“核弹”!2.87倍!华为用一颗芯片,终结了美国对算力的统治!
过去很长一段时间里,全球高端 AI 算力芯片的核心技术与供应话语权,几乎全被美国企业攥在手里,国内 AI 产业的发展,始终绕不开 “缺芯少算” 的卡脖子困境。
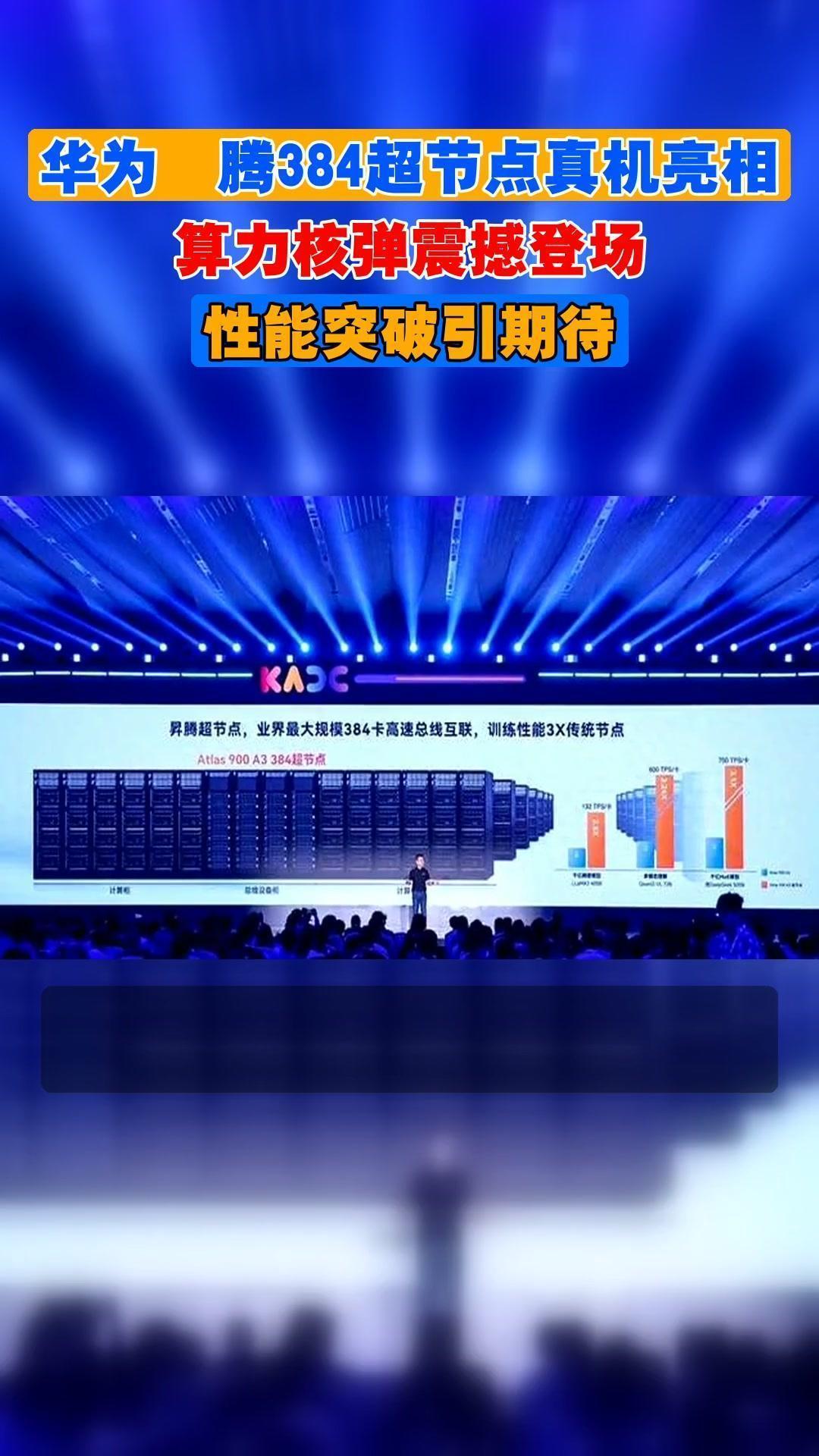
2026 年 3 月 22 日,在深圳坂田举办的华为中国合作伙伴大会上,华为昇腾计算业务总裁张迪煊,正式发布了全新的 AI 算力产品,给整个行业带来了颠覆性的改变。
这次亮相的 Atlas 350 AI 训练推理加速卡,核心搭载的是华为 2026 年第一季度全新推出的昇腾 950PR 芯片,单从产品定位来看,这张加速卡就覆盖了 AI 产业最核心的两大需求 —— 训练与推理。
用大白话讲,训练就是给 AI 大模型 “上课教学”,让它学会海量的知识与能力;推理就是 AI 学成之后,给用户提供实时的服务响应,我们每次向 AI 工具发出指令、拿到结果,背后都是推理算力在支撑。一张卡就能同时搞定两大核心场景,实用性直接拉满。
在 AI 应用最广泛的 FP4 低精度推理场景下,这款芯片的单卡算力达到了 1.56PFlops。
可能很多人对这个单位没概念,简单说,1PFlops 代表每秒能完成 1 千万亿次浮点运算,1.56PFlops 的算力,意味着这张芯片一秒钟能完成的运算量,换成普通家用电脑,可能要连续运算好几个月才能完成。
更关键的是,第三方机构的实测数据显示,在同等测试环境下,这款芯片的推理性能,达到了英伟达 H20 芯片的 2.87 倍。
这个近 3 倍的性能差距,从来都不是简单的数字游戏,而是真真切切能改变整个行业格局的硬实力。
举个最实际的例子,想要搭建一个能支撑商用大模型稳定运行的算力集群,之前用行业主流的海外芯片,需要近 300 张卡才能扛住的运算压力,现在用这款华为的芯片,100 张就能完全搞定。
不光前期的硬件采购成本直接砍掉了三分之二,后续的机房占地、电力消耗、运维管理的长期成本,也会跟着大幅下降。更重要的是,这不是靠堆料、超频挤出来的一点点性能提升,而是从芯片底层架构实现的跨越式突破,直接把全球 AI 算力的行业标准拉高了一个层级。
