[LG]《A Deep Dive into Scaling RL for Code Generation with Synthetic Data and Curricula》C Sancaktar, D Zhang, G Synnaeve, T Cohen [Meta FAIR & University of Tübingen] (2026)
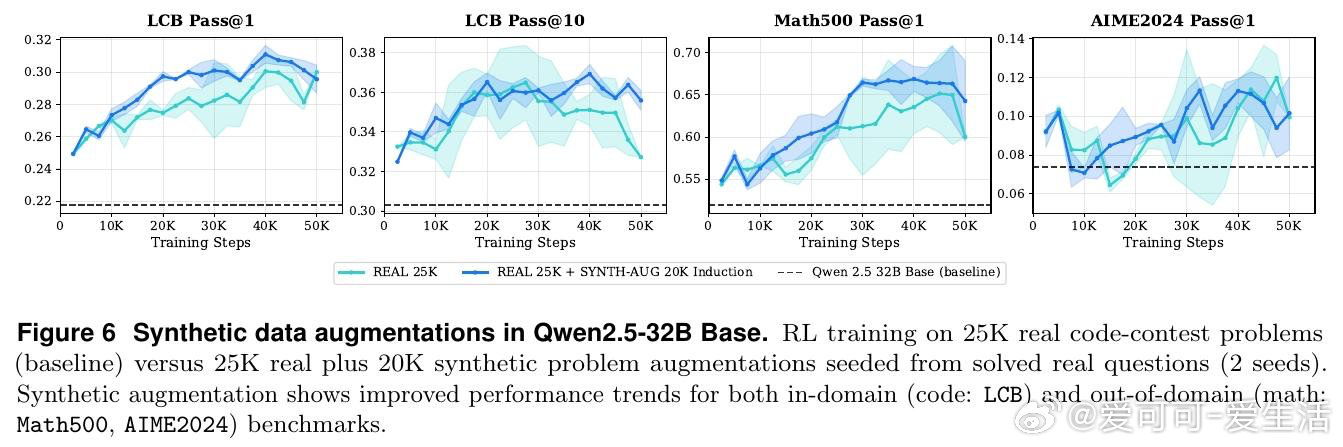
