[LG]《Sparser, Faster, Lighter Transformer Language Models》E Cetin, S Peluchetti, E Castillo, A Naruse… [Sakana AI & NVIDIA] (2026)
大型语言模型的前馈层占据模型参数量的三分之二和八成以上的计算量,而其中大部分神经元对任意给定输入实际上处于休眠状态——这意味着理论上可以跳过大量计算。然而,GPU硬件栈深度优化于稠密矩阵运算,将稀疏索引物化与管理的开销往往抵消甚至超过节省的计算量,导致"算得少反而跑得慢"的工程悖论长期阻塞稀疏化的实用化。
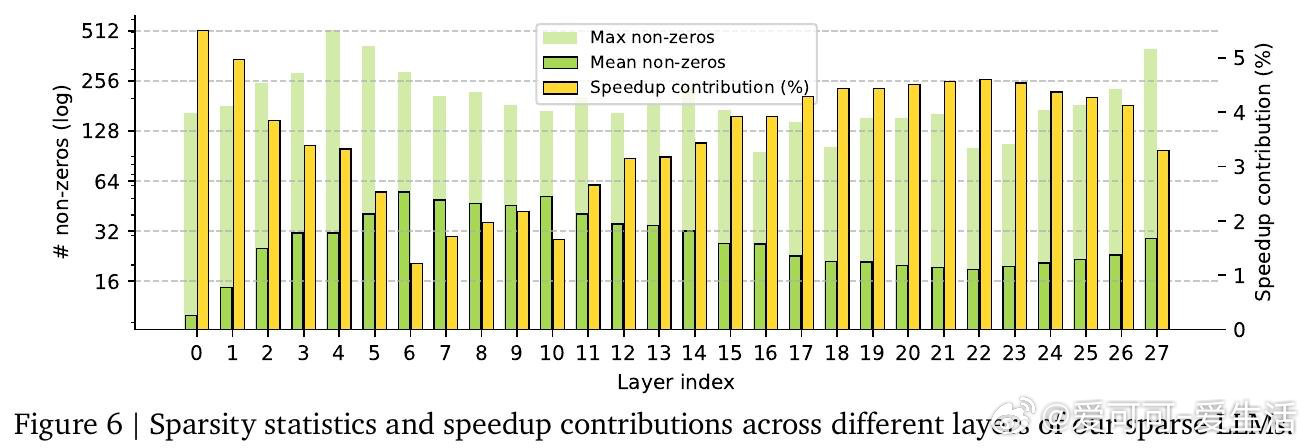
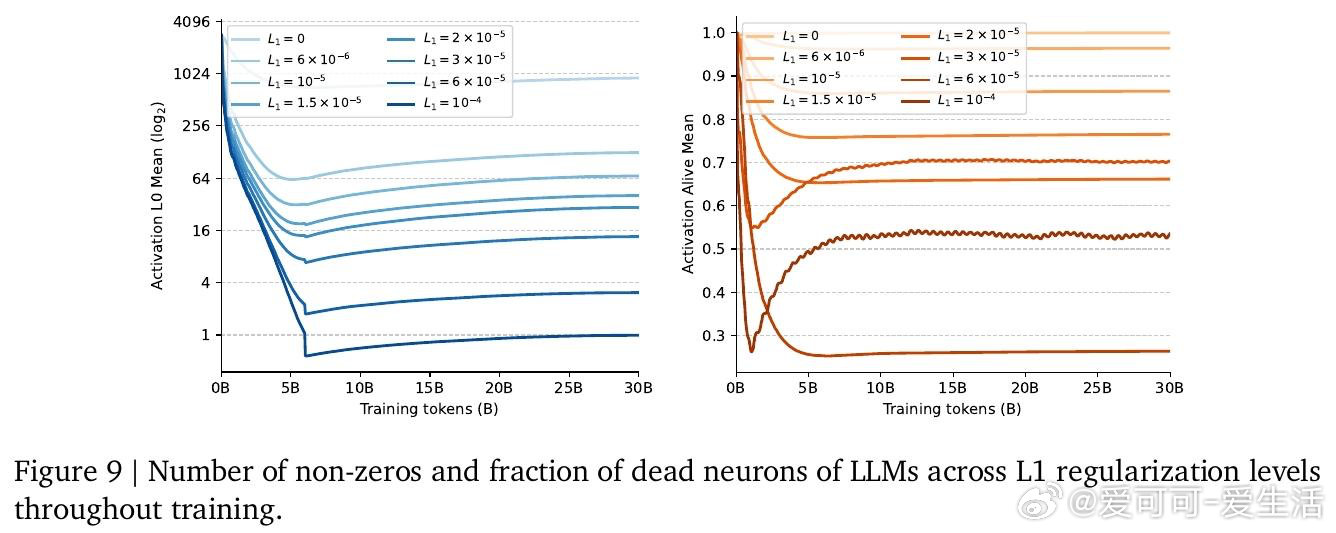
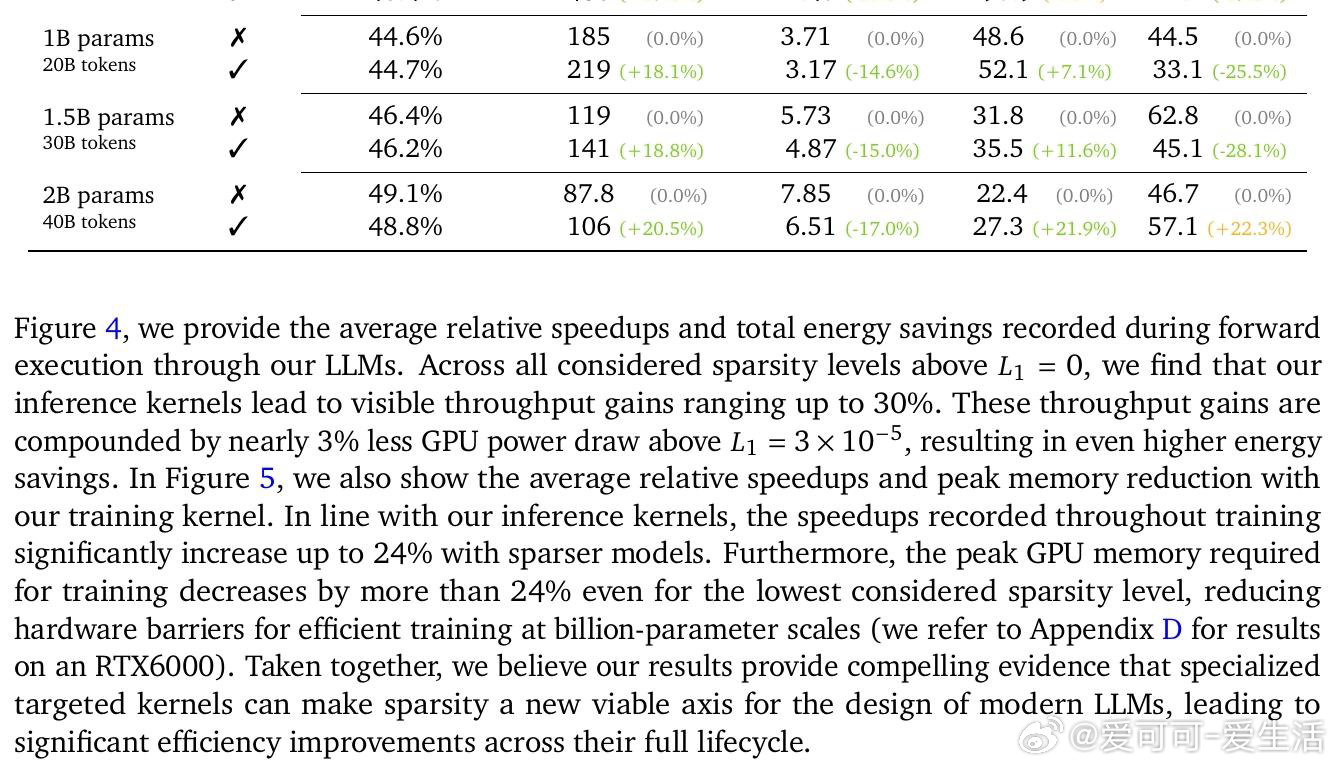
