[LG]《Efficient RL Training for LLMs with Experience Replay》C Arnal, V Cabannes, T Cohen, J Kempe… [FAIR at Meta] (2026)
在LLM强化学习后训练中,推理生成成本高达总计算预算的80%以上,但现有流水线采用"生成即丢弃"策略——每条轨迹仅用一次梯度更新便被抛弃。这一惯例源于"陈旧数据必然损害性能"的主流共识,导致极度的样本浪费。
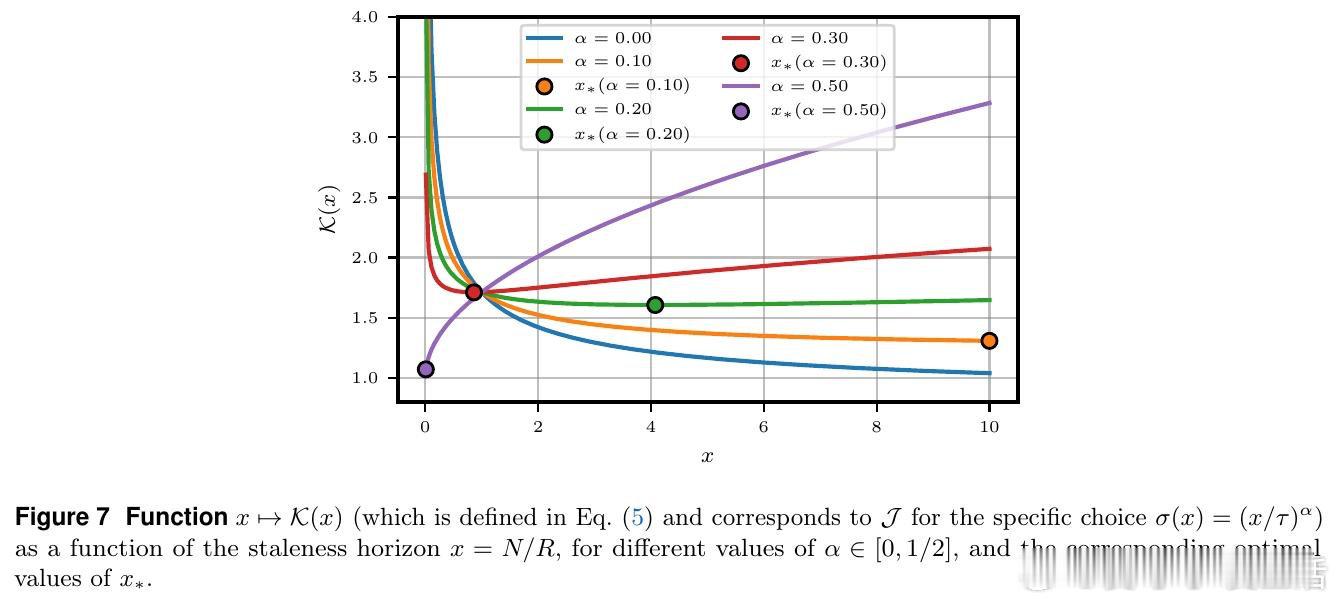
