[CV]《End-to-End Training for Unified Tokenization and Latent Denoising》S Duggal, X Bai, Z Wu, R Zhang… [MIT & Adobe] (2026)
在生成式视觉建模领域,分词器与扩散模型必须分阶段训练是一个被默认接受的工程枷锁:先冻结编码器,再在固定潜空间上训练生成模型。这种割裂导致生成目标的梯度永远无法塑造表示空间,两个任务只能妥协于彼此的次优解。
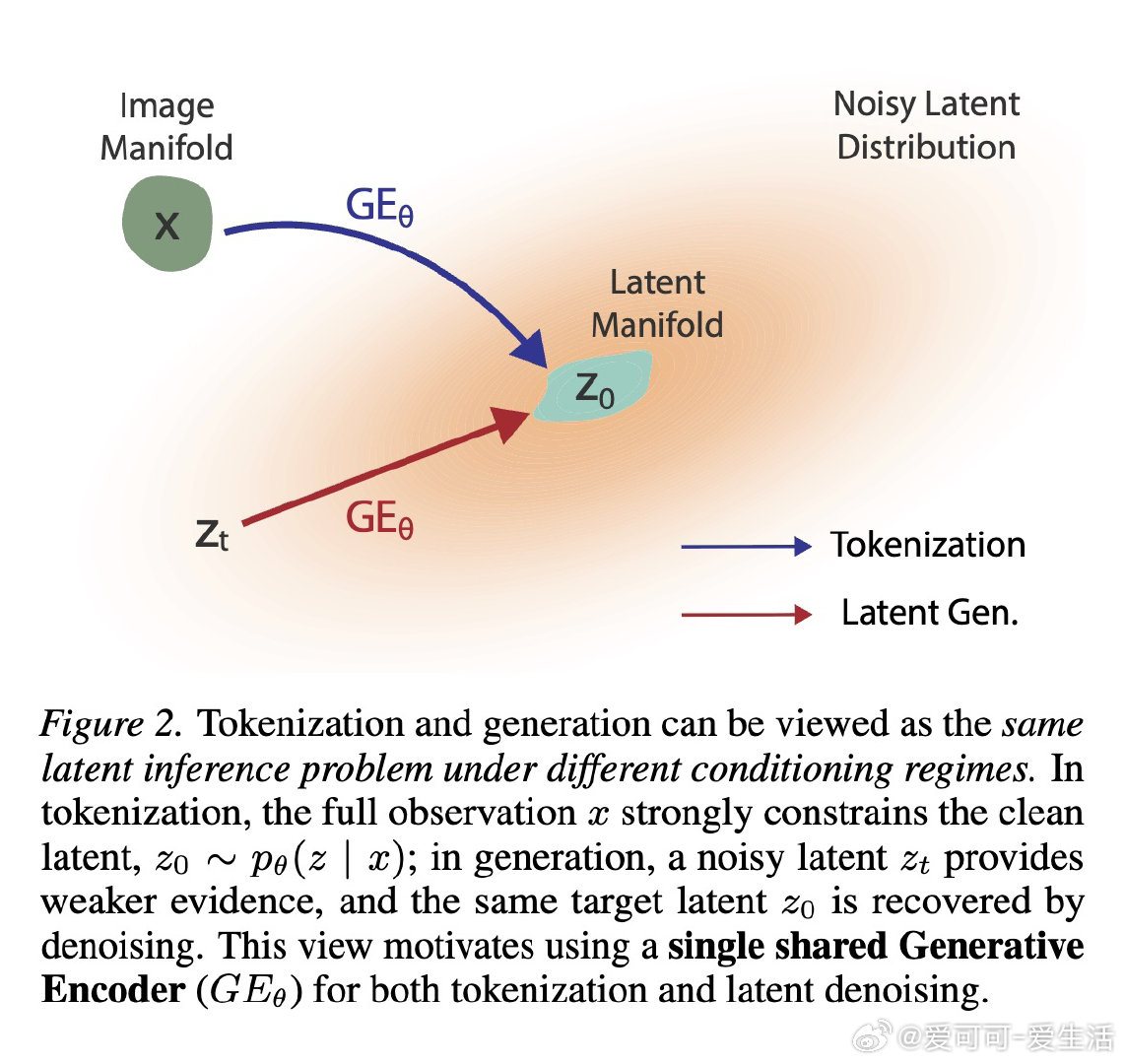
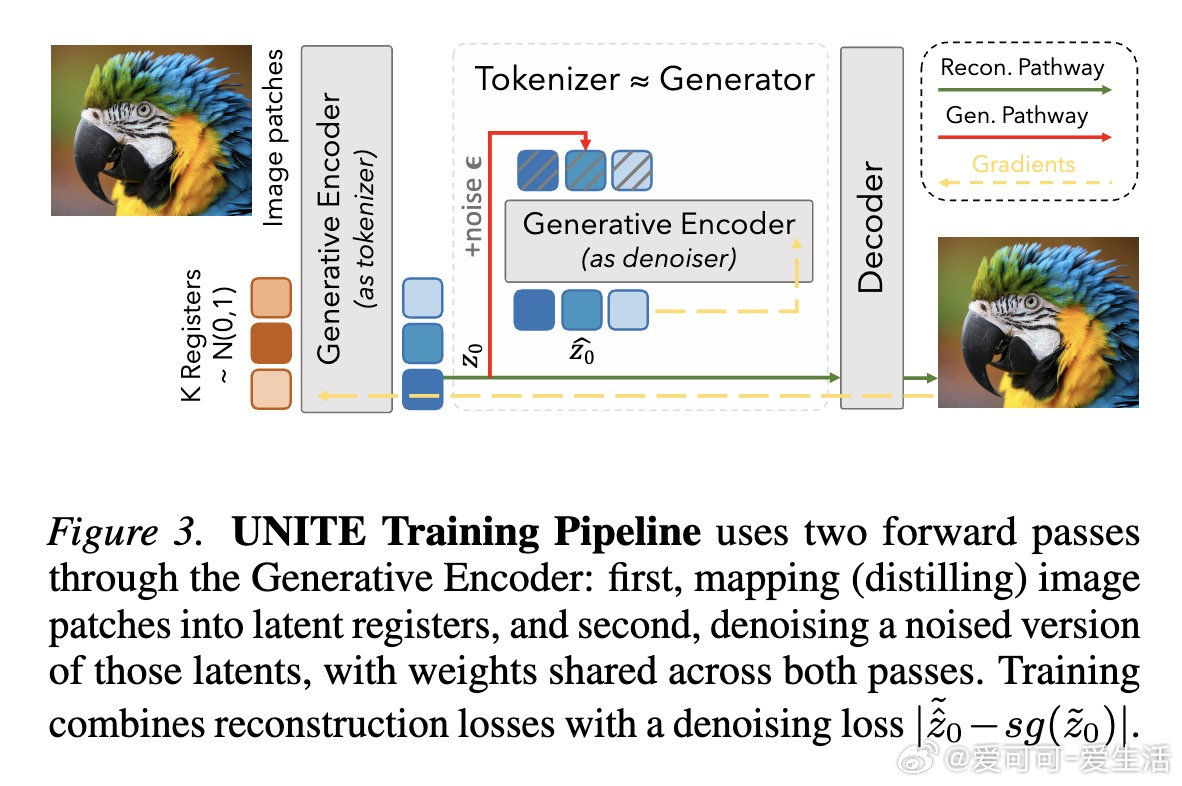
本文的核心洞见是:把分词(从图像推断潜变量)与去噪生成(从噪声推断潜变量)重新看作同一个潜变量推断问题在不同观测强度下的两种形式。由此,用一个权重共享的"生成编码器"在单次训练中执行两次前向传播这一操作,使两个目标的梯度直接竞争并共塑同一套参数,自然涌现出一种对重建与生成均适用的"公共潜变量语言"。
这项工作真正留下的遗产是:证明了无需预训练教师模型、无需对抗损失、无需多阶段流程,单阶段端到端训练即可让分词器与生成器互相强化而非相互干扰。它为后来者打开的新门是:将潜在扩散建模扩展至无DINO类预训练资源的领域(如分子、晶体),开辟了"表示空间由生成目标塑造"的新范式;但尚未跨过的门槛是:共享参数的判别能力(线性探测约30%)仍弱于专用表示模型,能否在视觉语言任务中替代专用编码器,尚无答案。
arxiv.org/abs/2603.22283 机器学习 人工智能 论文 AI创造营