[LG]《PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost》J Yi, D Mosk-Aoyama, B Huang, R Gala… [NVIDIA & UC Berkeley] (2026)
在Agent智能体的后训练领域,如何用有限算力同时保住域内准确率与域外泛化能力,是一个两难困境。SFT计算高效,却会灾难性遗忘——终端域训练后,数学基准AIME25从86分骤跌至21分;E2E RL泛化稳健,却要为每次参数更新付出完整多轮环境交互的沉重代价。
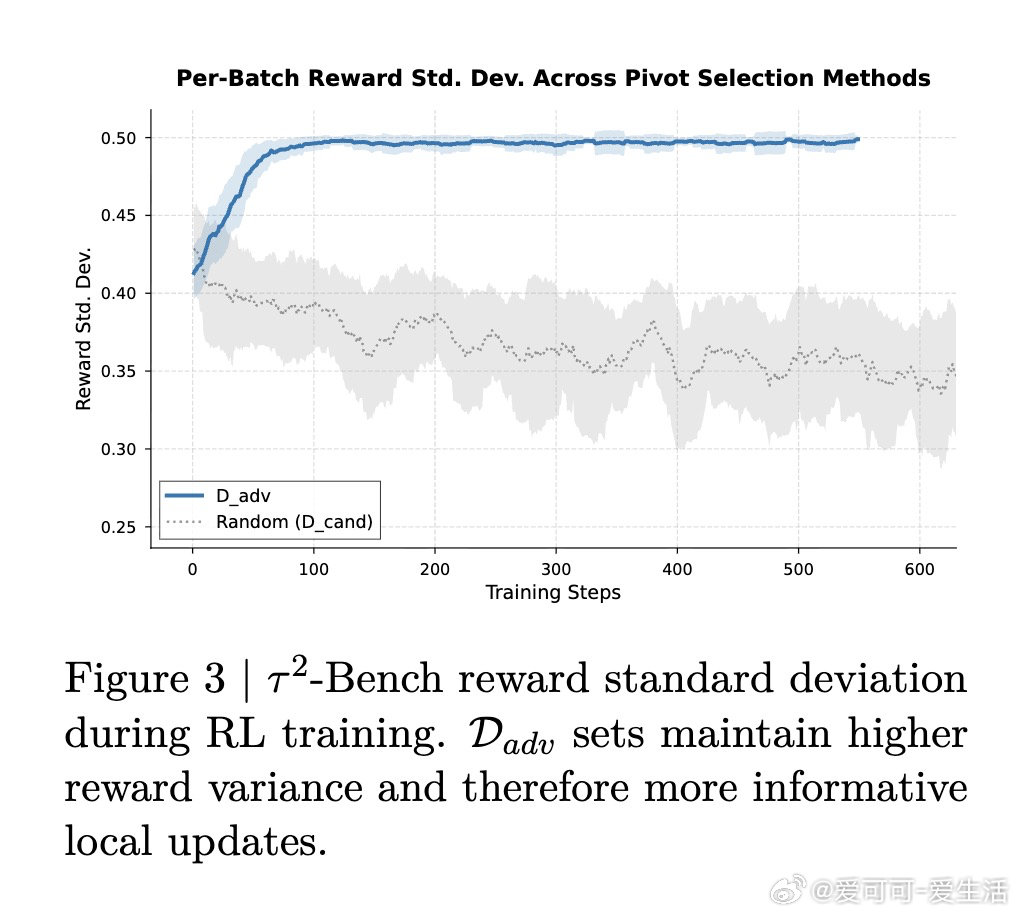
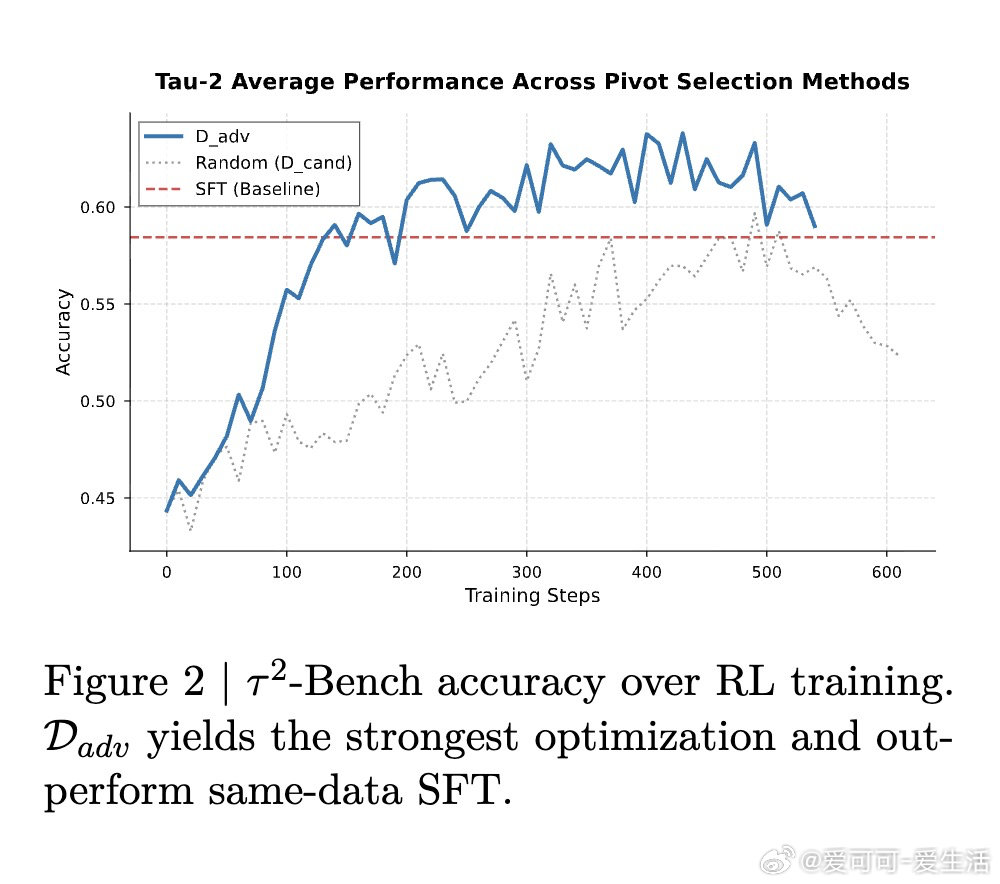
本文的核心洞见是:把SFT轨迹中"当前策略成败参半"的关键转折点单独挑出,作为局部强化学习的训练锚点。