[LG]《Scaling Attention via Feature Sparsity》Y Xie, T Wen, T Huang, B Chen… [Xidian University] (2026)
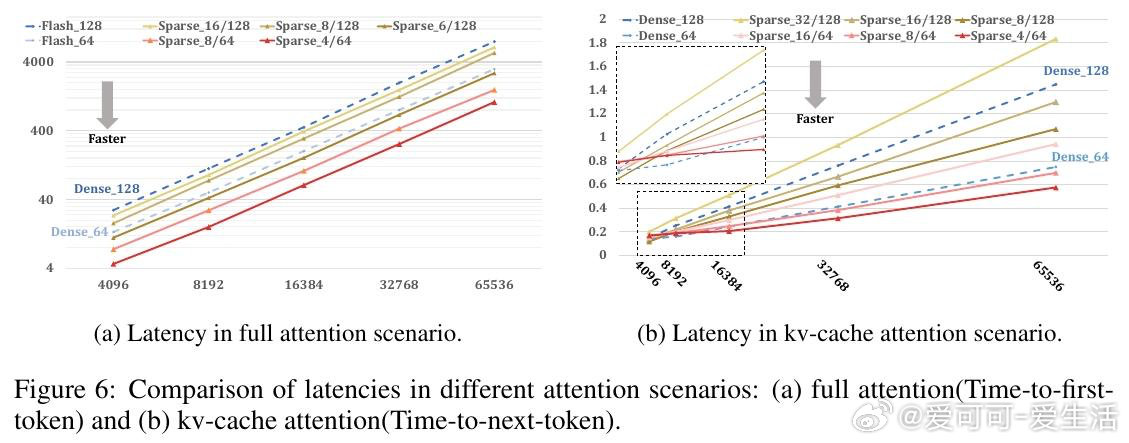
在超长上下文场景中,自注意力的计算瓶颈始终悬而未决。