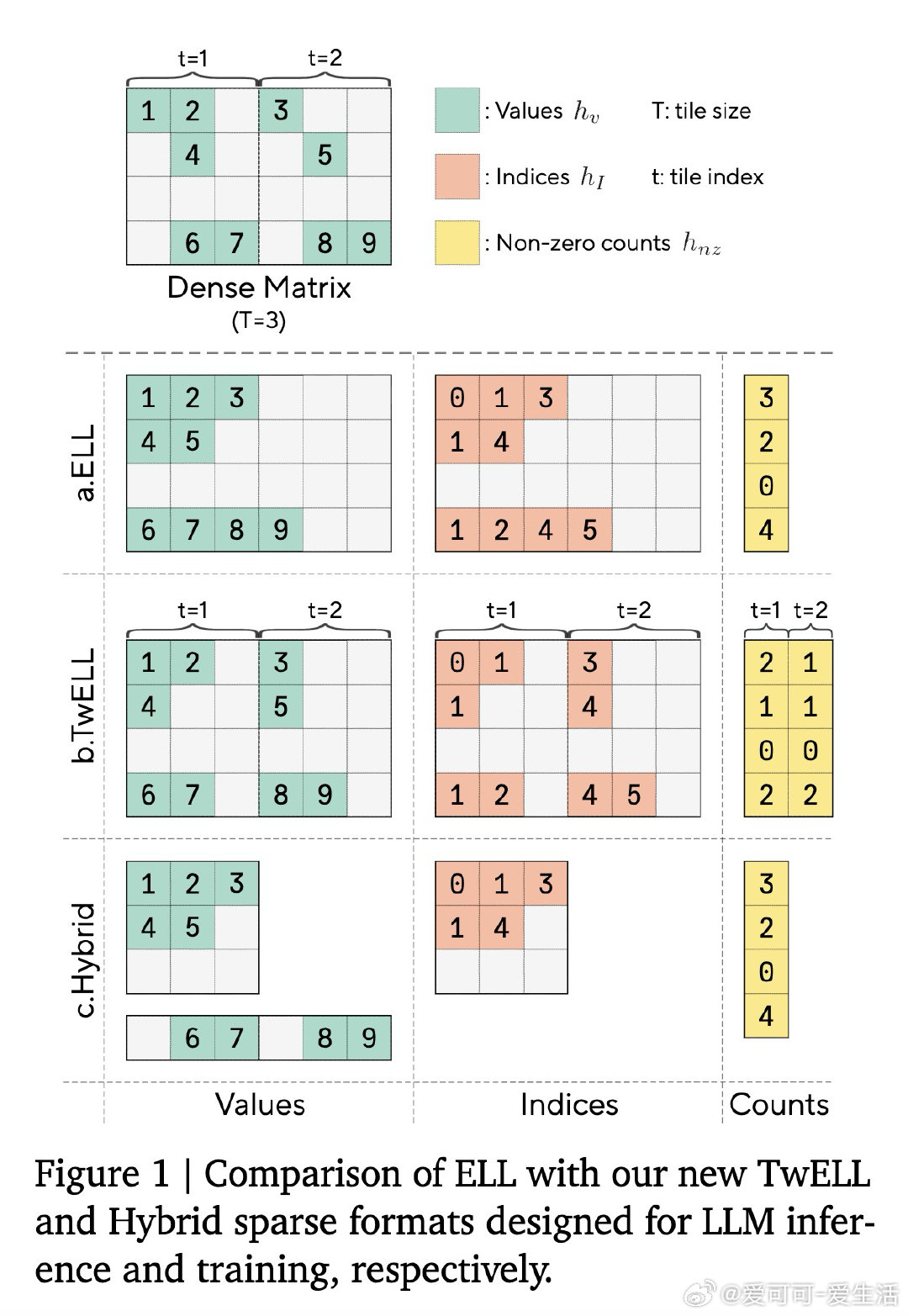
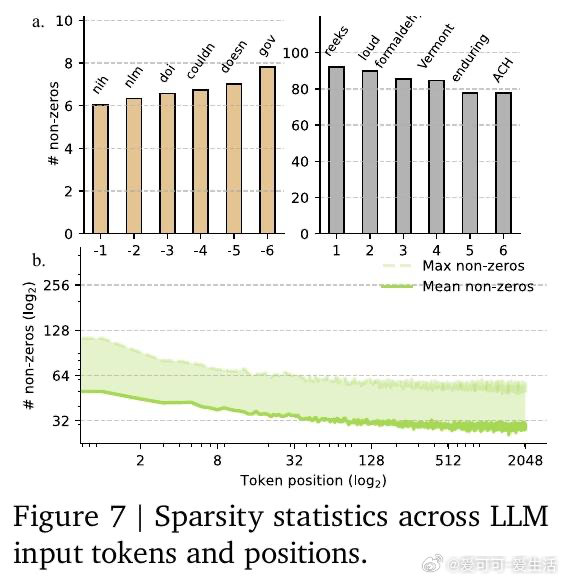
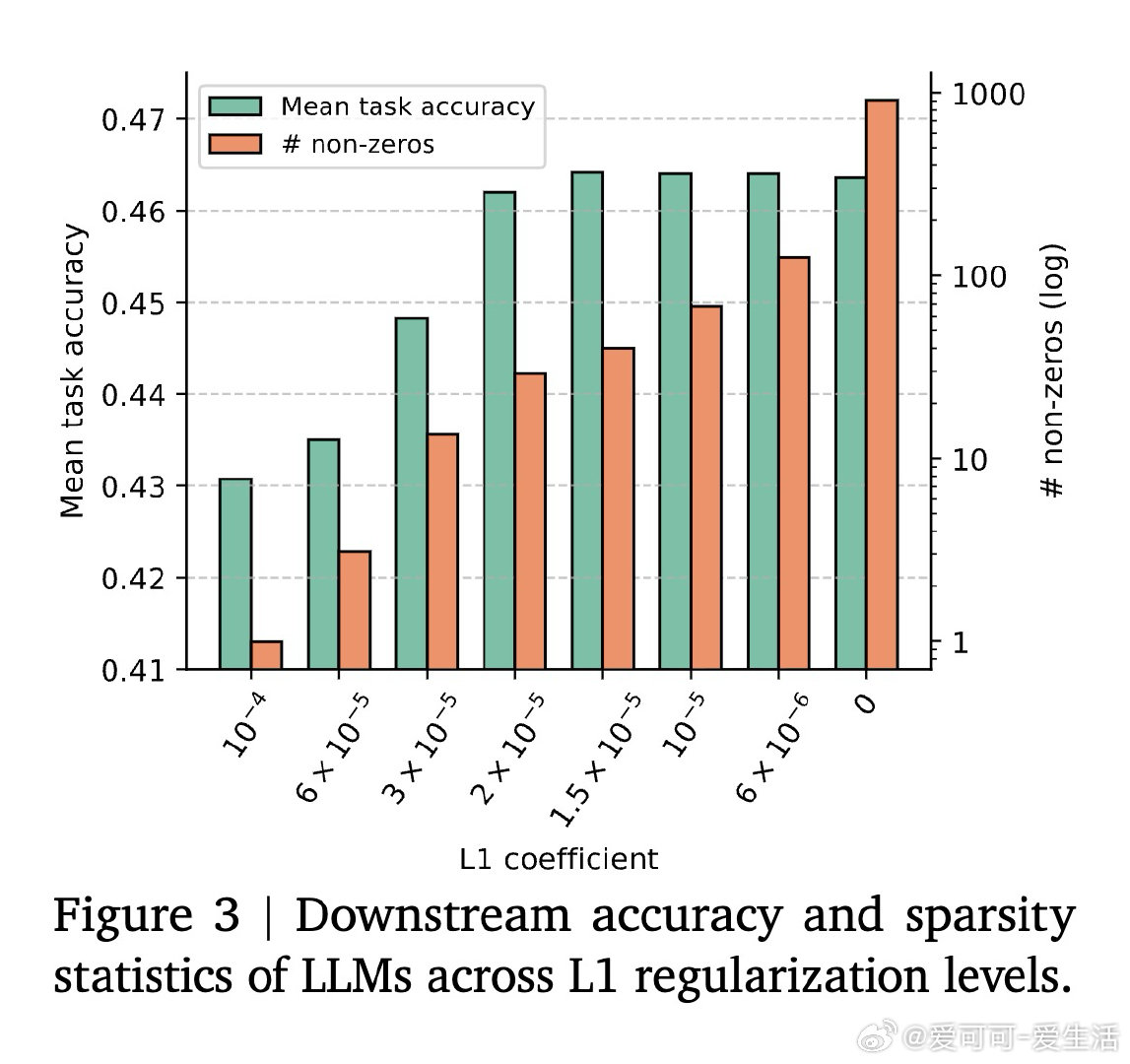
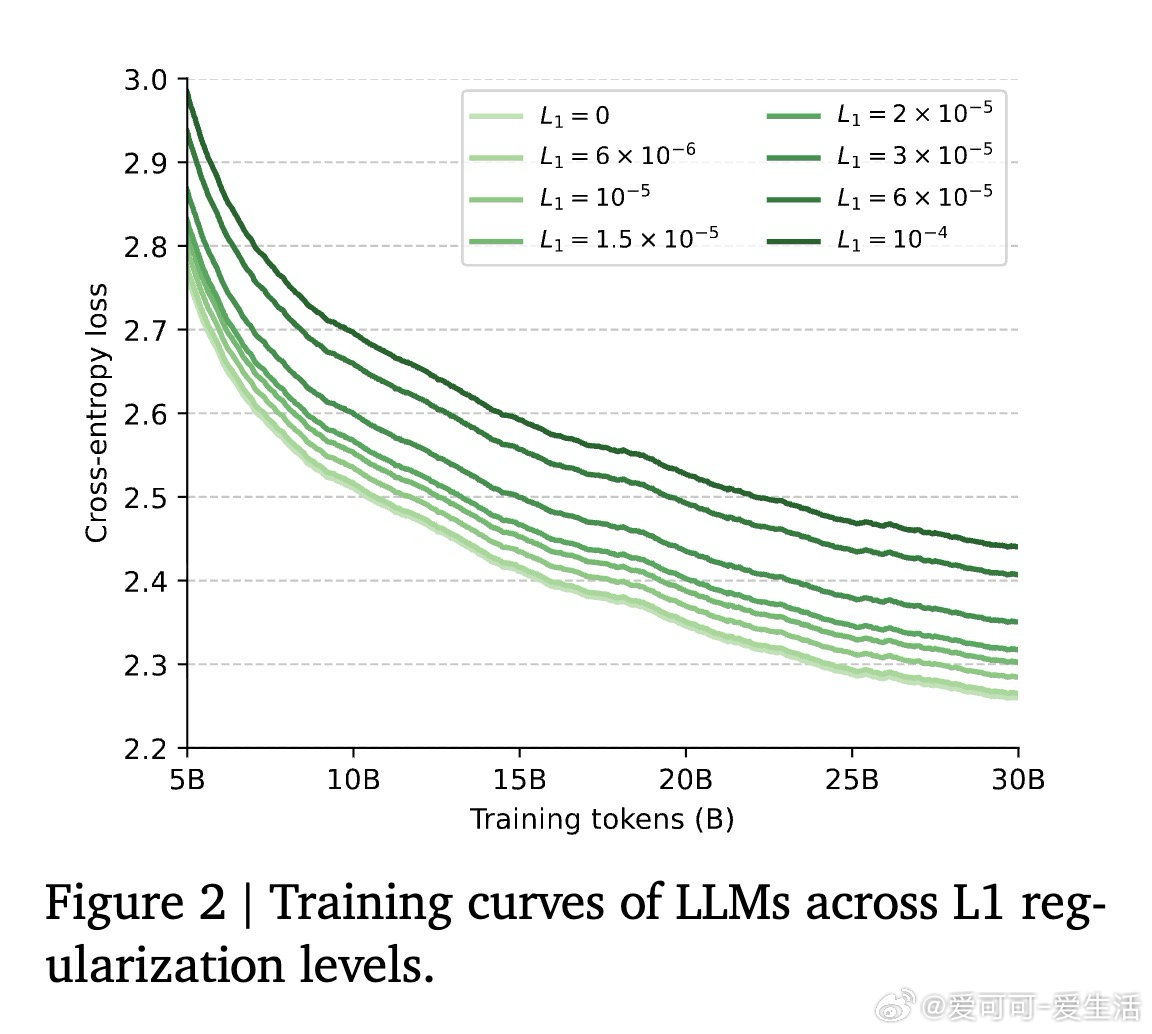
