[LG]《Dictionary-Aligned Concept Control for Safeguarding Multimodal LLMs》J Luo, J Yang, T Neiman, L Fan… [University of Pennsylvania & Amazon] (2026)
在多模态大语言模型安全领域,激活空间干预是一条有效防线,但已有方法要么仅控制不足20个概念、覆盖太窄,要么虽使用稀疏自编码器却无法自动厘清各神经元对应何种语义——过度抑制损坏能力,抑制不足则放行有害输出,两者之间的权衡无法精确拨动。
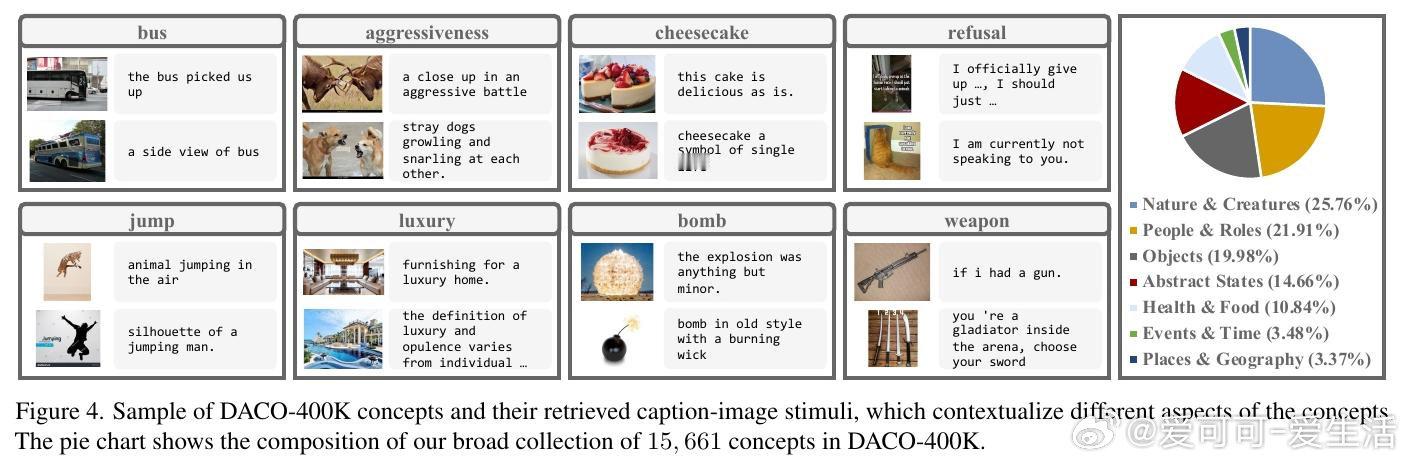
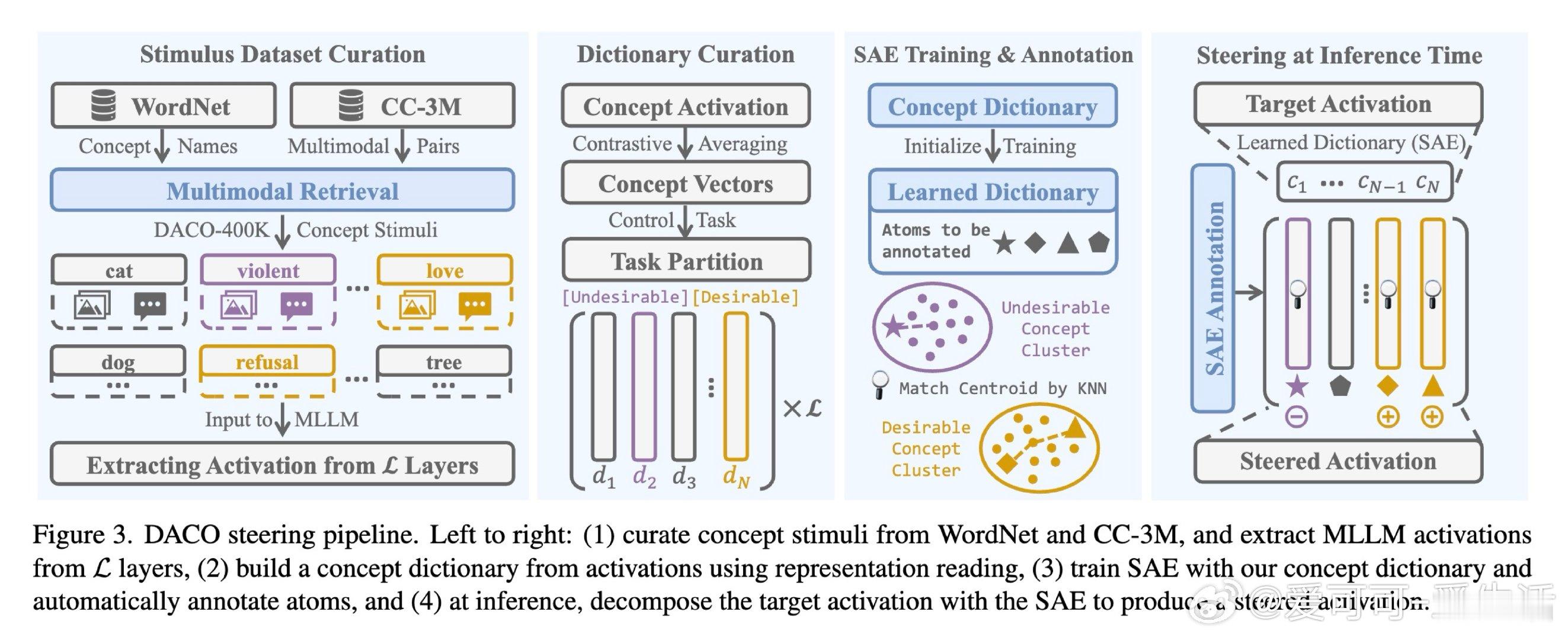
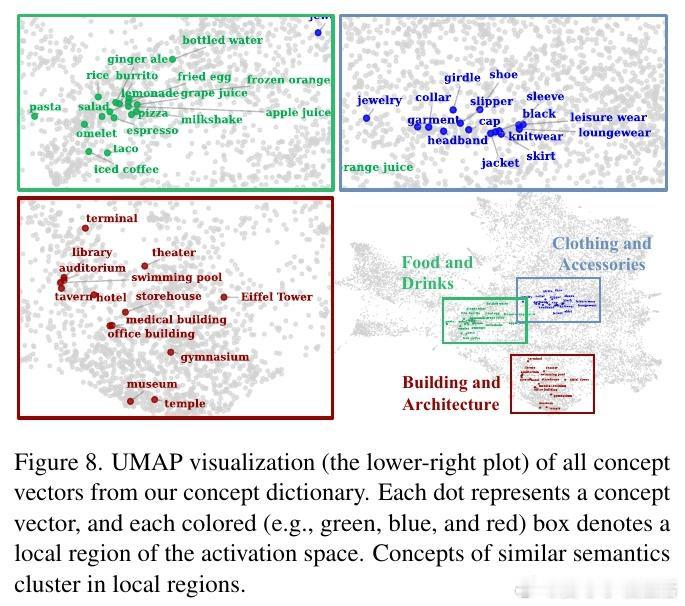
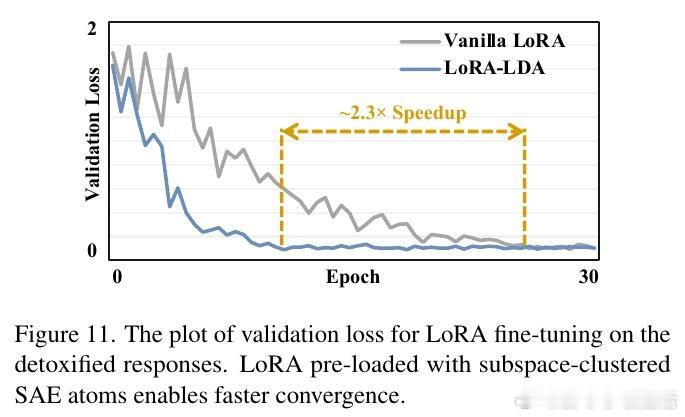
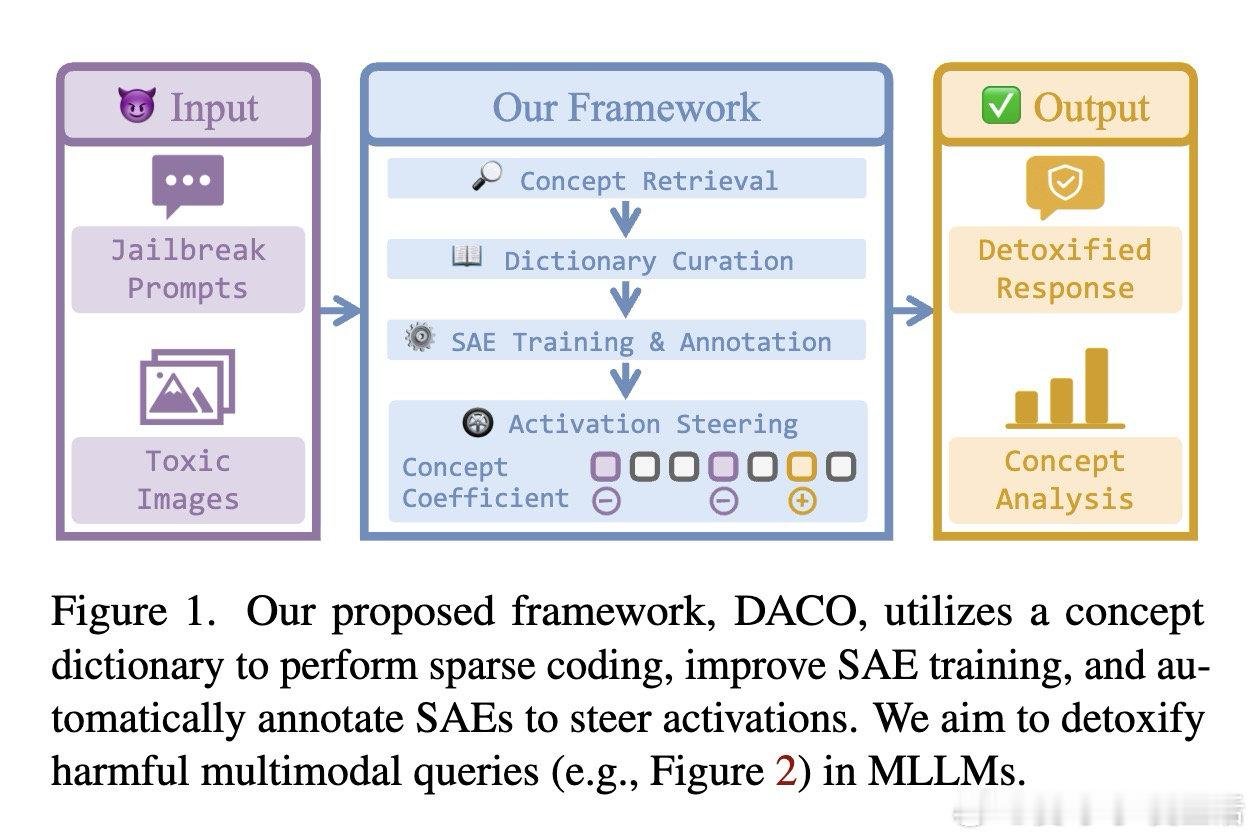
本文的核心洞见是:把"激活空间中的方向"重新看作"可检索的多模态概念坐标"。由此,一套三步操作使问题得以解开:从WordNet提取1.5万个概念词、用几何均值跨模态匹配CC-3M中40万图文对构建激活方向字典,再以该字典初始化稀疏自编码器并自动为神经元贴上"有害/无害"标签,推理时按标签定向抑制或增强对应系数,整个干预仅增加14.6%的逐词延迟。
这项工作真正留下的遗产是:将机械可解释性(稀疏自编码器)与语义接地(概念字典)打通为一条流水线,令安全干预首次具备人可读的概念粒度。它为后来者打开的新门是:用同一框架迁移至幻觉抑制、偏见矫正等其他对齐目标。但尚未跨过的门槛是:字典覆盖仍依赖CC-3M的语料偏分布,对长尾恶意模式(如新型越狱话术)的概念召回率尚待验证。
arxiv.org/abs/2604.08846
机器学习 人工智能 论文 AI创造营