[LG]《Zero-shot World Models Are Developmentally Efficient Learners》K L Aw, K Kotar, W Lee, S Kim… [Stanford University] (2026)
在视觉认知领域,如何从一个孩子有限的第一人称经验中涌现出深度感知、物体追踪、直觉物理等多种能力,是一个悬而未决的难题。现有的自监督视觉模型在婴儿级别的数据上训练后,性能远不及在精心策划的大规模数据集上训练的同类模型,且每项下游任务都需要额外的标注训练,使其既不高效也不灵活。
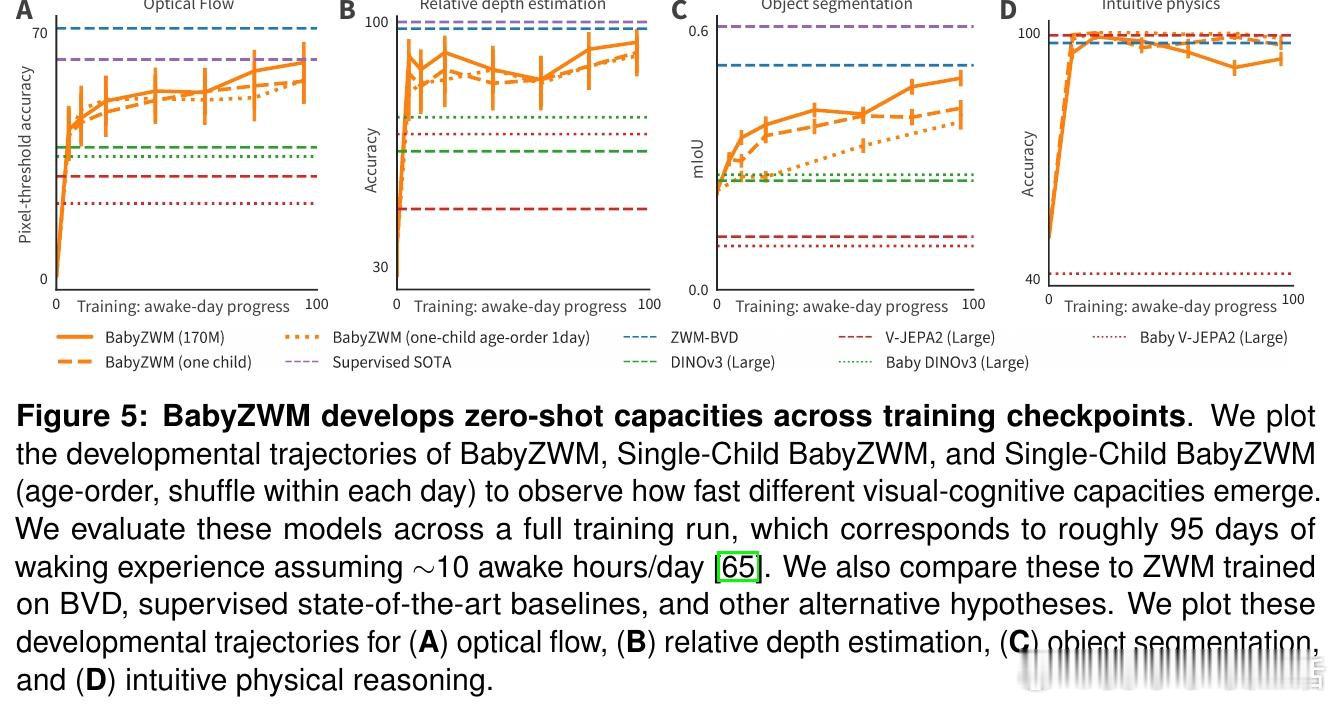
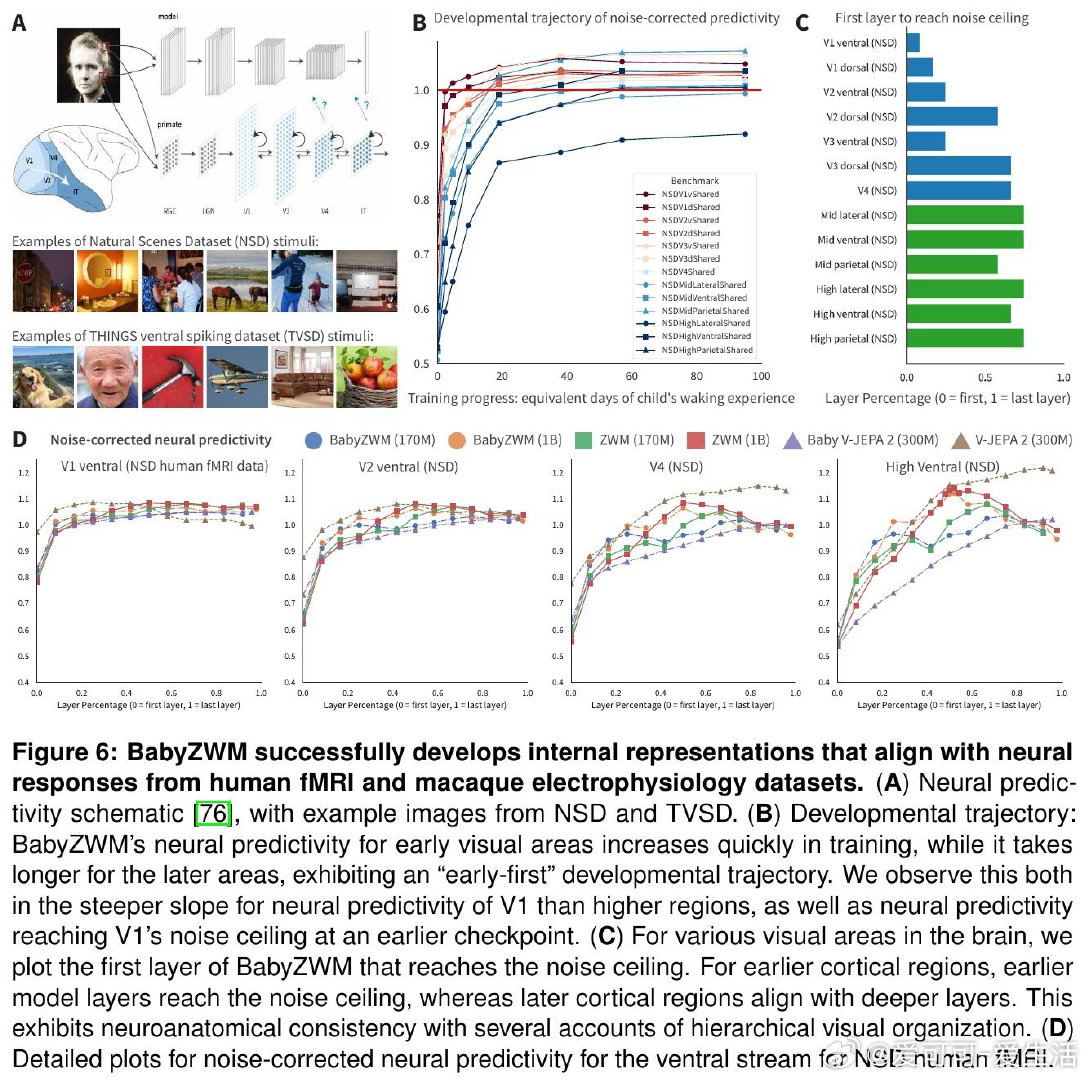
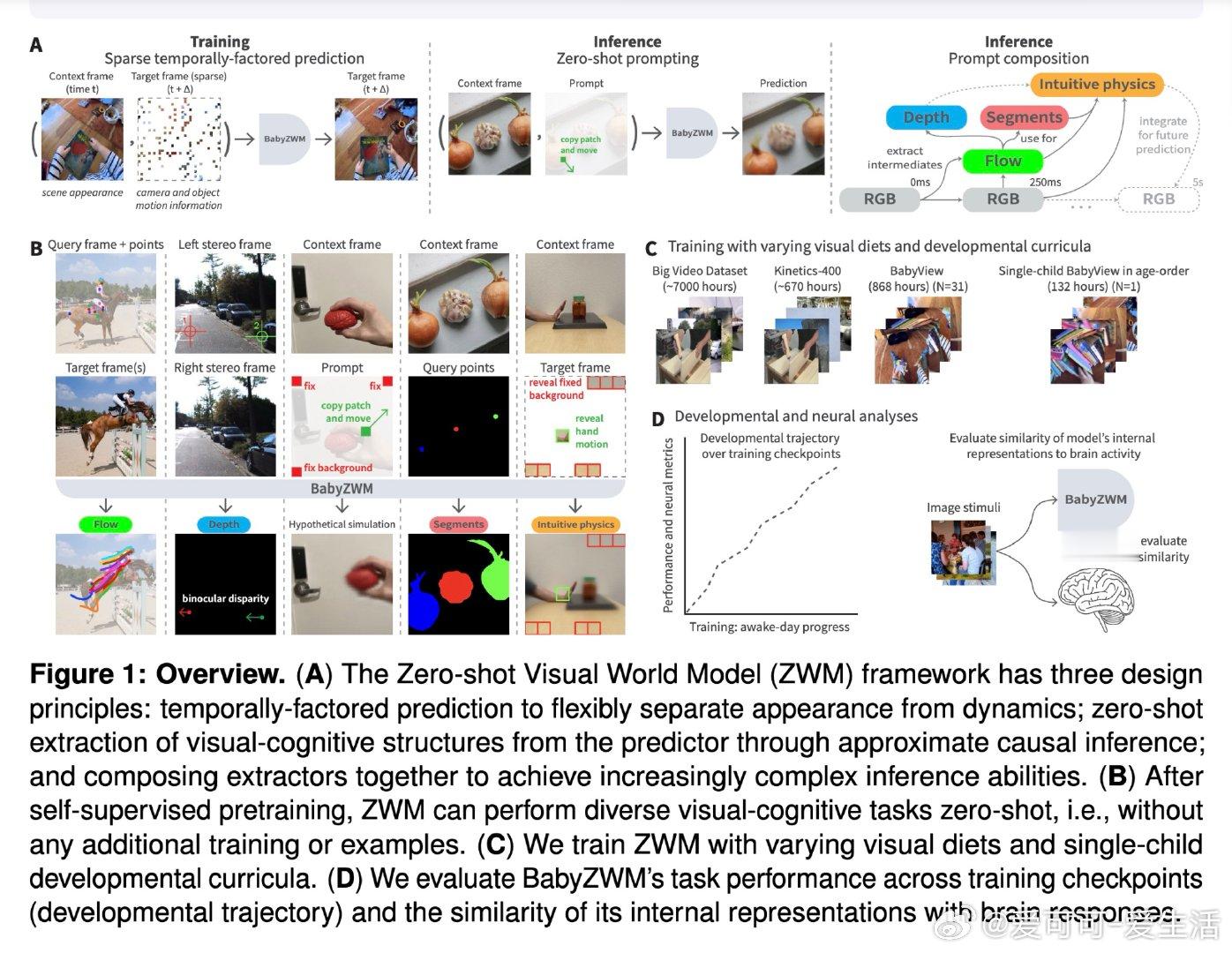
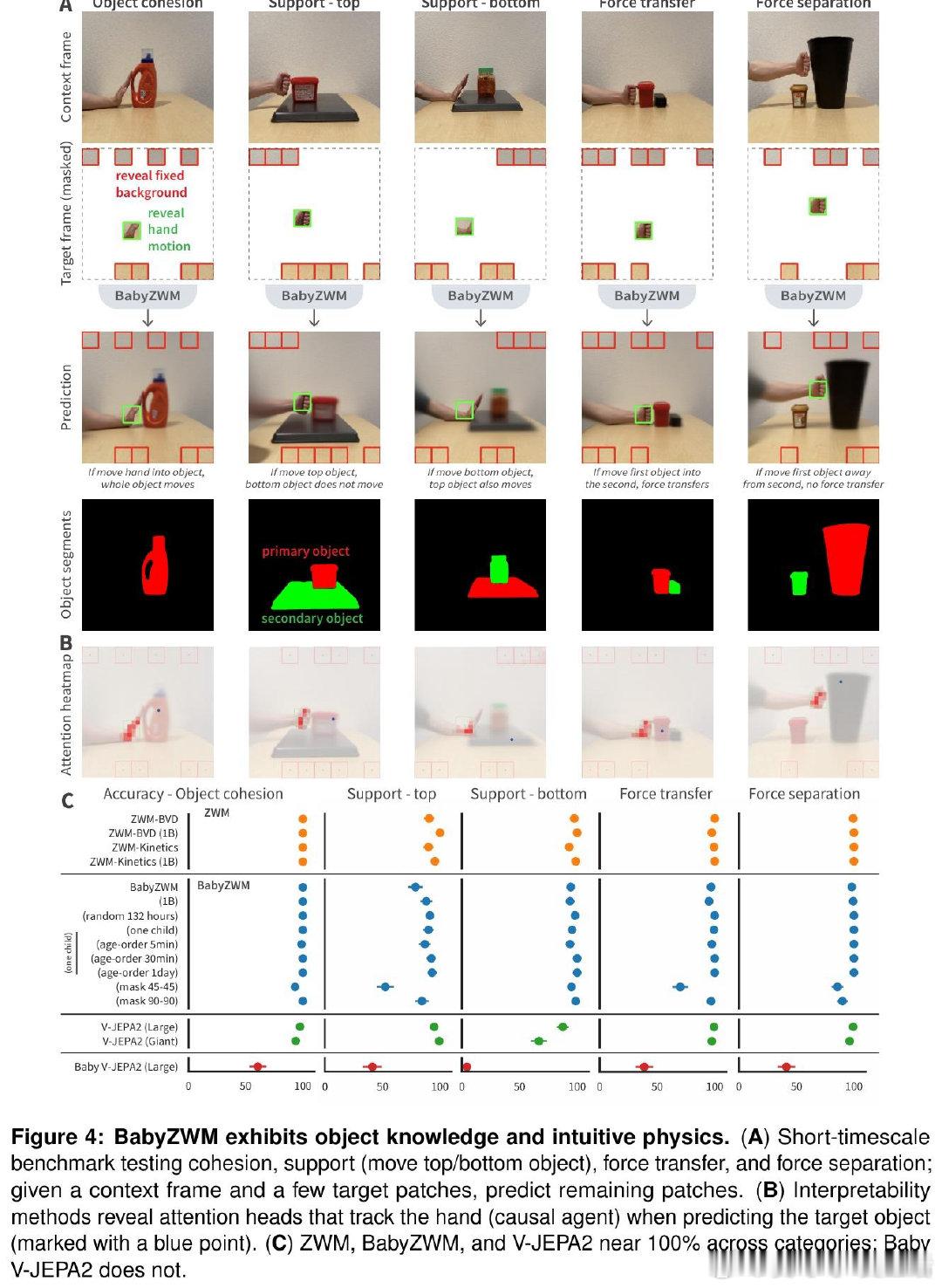
本文的核心洞见是:把"预测下一帧"重新看作一种因果推断的接口。通过让模型在完整可见的第一帧与高度遮蔽的第二帧之间进行预测,模型被迫将外观与运动解耦;之后,对输入做最小扰动并比较输出差异,即可零样本地"套取"出光流、深度、物体分割等视觉量,而无需任何额外标注。这些简单提取可进一步组合,构建出直觉物理等更复杂的推断。
这项工作真正留下的遗产是:证明了正确的归纳结构(而非海量数据)才是视觉认知高效涌现的关键——仅用一名儿童132小时的日常录像,即可在多项基准上媲美有监督专用模型。它为后来者打开的新门是:视觉版"大语言模型式"零样本泛化在远小于语言模型的数据量下即可实现,为机器人、医疗影像等标注稀缺领域提供了新路径。但尚未跨过的门槛是:该框架尚不涉及语义概念的发展,且作为确定性回归模型,在未来不确定时会产生模糊预测,难以支撑长时程规划。
arxiv.org/abs/2604.10333
机器学习 人工智能 论文 AI创造营