本文的核心洞见是:把"稀疏模式的发现"与"稀疏格式的构造"重新看作同一个矩阵乘法的末尾步骤,而非两个独立内核。由此,TwELL(分块ELLPACK)格式让门控投影在产出激活值的同时直接输出稀疏索引,消除了格式转换带来的内存往返;训练阶段则引入混合格式,将极端稀疏行压入紧凑ELL、将非均匀溢出行保留为稠密备份,使反向传播无需重算稠密激活。仅用L1正则化便可将99%的神经元置零,且七项下游推理任务的精度损失可忽略不计,2B参数模型推理吞吐提升20.5%,训练加速21.9%,显存峰值下降22.3%。
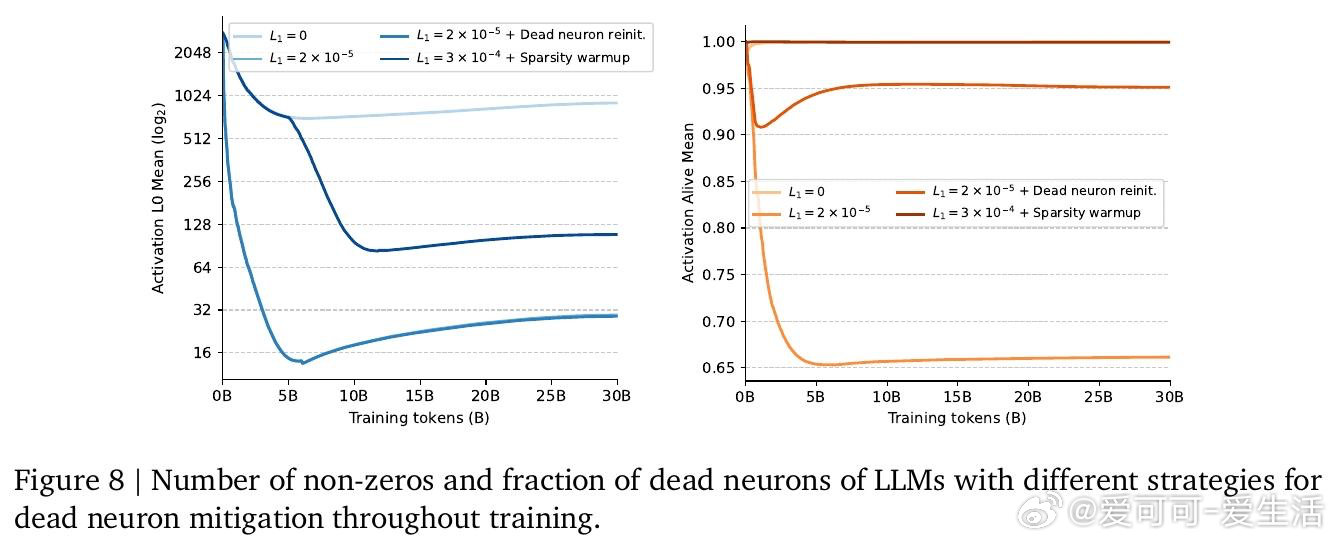
这项工作真正留下的遗产是:用两个融合内核覆盖前馈模块全生命周期(推理+训练),将稀疏性从"理论上更快"变为"工程上确实更快",并开源验证了这一路径随模型规模增大而收益递增。它为后来者打开的新门是:将同样的内核体系迁移至现有千亿级稠密预训练模型的微调稀疏化,以及在RTX 6000等低端设备上进一步放大收益(实测稀疏内核在该设备比H100快1.3–2.1倍)。但尚未跨过的门槛是:死神经元(约30%神经元永久失活)的机理尚未彻底解决,当前死神经元再激活策略属于初步探索,且超过99%稀疏度时性能开始可见下降,极限边界仍不清晰。
arxiv.org/abs/2603.23198
机器学习 人工智能 论文 AI创造营