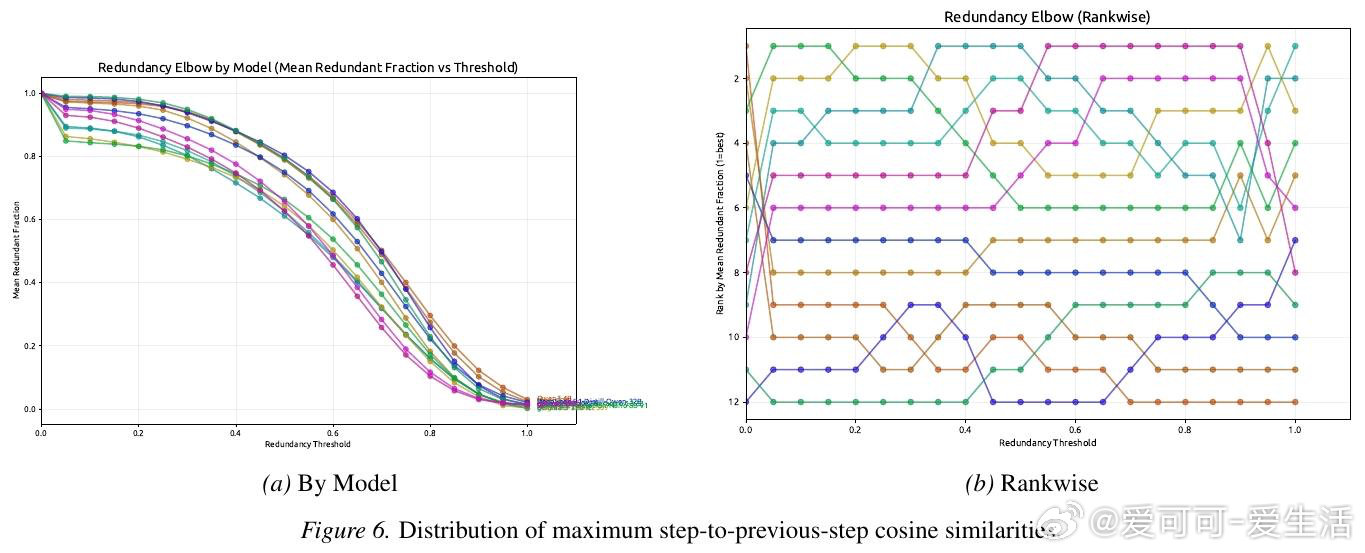
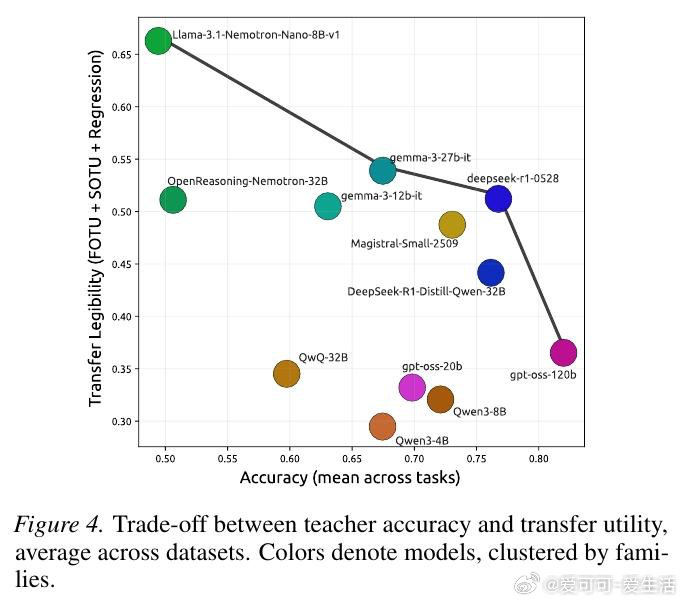
本文的核心洞见是:把"推理痕迹能否被教会"重新看作一个独立的可量化目标。由此,"迁移效用"这一操作应运而生——让弱模型逐步接收强模型推理链的前缀,以弱模型答题准确率随步数的变化曲线,衡量推理链的可教性而非仅衡量其简洁程度。跨12个模型、近10万条痕迹的实验揭示:准确率最高的模型(82%)在迁移效用上排名倒数第二,而准确率最低的模型反而教学效果最佳。
这项工作真正留下的遗产是:首次将推理痕迹的"可传授性"与"高效性"解耦,证明二者构成一条帕累托前沿,并提供了将其纳入强化学习奖励信号的具体度量目标。它为后来者打开的新门是:在多智能体系统中,以迁移效用作为奖励信号训练"可监督的"推理模型。但尚未跨过的门槛是:迁移效用的在线蒸馏验证、跨任务的可泛化奖励设计,以及与真实人类认知负荷的直接对齐。
arxiv.org/abs/2603.20508
机器学习 人工智能 论文 AI创造营