【超越谷歌只是开始,PaddleOCR的“难度甜点区”才是大杀器】
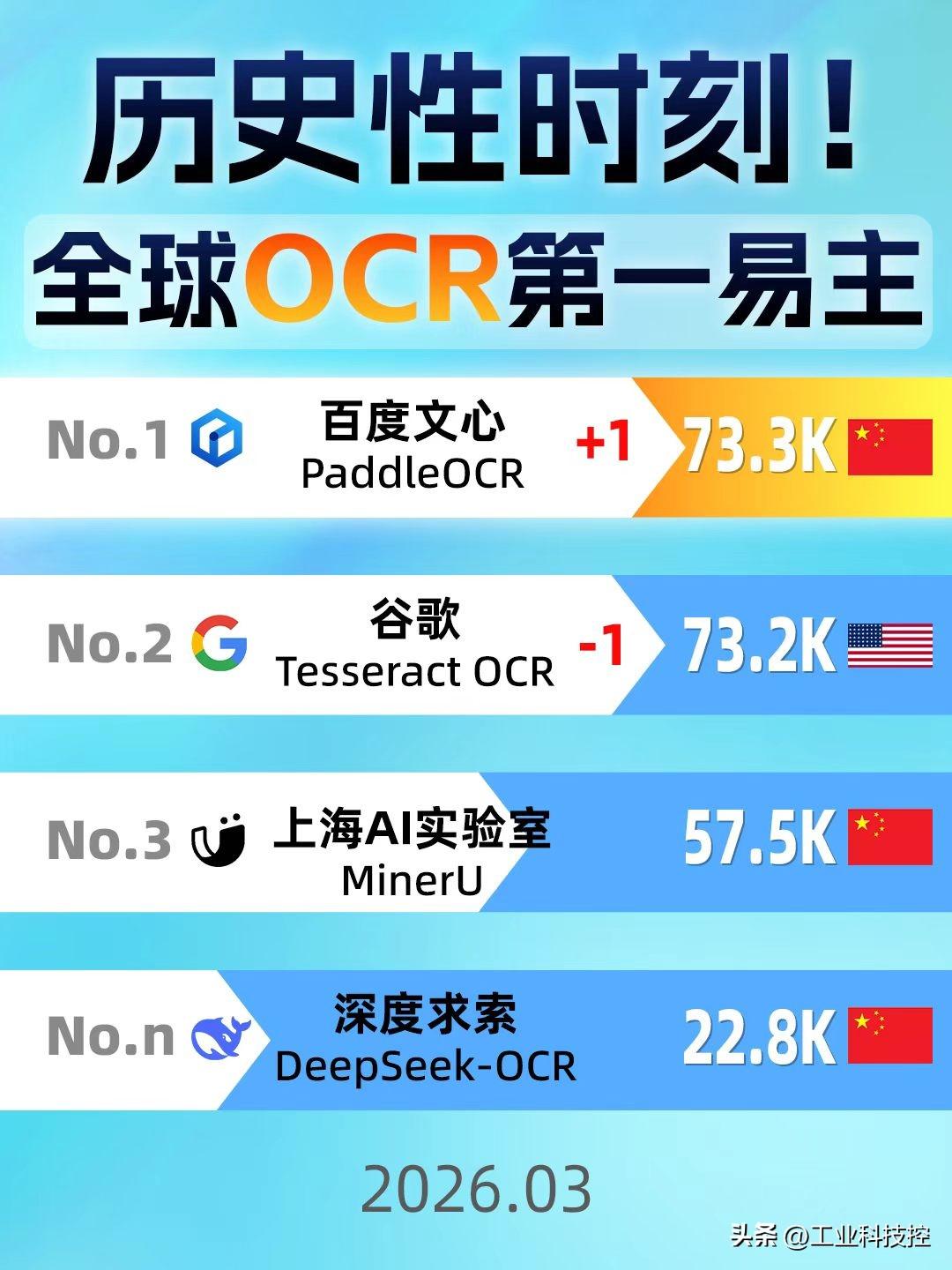
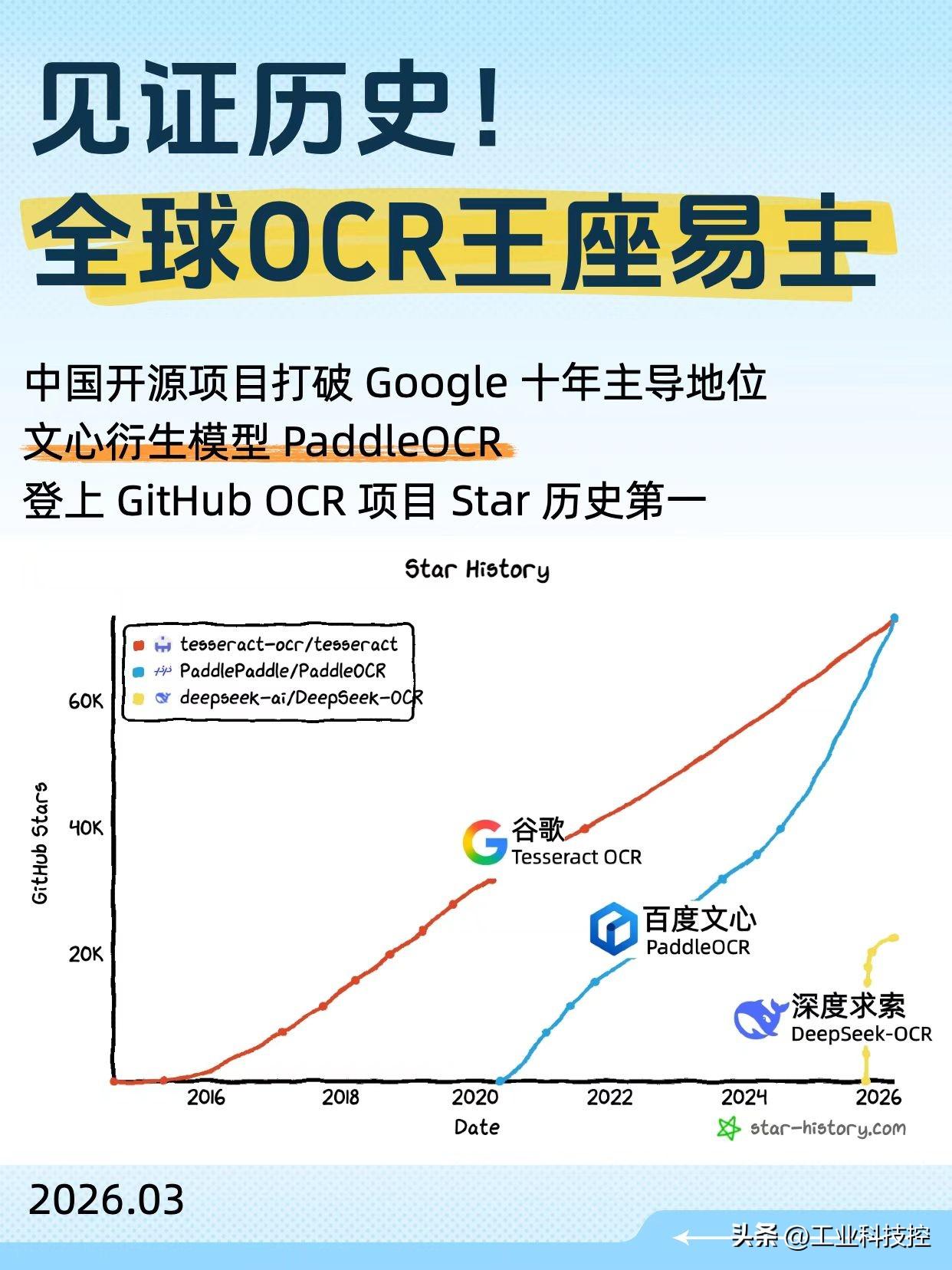
最近AI圈有个事挺有意思,百度文心衍生模型PaddleOCR在GitHub上Star数超过了谷歌的TesseractOCR,成了全球第一。这个事本身已经够热闹了,但我更感兴趣的是他们入选CVPR的一篇论文,看完之后发现,真正的技术看点其实藏在这里面。
这篇论文叫PP-OCRv5,核心就干了一件事:用5M参数的超轻量模型,在OCR任务上打平甚至超过了GPT-4o这种千亿级的大模型。5M对上千亿,这个悬殊程度自己去品。而且有意思的是,百度PaddleOCR团队并没有在模型架构上搞什么花活,真正的杀招全在数据上。
他们搭建了一套量化分析框架,把训练数据从难度、准确性、多样性三个维度拆开来看,结果发现一个关键规律——中等难度的数据对模型提升最有效,太简单或者太难反而效率不高。PaddleOCR团队把这个区间叫作“难度甜点区”,训练的时候集中喂这个区间的数据,效果远好于盲目堆量。
