美剧《火线》里有条贯穿多季的暗线:
巴尔的摩警察局为了让犯罪数据好看,把重罪降级为轻罪,让强奸案凭空消失。上级看着报表上的数字逐月下降,在市政厅汇报时满脸骄傲。
只有街区的居民知道,街上枪声一点没少。
剧里有句台词:youjukethestatsandmajorsbecomecolonels.刷刷数据,少校能升上校。

但谁也没想到,2026年,这句话的新版本正在中国互联网大厂上演。
只不过被刷的不是犯罪率,而是aitoken消耗量。只要你刷刷token,摸鱼也能变劳模。
最近,小红书上有个帖子很火。
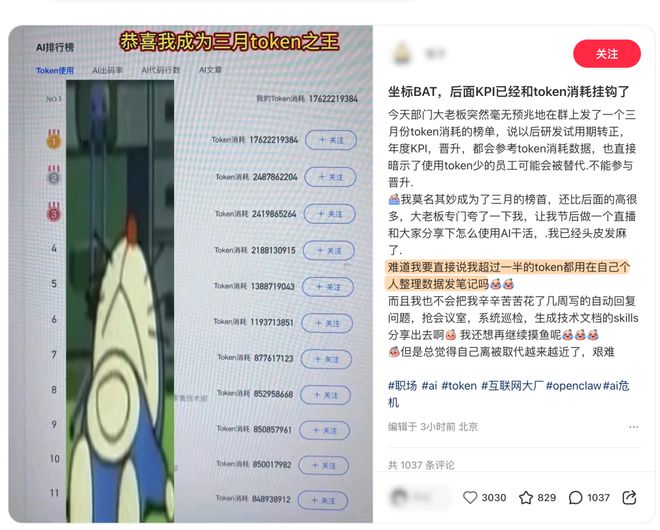
一个自称在bat大厂(首先b排除百度)的网友说:部门突然开始搞token消耗排行榜,以后试用期转正、年度kpi、晋升,都要参考这个数据,甚至用得少的人,可能被替代。
他是三月份的榜首,还遥遥领先,被老板点名夸了一顿,让他节后给全部门做直播分享怎么用ai干活。
但他没敢说的是,自己超过一半的token,是在整理个人数据发笔记。。。
不光是大厂噢。
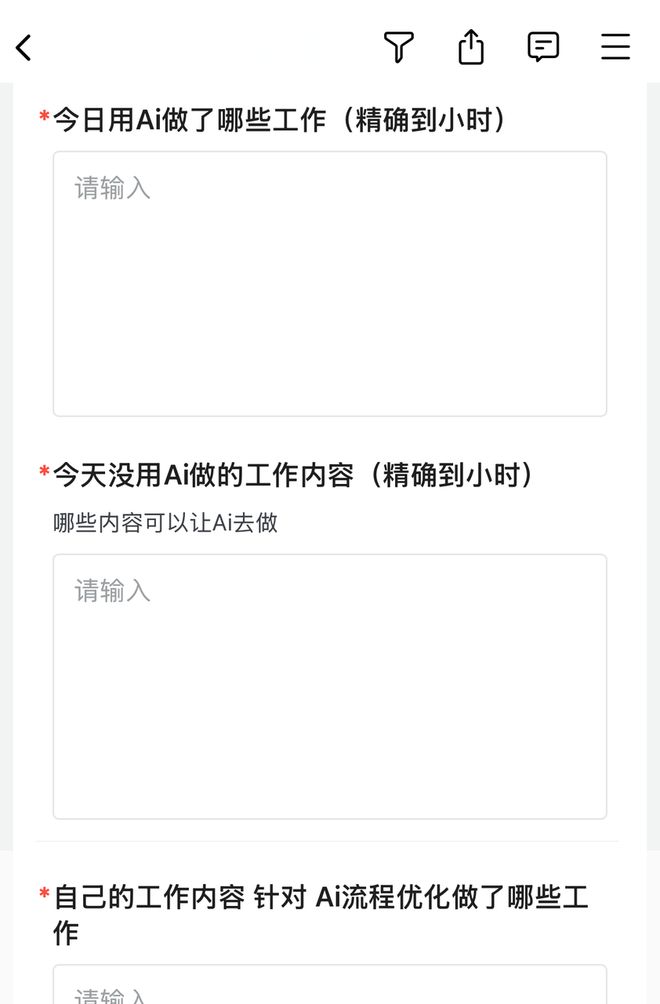
我身边有个发小在一家公司干了三年,前几天突然被要求:日报里要填写今天用ai做了哪些工作,提高了多少产能,还要精确到小时。
搞得他现在动不动要打开ai软件,想想怎么刷。
看到这些,差评君第一反应是迷惑,这不就是2026年版的工位亮灯等于加班吗??
在聊这事之前,咱先简单解释一下token。
token是ai处理信息的最小计量单位,你可以把它理解成ai世界的字数/货币,一个中文字大约等于1到2个token。
你和ai对话一轮,消耗的token=你发给ai的字+ai思考推理+ai回复的字。
ai模型公司呢,就按token消耗量去收钱。
理论上,token消耗量和ai交互是成正比的。你消耗越多,就能说明你跟ai交互越频繁。
听起来没毛病,黄仁勋也这么想的。
3月下旬的英伟达gtc大会上,黄仁勋说公司应该给每个工程师配一笔token预算,金额大约是基本工资的一半,让ai把他们的产出放大十倍。

