[CV]《PhysInOne: Visual Physics Learning and Reasoning in One Suite》S Zhou, H Wang, H Cheng, J Li… [vLAR Group] (2026)
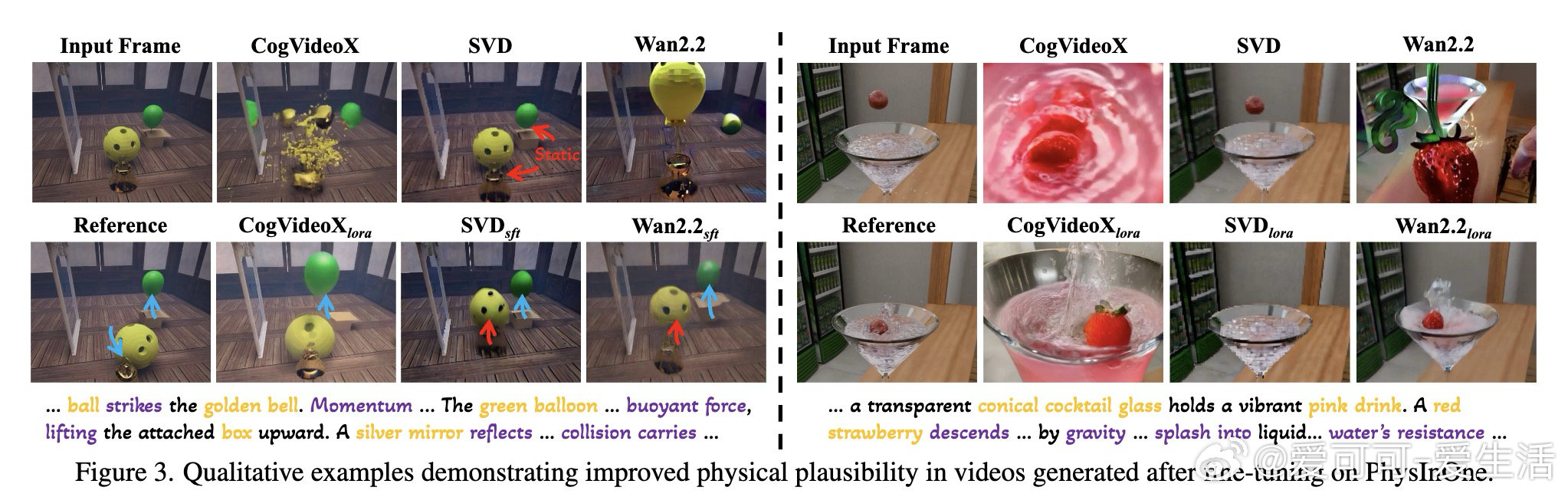
在视频生成与物理推理领域,AI模型普遍缺乏真正理解物理规律的能力——生成的视频中物体会向上坠落、速度无故突变。根本原因在于:现有训练数据最多仅涵盖数千个样本,且局限于简化场景与单一物理现象,无法为模型提供学习真实物理世界所需的规模与多样性。
本文的核心洞见是:把"物理法则"重新看作可编程的场景生成规范。通过将71种日常物理现象(力学、光学、流体、磁力)系统化地编排为15.38万个多物体、多物理量交互的三维场景,并以13路摄像机同步录制,最终产出200万条带精确标注的动态视频——其规模比此前最大同类数据集高出数个量级。
这项工作真正留下的遗产,是为物理感知世界模型的训练提供了一套工业级基础设施,并用PMF(物理运动保真度)这一新指标替代了无法衡量物理合理性的传统像素级评估。它为后来者打开的新门是:在视频生成、未来帧预测、物理属性估计等任务上建立了可量化的基准起点。但尚未跨过的门槛是:复杂多体动力学建模与内在物理属性的精确估计,现有方法在面对真实复杂场景时仍远未达标。
arxiv.org/abs/2604.09415
机器学习 人工智能 论文 AI创造营