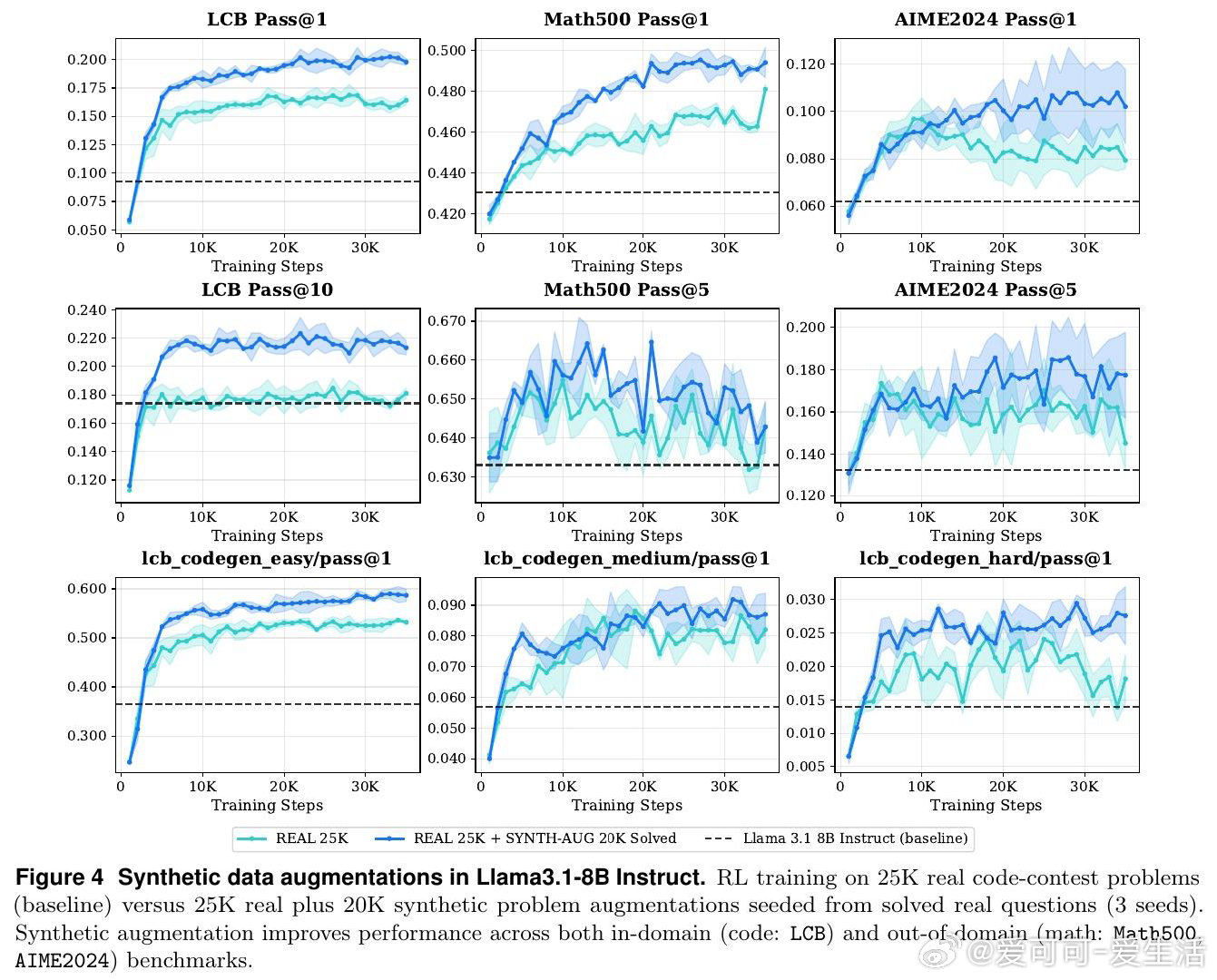
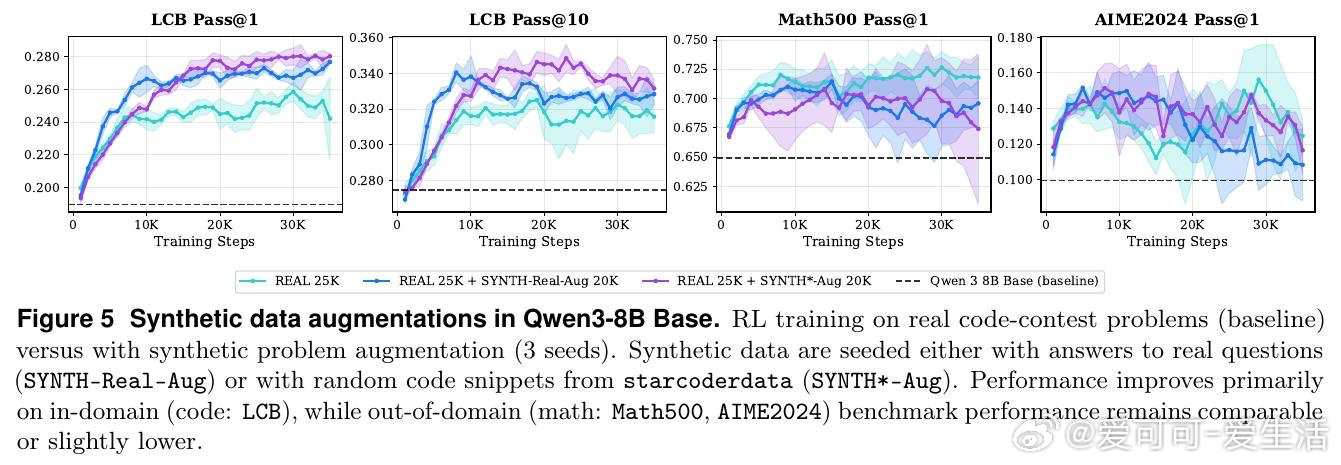
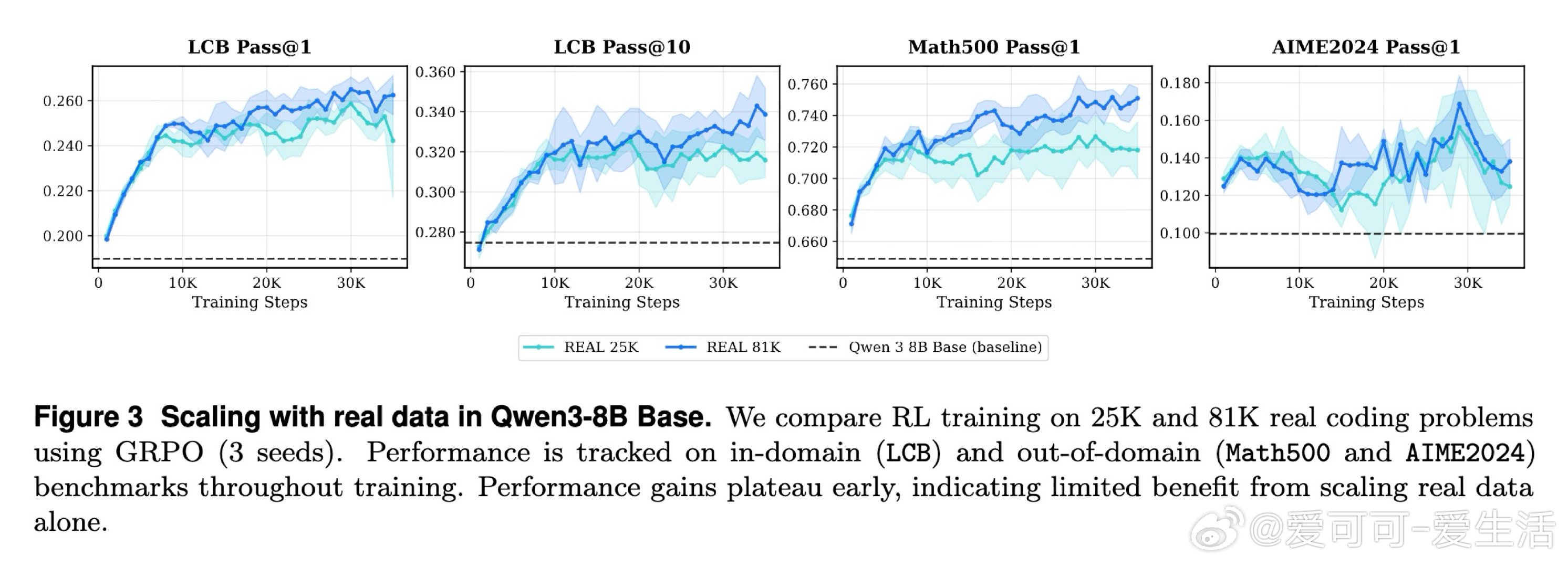
在代码生成领域,用强化学习(RL)持续提升大语言模型面临一个结构性困境:单纯堆砌训练题目数量不带来比例收益,性能在策略熵下降后迅速触顶。根本原因在于,数据的多样性与难度结构,而非体量,才是制约因素——太难的题让奖励稀疏无从学习,太容易的题让模型过拟合于简单模式。