后来他在all-in播客上又举了个例子:
假设有一个年薪50万美元的工程师,年底你问他今年花了多少token,如果没花到25万美元,老黄说会“deeplyalarmed”,深感震惊。
他要说5000美元呢?
老黄直接“iwillgoapesomethingelse”,中文大概就是气得跳脚,当场发疯,叼你md(最后一句我加的戏)。

在老黄看来,优秀的工程师就应该大量使用ai,用得越多产出越高。
毕竟公司给你配了ai资源,你用资源提效,产出放大,你要是不用,确实说不过去。
这套逻辑,不只老黄一个人这么想。
2025年4月,shopifyceotobilutke给全公司发了封备忘录:申请加人之前,必须先证明ai做不了这个工作,而ai的使用情况也要纳入绩效考核。
硅谷甚至出现了一个专门的词来形容这股风气:tokenmaxxing,token最大化。
《纽约时报》科技记者kevinroose给它做了专题报道,里面数据很夸张:openai有工程师一周处理了2100亿token,anthropic有用户一个月在claudecode上烧掉了15万美元。

而现在,这股风终于吹到了国内,企业们开始把token消耗、ai使用时长绑进绩效。。。
不是兄弟。。。
和ai互动得多,不代表解决的问题就多啊。就好比我们去健身房,不是去了100次体重就一定减少的。
好,退一万步讲:
就算我们暂且接受“用得多=产出高”这个前提。那至少这个指标应该很难造假吧?
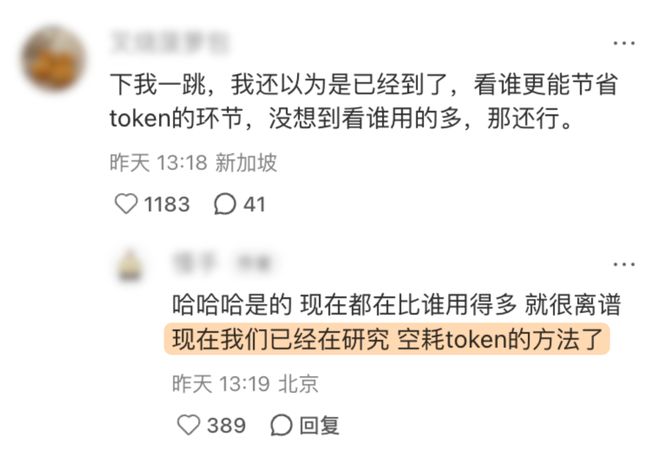
恰恰相反,刷token,可能是2026年最容易的一件事。
差评君简单露几手,看完你就知道这玩意作为指标有多差劲了。
第一种,上下文滚雪球。
为了联系上下文,ai的每次回答都会把之前的所有对话从头重读一遍。对话越长,每轮重读消耗的token越多。第1轮只要1500个tokend,但到了第20轮、第50轮光重读就要烧好几十万、百万token。
你就这么无限对话下去,就算被领导质疑,你就说:这可是我反复追问了好多轮才得到满意的结果。
懂不懂“深度思考”啊。