现有方法沿序列轴削减交互代价——窗口化、低秩近似或token剪枝——却无一例外地以精度为代价。根本困境在于:所有方案都在压缩"谁与谁交互",却从未质疑"用多少特征维度来交互"这一隐性假设。
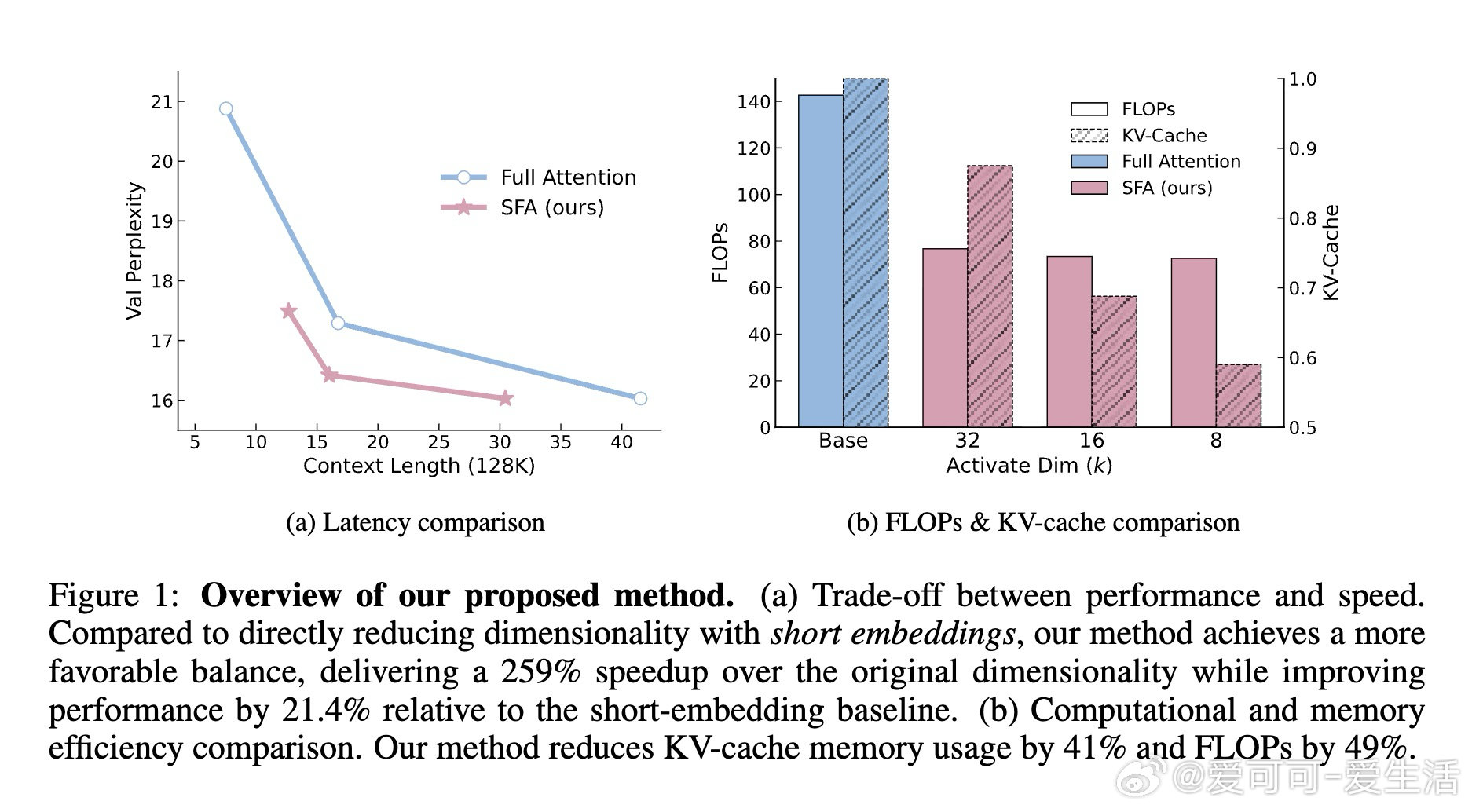
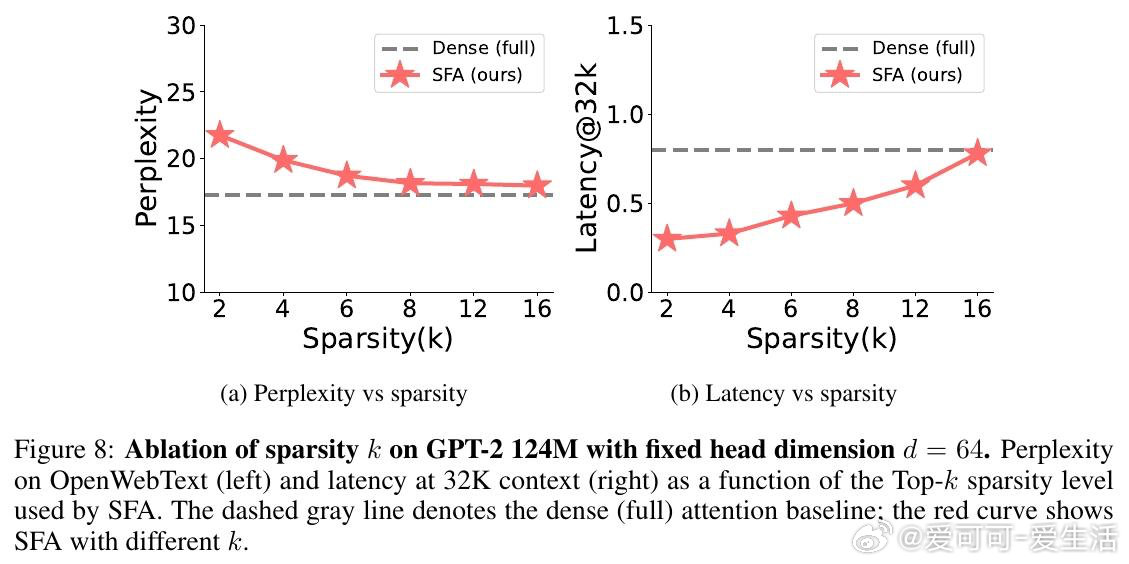