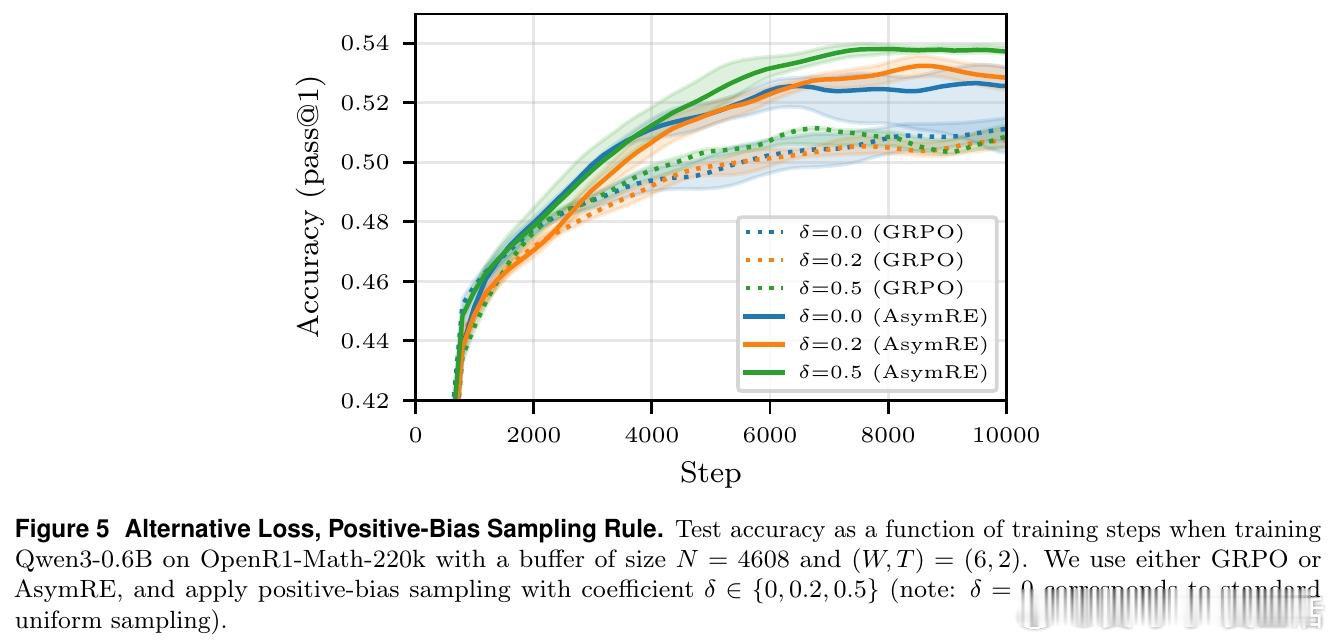
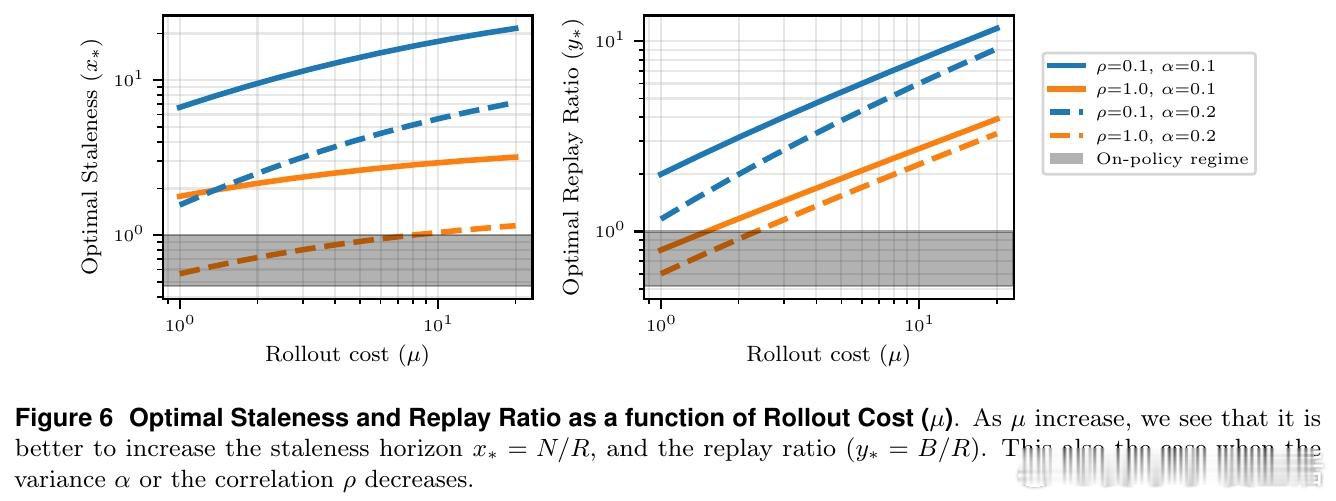
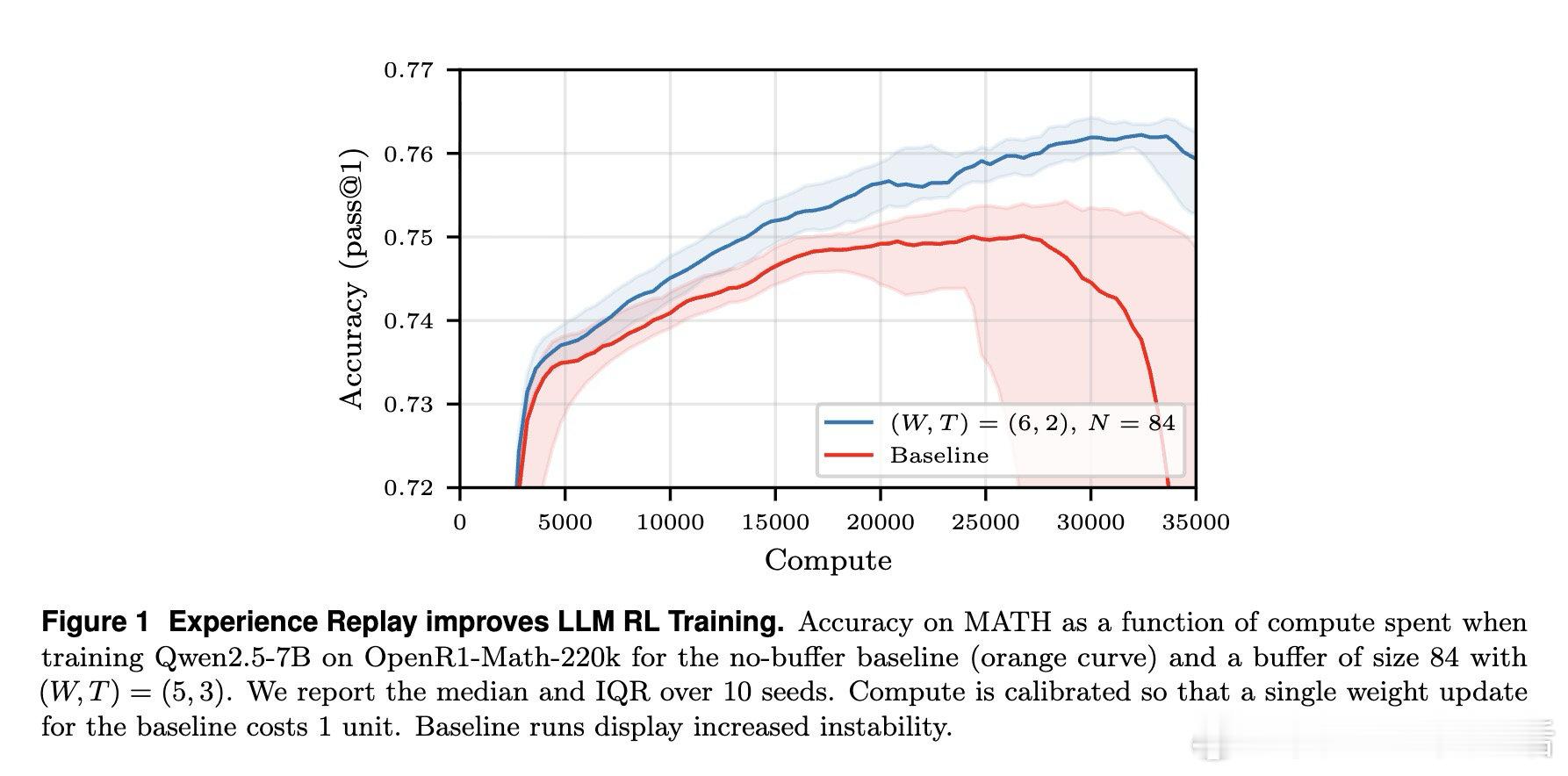
本文的核心洞见是:把"新鲜数据vs.计算效率"的取舍重新看作一个可被数学量化的三维均衡——陈旧性噪声、样本多样性衰减、推理计算成本。由此,将历史轨迹缓存复用这一关键操作使问题得以解开:理论推导证明严格在策略采样并非最优,并给出最优缓冲区大小与重放比率的闭合解;实验证明,合理配置缓冲区可节省40%计算量,同时模型准确率不降反升,还因训练分布多样化抑制了策略熵坍缩。
这项工作真正留下的遗产是:为LLM强化训练建立了"每单位算力最大化性能"的设计范式,而非"每步梯度最大化性能"。它为后来者打开的新门是:将经典深度强化学习的经验回放机制系统性地引入LLM训练工程实践,并配套了可落地的异步流水线伪代码。但尚未跨过的门槛是:实验仅在7B以下模型验证,更大规模前沿模型的收益鲁棒性仍待确认,且优先级采样等高阶策略的规模化效果亦尚不明朗。
arxiv.org/abs/2604.08706
机器学习 人工智能 论文 AI创造营