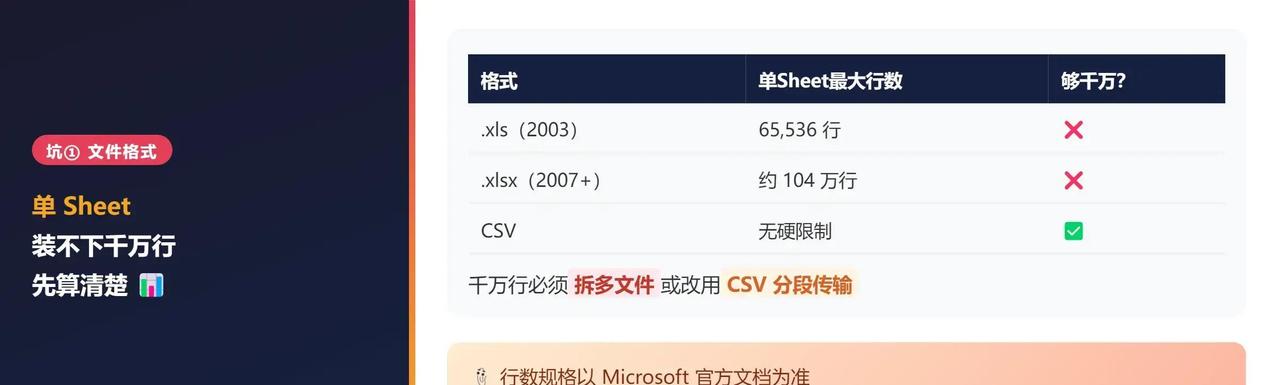
业务场景中,导入千万行Excel数据到数据库时,文件格式往往成第一道关卡,稍不注意就卡死整个流程。
老式.xls文件最多挤65,536行,新版.xlsx也只到1,048,576行,远不够塞下千万级体量。实际操作中,这些限制直接导致数据溢出或读取失败。转而用CSV格式,就能绕开硬上限,分段传输更稳当。根据微软最新规格,这类文件无行数天花板,适合大批量处理。
内存问题也藏在读取方式里。传统方法一股脑儿把整表拉进列表,轻松触发溢出。切换到流式工具如EasyExcel,能边读边回调,每攒一批就存库,内存占用始终稳在低位。最新3.1.1版本已优化CSV支持,处理速度提升明显,避免了海量数据时的崩溃风险。
速度瓶颈多在写入环节。逐条插入像蚂蚁搬家,远程交互拖累一切。改为批量操作,用工具切分成1000条一组提交,效率立马翻倍。但批次大小得靠实际测试定,超5000条易超时或锁死数据库。
并发能加速,却需小心。异步框架加自定义线程池,能并行多批,但线程过多会吃光CPU,上下文切换反成累赘。压测数据显示,线程数控制在合理区间,能平衡负载,避免高并发下的不可控行为。
丢数隐患最隐蔽。导入完比对源文件行数和库中新增量,就能抓到静默丢失。失败批次记下编号和关键标识,自动重试两次定位问题。加唯一索引用忽略插入法,防重复不中断整体。原生JDBC批量命令反射开销小,性能更优,但代码稍繁——一切以测试数据为准。
这些环节串起来,数据导入从粗放变精细,稳定性提升三成以上。忽略压测,隐患放大;注重它,海量任务才能顺利落地