[CV]《Efficient Universal Perception Encoder》C Zhu, S Suri, C Jose, M Oquab… [Meta Reality Labs & FAIR at Meta] (2026)
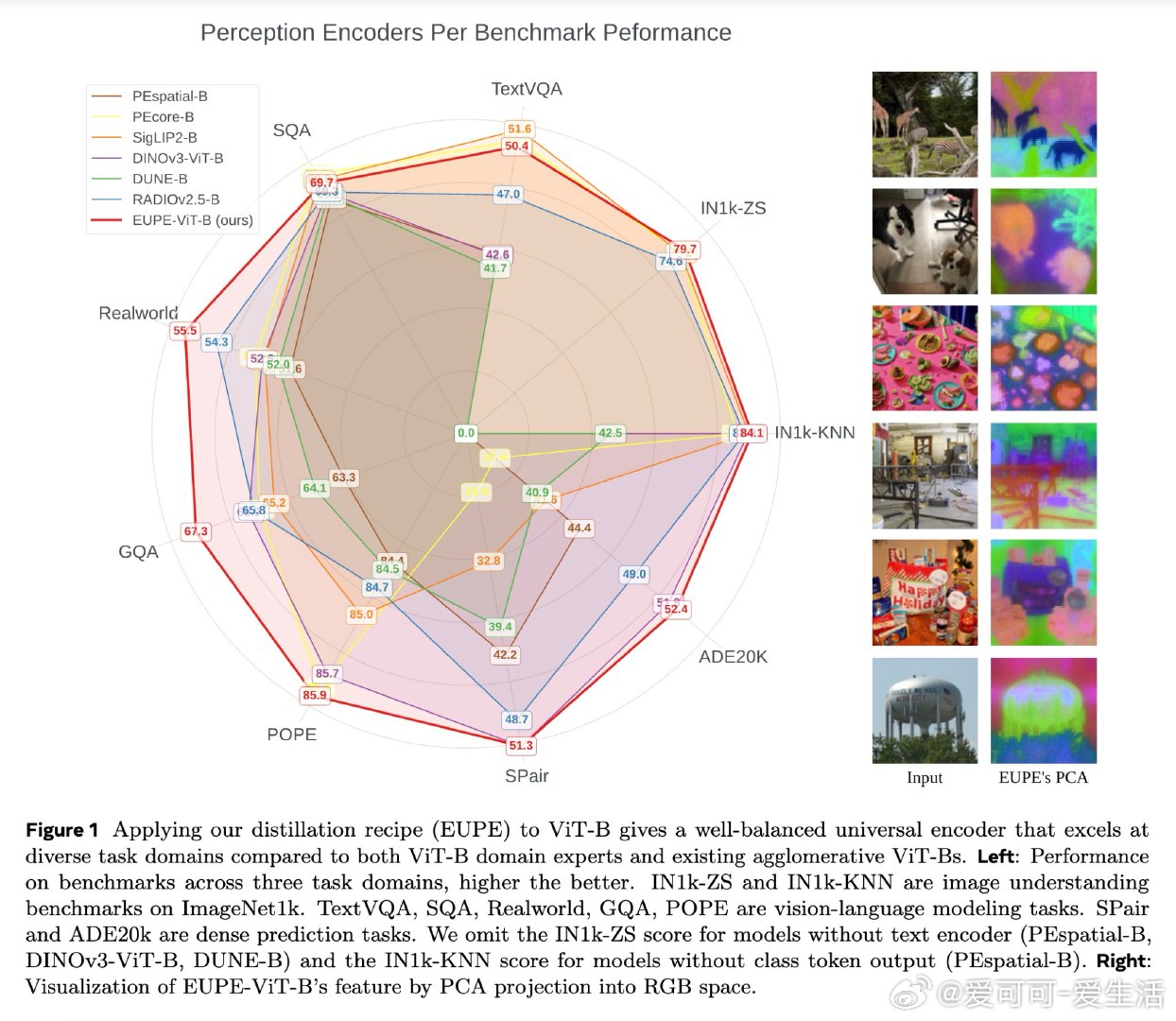
在边缘设备视觉感知领域,单一编码器始终困于"专才陷阱":擅长语义理解的CLIP系模型空间感知差,擅长密集预测的DINO系模型语言对齐弱。直接将多个专家教师压缩进轻量编码器时,86M参数的学生根本无法同时容纳来自多个异构特征空间的表示,导致知识相互干扰。