过去十年,全球高端 AI 算力市场,一直处于美国企业的绝对垄断状态。他们不仅手握最先进的芯片设计与制造技术,还通过出口管制、技术封锁、产品规格阉割等各种手段,给其他国家的 AI 产业发展设下了层层壁垒。
就拿国内市场来说,前些年很多 AI 企业想要采购高端算力芯片,不仅要付出远超海外市场的高价,还随时要面对断供、限售的风险,就算顺利拿到货,很多也是被刻意限制了性能的版本,根本没法放开手脚用于大模型的研发与落地。
不少有创意、有潜力的 AI 创新项目,最终都因为算力缺口太大、算力成本太高,只能被迫搁置。
而华为这次带来的这款芯片,最核心的价值,从来都不只是纸面性能上的超越,而是彻底撕开了持续十年的算力垄断壁垒。
这款芯片从底层架构设计,到配套的软件生态适配,再到全流程的生产供应链,全都是华为自主研发完成的,完全不依赖海外的技术与供应体系,也就不会被任何外部的限制政策卡脖子。
国内的 AI 企业,终于有了一款性能够强、供应稳定、成本可控的自主算力选择,不用再看着别人的脸色谋发展。
这种算力层面的核心突破,最终惠及的绝不只是科技企业,还有我们每一个普通人。
算力的成本降下来了,AI 技术的落地门槛就会跟着大幅降低,以后不管是能帮我们更早发现健康风险的智能医疗,还是能让出行更安全的自动驾驶,甚至是日常用的各类智能生活服务,都会以更快的速度普及,用更低的成本给我们的生活带来实实在在的便利。
就连很多中小创业团队,也能用上之前只有头部大厂才负担得起的高性能算力,做出更多有创意、有价值的 AI 产品,给整个行业注入更多的活力。
其实这些年,国内科技企业在核心技术领域的每一次突破,从来都不是偶然的运气,而是日复一日、年复一年在研发上的持续投入,一步一个脚印走出来的结果。
从通信技术到芯片设计,从操作系统到算力生态,正是这种咬定自主创新不放松的韧劲,才让我们一次又一次打破了海外的技术封锁。这次的算力突破,也不是国产科技发展的终点,而是国内 AI 产业全面自主、全速发展的全新起点。
对于这次国产算力芯片的跨越式突破,你觉得它会给我们的日常生活和整个 AI 行业,带来哪些意想不到的改变?欢迎在评论区留下你的看法。