由此,两个操作使问题得以解开:其一是离线筛选"枢轴转折点"——仅在奖励方差非零的中间步骤上展开单步rollout,避免在已解决或完全失败的步骤上浪费算力;其二是用功能等价验证器替代严格字符串匹配,令任何局部可接受的动作都能获得奖励,从而保留参考策略在任务无关动作上的相对排序。
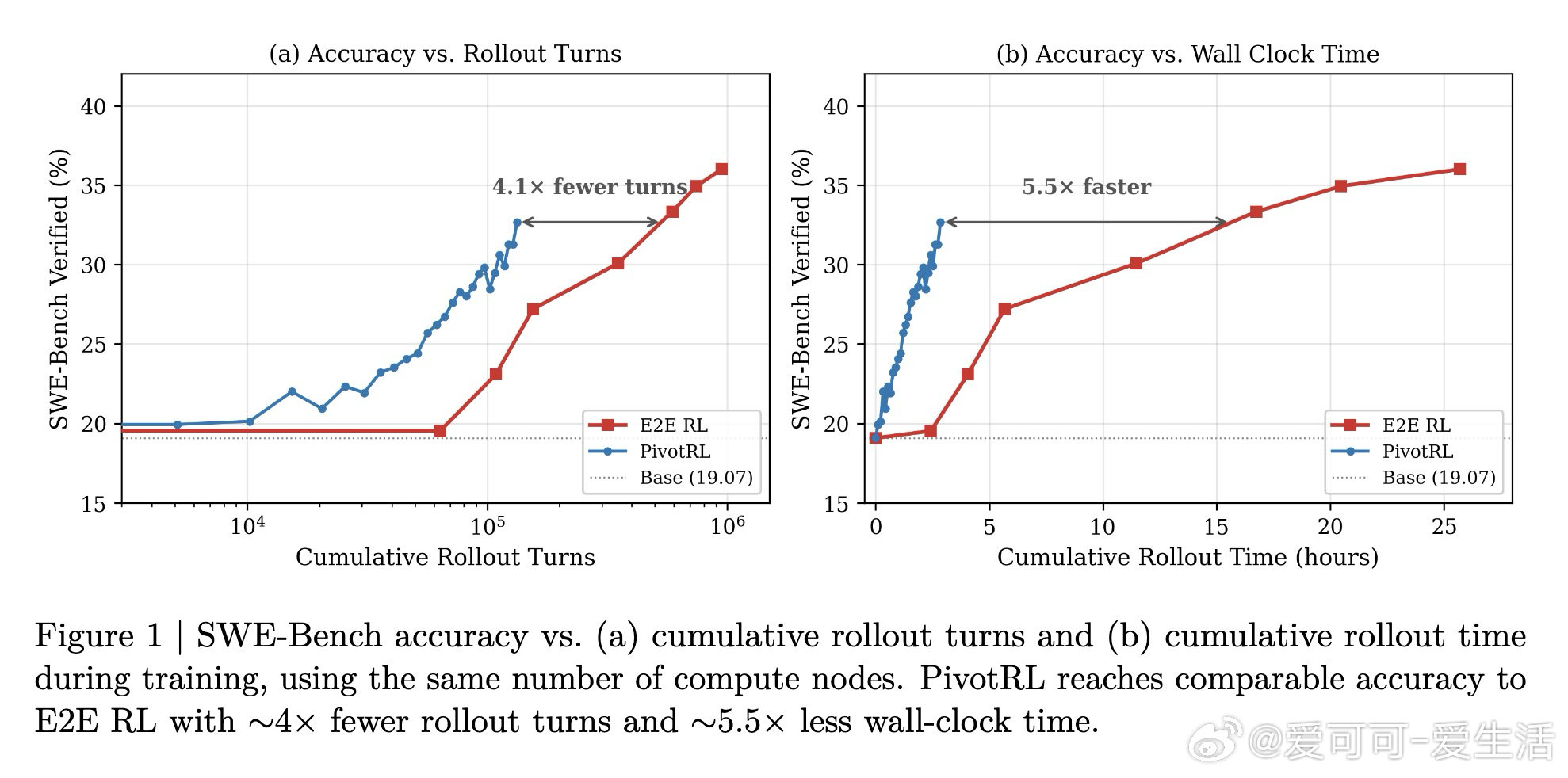
这项工作真正留下的遗产是:证明了在不触碰完整轨迹的前提下,可以用SFT的数据开销换取接近E2E RL的泛化收益——在SWE-Bench上以4倍更少的rollout步数达到相当准确率,且域外性能几乎零损耗。它为后来者打开的新门是:将现有离线演示数据直接转化为在线RL信号的系统性方法论。但尚未跨过的门槛是:当前依赖可程序化验证器,对缺乏明确局部正确性判据的任务(如开放式写作、复杂推理链中间步)尚无成熟的扩展方案。
arxiv.org/abs/2603.21383
机器学习 人工智能 论文 AI创造营