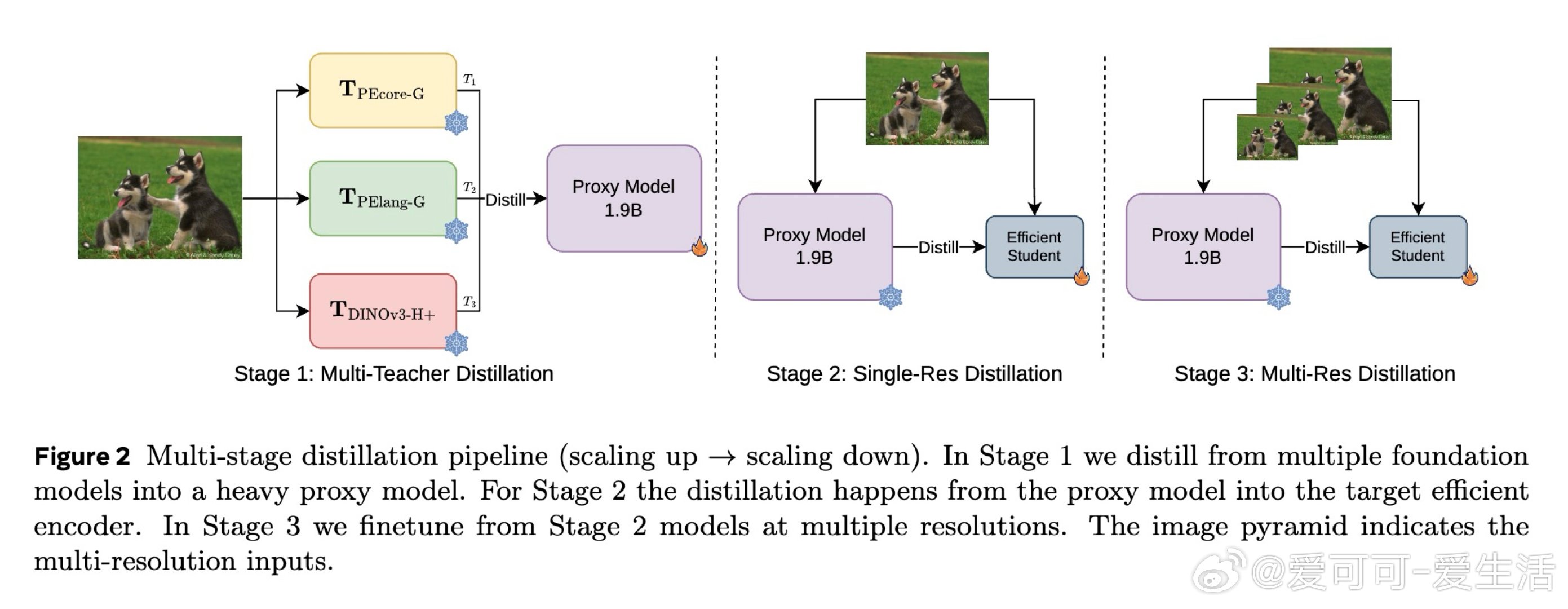
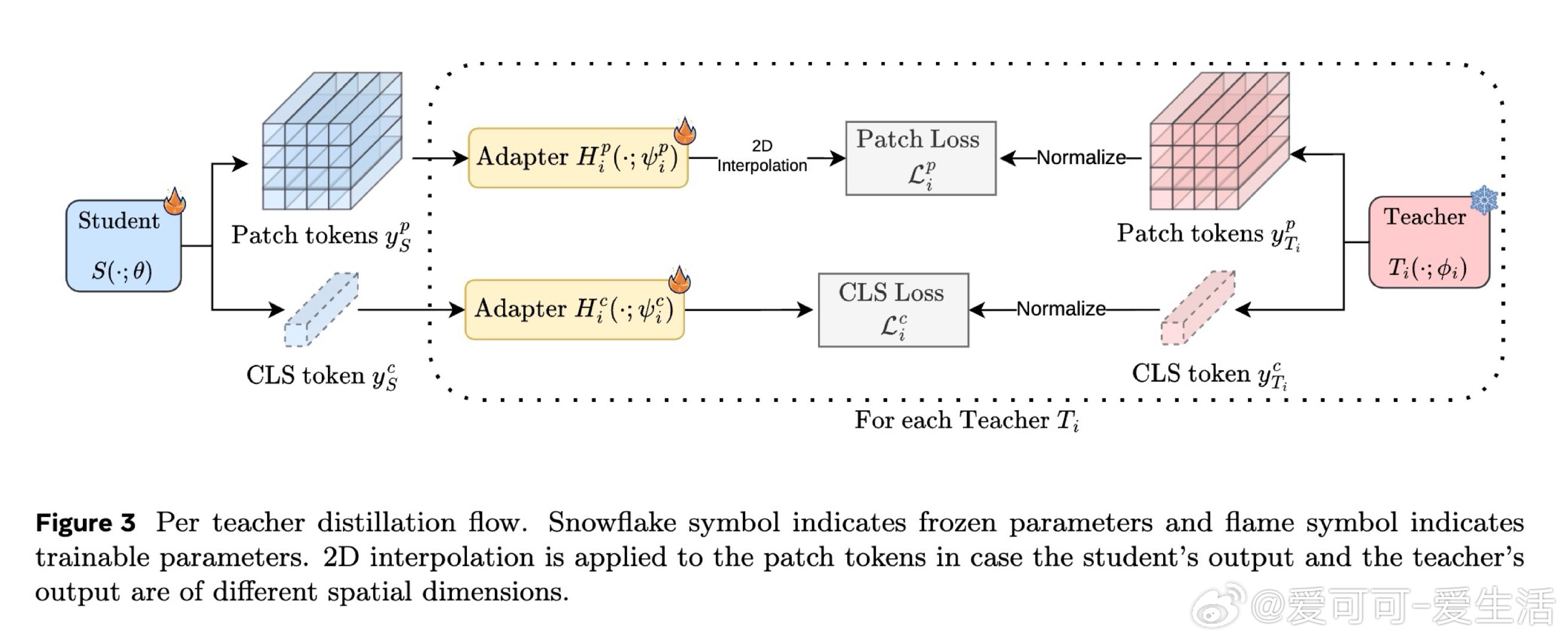
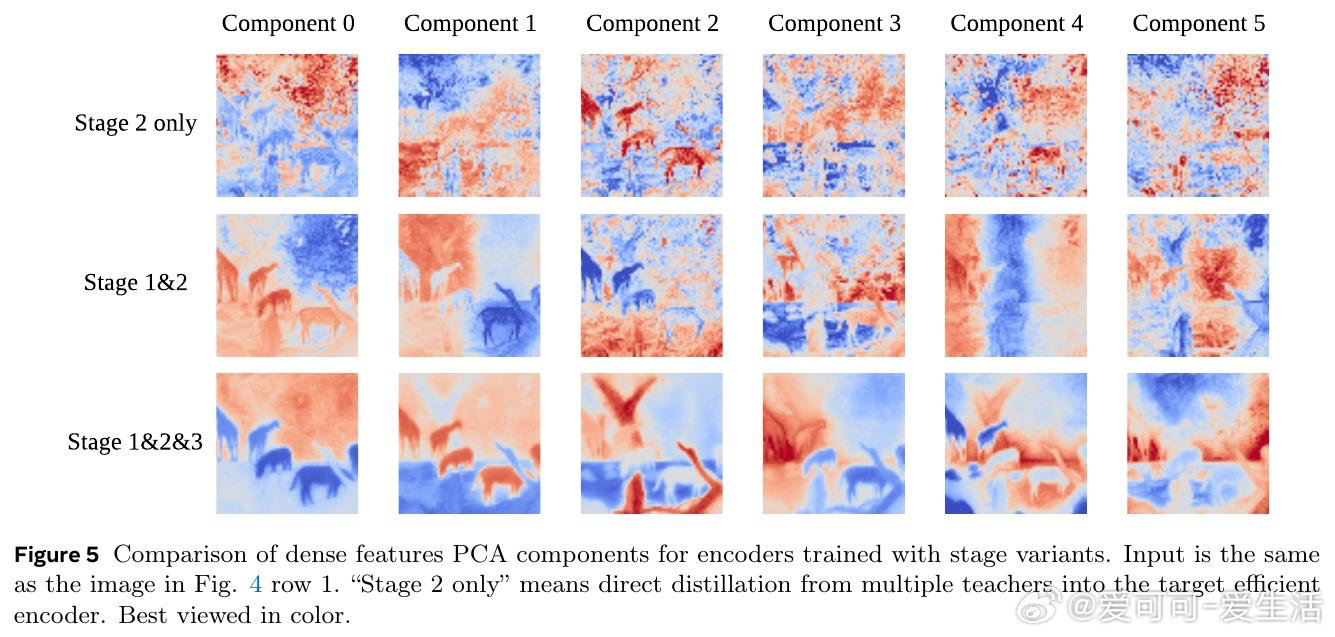
本文的核心洞见是:把"多教师→小模型"的直接压缩,重新看作"多教师→大代理→小模型"的两段式蒸馏。先用1.9B参数的代理模型将多个专家知识熔合成一个统一的通用表示,再由这个单一代理向轻量学生单向传授。这一"先扩后缩"的操作,将学生面临的问题从"如何同时学会多种语言"简化为"如何学好一种融合语言"。
这项工作真正留下的遗产是:证明了代理模型作为知识融合中间层的必要性,为边缘端通用视觉系统提供了可复现的实用基线。它为后来者打开的新门是:沿代理模型规模轴继续探索(7B实验已现曙光),以及将同一框架迁移至更多异构模态。但尚未跨过的门槛是:7B代理向86M学生蒸馏时出现的知识损耗问题——规模鸿沟越大,知识能否完整传递仍悬而未决。
arxiv.org/abs/2603.22387
机器学习 人工智能 论文 AI创造营