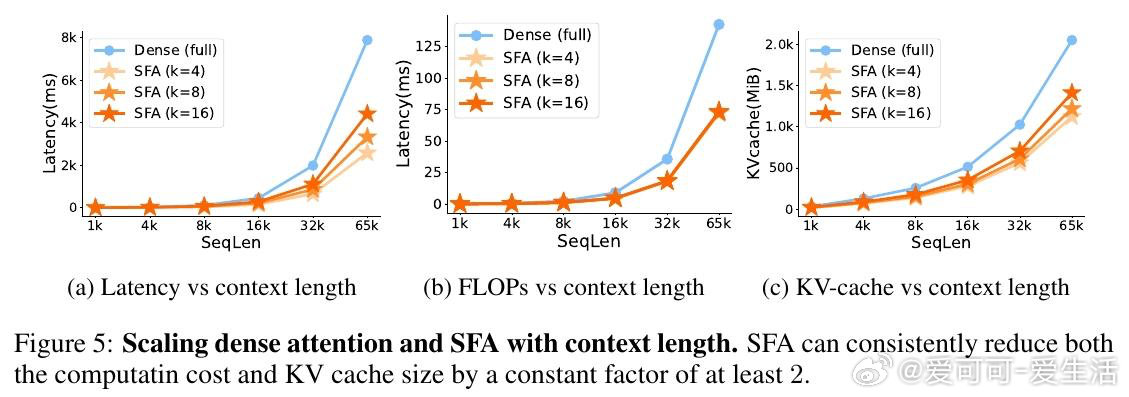
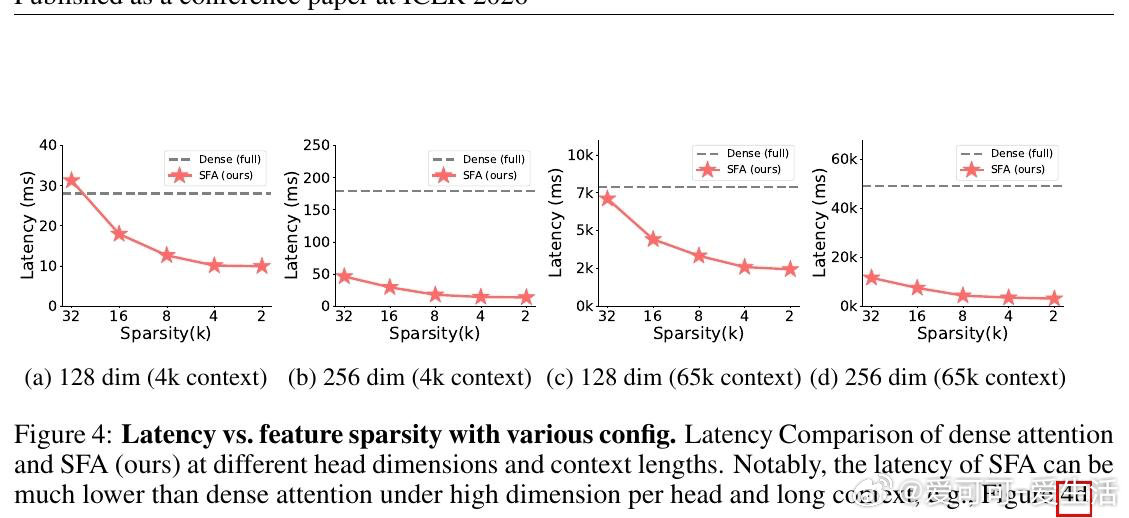
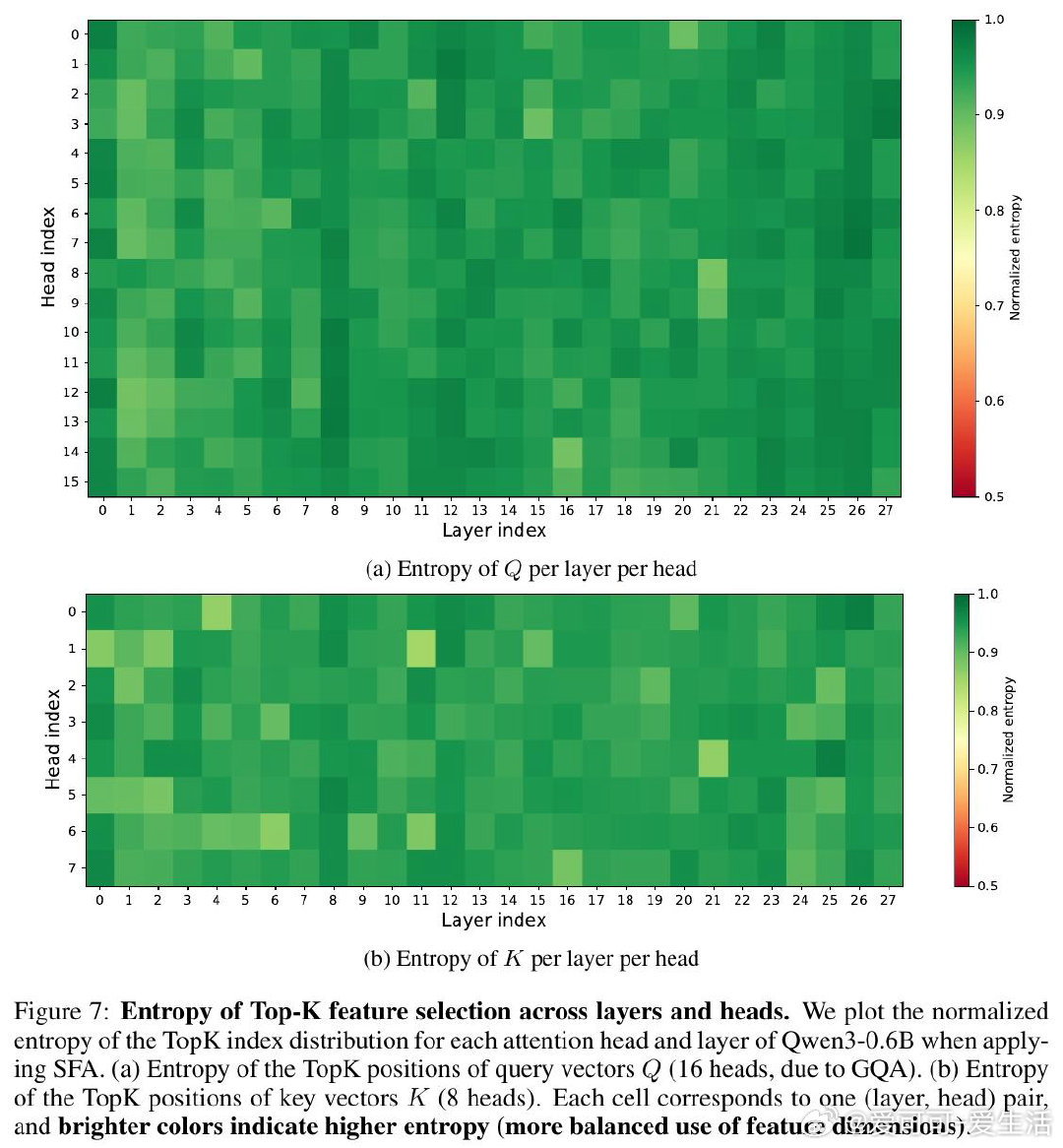
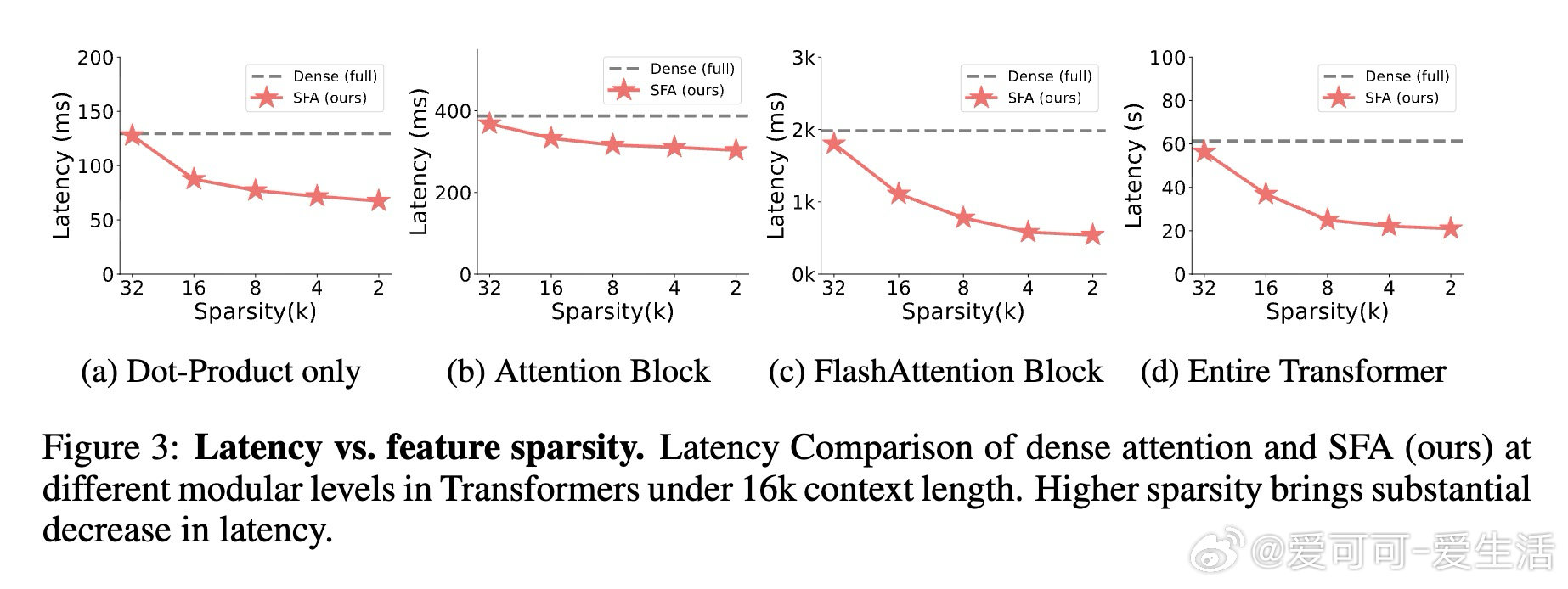
本文的核心洞见是:把注意力打分重新看作稀疏特征坐标上的集合求交问题。由此,对Query和Key各自只保留幅度最大的k个维度(Top-k稀疏化),计算量从n²d骤降至n²k²/d,且通过FlashSFA内核在分块流水线中直接处理稀疏重叠、避免具象化n×n矩阵,使数学等价性与内存效率同时成立。
这项工作真正留下的遗产是:特征轴稀疏性作为一个独立于token轴的正交加速维度首次被系统确立。它为后来者打开的新门是与token稀疏、KV压缩、量化等方法的可组合叠加空间——每种方法压缩不同轴,增益可累乘。但尚未跨过的门槛是:当前GPU硬件对稀疏张量乘积的原生支持不足,极低k值下偶发的质量退化问题,以及如何动态自适应每层最优稀疏预算,仍待解决。
arxiv.org/abs/2603.22300
机器学习 人工智能 论文 AI创造营