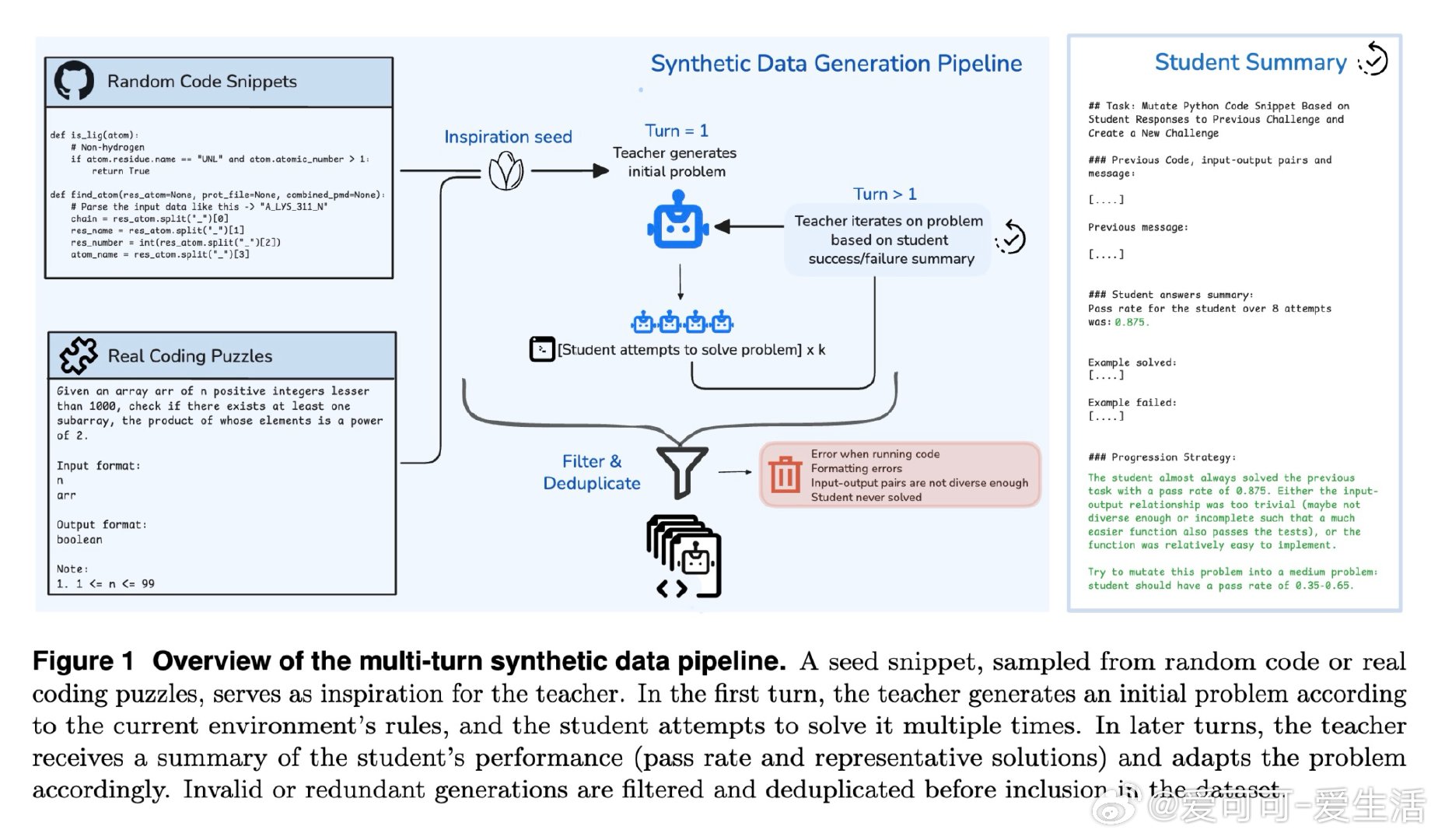
本文的核心洞见是:把"生成更多题目"重新看作"生成结构化的认知台阶"。由此,多轮教师-学生对话这一关键操作使问题得以解开:教师模型根据学生的实际通过率(而非人工标注)迭代变异同一道题,自动产出易-中-难三级梯度变体,无需对教师进行任何梯度更新。实验进一步揭示,将固定数据预算分配至四种不同环境(归纳、溯因、演绎、模糊测试)比在单一环境扩量更有效,且从中等难度题目出发的逆向课程在探索与收敛之间取得最佳平衡。
这项工作真正留下的遗产是:环境多样性可作为独立于数据规模的第三个RL扩展轴。它为后来者打开的新门是:无需训练教师模型,仅凭上下文学习即可构建可控难度的合成数据流水线。但尚未跨过的门槛是:教师与学生的解耦使数据生成无法实时响应训练中模型能力的变化,台阶效益在混合梯度下也仍不稳定,中等难度训练是否真正优于逆向课程有待更严格的对照实验验证。
arxiv.org/abs/2603.24202
机器学习 人工智能 论文 AI创造营