这个发现其实挺反直觉的。很多人以为训练数据越难越好,或者量越大越好,但实际不是这么回事。模型训练跟人学习一个道理,题目难度得跟当前水平匹配,卡太久了不行,一直做简单题也不行。PaddleOCR这套方法论最大的价值在于,他们把数据质量和数据规模在一定程度上解耦了,优先保证数据在难度和多样性上的合理性,再去考虑规模。这种Data-Centric的思路,跟过去围着模型架构打转的玩法完全不是一个路数。
当然,不是说小模型能全面替代大模型,但这个方向至少证明了一件事:数据策略的上限还远远没被挖掘出来。过去大家习惯把模型架构当成核心变量,觉得堆参数、堆算力才是王道,但类似PP-OCRv5这类工作正在提示,数据本身正在变成一条独立的能力曲线。谁能在数据处理上做出更精细的优化,谁就可能用更小的成本跑出更好的效果。
百度文心这次CVPR入选的还有另一篇PaddleOCR-VL,讲的是怎么解决VLM计算效率的问题,也是从数据处理的视角切入。整体看下来,PaddleOCR团队在OCR这条线上确实走出了一条不太一样的路,不拼参数、不拼算力,拼的是怎么把数据玩明白。在AI竞争逐渐转向数据获取和处理效率的当下,这个思路的含金量,可能比登顶GitHub本身还要高。
百度 文心一言 文心大模型 文心大模型 谷歌 OCR deepseek AI大模型 科技 技术 干货分享