第二种,开50个aiagent(代理)让它自动跑任务。
agent会自己派活、自己重试、遇到问题自己绕路,每个步骤都在烧token,思考过程也算钱,跑一晚上第二天你就是部门劳模。
第三种更简单。
把一整个10万行代码仓库扔给ai,让它“分析一下”就行,努力的样子从未如此省力。
其实这些方法一点都不高级,制定这条kpi的公司、管理层,也不可能没预料到会被刷。
因为经济学有个概念叫goodhart定律:当一个度量指标变成了考核目标,它就不再是一个好指标。
它一定会被刷。
英国nhs曾经考核急诊等待时间不超过4小时,结果医院让救护车在门口停着不让病人下车,因为等待时间从进门开始算。
没有人觉得自己在作恶,每个人都在合理地优化自己面对的指标。

token排行榜也一样。
它已经成了ai时代的功德箱,佛祖不看金额看诚意,领导不看产出看次数。
所以真正的问题来了:
为什么明知会被刷,这个指标还是出现了?
因为它的背后,是ai时代特有的、自上而下的焦虑。
过去两年,不拥抱ai就会被淘汰几乎成了科技圈的政治正确。ceo们在财报电话会上必须提ai,投资人看的是ai渗透率,媒体写的是某公司全员接入大模型。
meta2026年绩效关注员工用ai做出多少成果

这种焦虑一层一层往下传:
董事会问ceo“我们的ai战略是什么”,ceo问vp“ai落地进度怎么样”,完了vp又发条语音问总监“能不能给我一个数据证明大家在用”。
在这种氛围下,管理层就不得不需要一种手段强推ai渗透。
可问题是,ai时代产出归因太模糊了。
代码行数、需求完成数、项目交付,现在说不清到底多少是ai贡献的。上头一问你ai渗透到什么程度,你直接哑火。
当真实贡献不可观测,管理者就只能抓最近的、可数的东西。
诶,token消耗量恰好是那个完美指标:可量化、可对比、可造假。
到这,你就能理解为什么token排行榜会出现在大厂里了,又能逼着员工用起来,又能拿去跟老板交差,当作一个向上汇报的数据,美滋滋。

当然了。。。
鉴于这次kpi提出者是bat大厂管理层,也可能存在第二种原因。
你想想,“不用ai就会被淘汰”、“token消耗代表先进性”,这套行业叙事的最大受益者是谁?
bat等大模型厂商,毕竟靠卖token赚钱,不过这就不在本文讨论范围内了。

差评君更关心的是,今年大厂能把token消耗纳入考核,小公司把ai使用时长加进日报。
那明年呢,你所在的公司呢?
我不是说ai没用,也不是说不该推ai。
的确,在ai应用早期阶段,强制接触有其合理性,历史上也有过“强推”的成功先例。
20世纪初,福特工厂强制流水线作业,工人强烈抵触,觉得这是剥夺手艺人的尊严,但流水线最终让汽车从富人玩具变成了普通家庭的交通工具。

组织一旦习惯了旧的做事方式,即使新工具明显更好,惯性也会让所有人赖在原地不动。
从企业角度来看,强推ai有组织变革的正当性。
可问题是,福特流水线和ai根本不一样啊。
福特是直接把生产方式换了,流水线往那一架,你作为工人没法再手搓了,这是从底层变革生产力。工人抵触归抵触,离职归离职,福特加工资把人留住,最后效率确实提上去了。
但ai不一样。
对互联网公司而言,ai没有在根本上替换他们的工具链。
员工用不用、怎么用,选择权还在自己手上。
ai要真能升效,用ai的人自然会在产出上胜出,大家自然会选择最高效的方式,不需要你拿排行榜逼。
如果所谓的token排行榜能度量员工的价值,那打字排行榜早就是诺贝尔文学奖的评选标准了。

写作的价值不在于你写了多少个字,思考的价值不在于你翻了多少页书,使用ai的价值也不在你烧了多少token。
不要因为ai时代的焦虑,就把人的价值也一起烧掉了。
巴尔的摩街头的枪声没有因为数据变好看而消失,你公司的效率也不会因为token烧得多就一定提升。
撰文:刺猬