[LG]《Solving Physics Olympiad via Reinforcement Learning on Physics Simulators》M Prabhudesai, A Satpathy, Y Li, Z Qin… [CMU & Lambda] (2026)
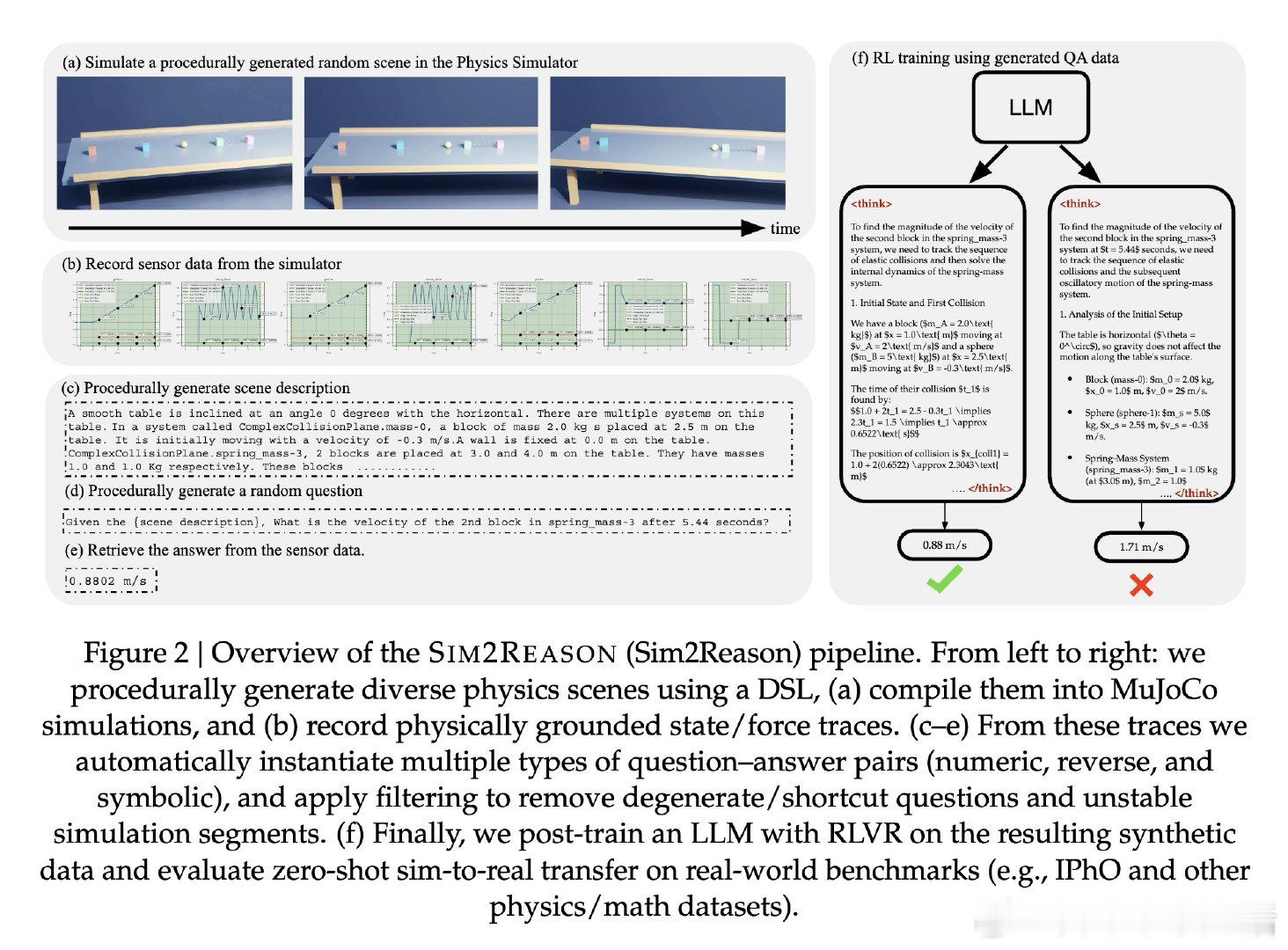
物理推理数据的获取是训练大语言模型的真实瓶颈:互联网上的题库有限且分布不均,DeepSeek-R1所用的80万条训练数据中物理题占比不足1%,导致模型在物理奥林匹克题目上表现欠佳。过去借助模拟器的方案要求模型自行生成仿真代码,但准确率极低,根本无法规模化。
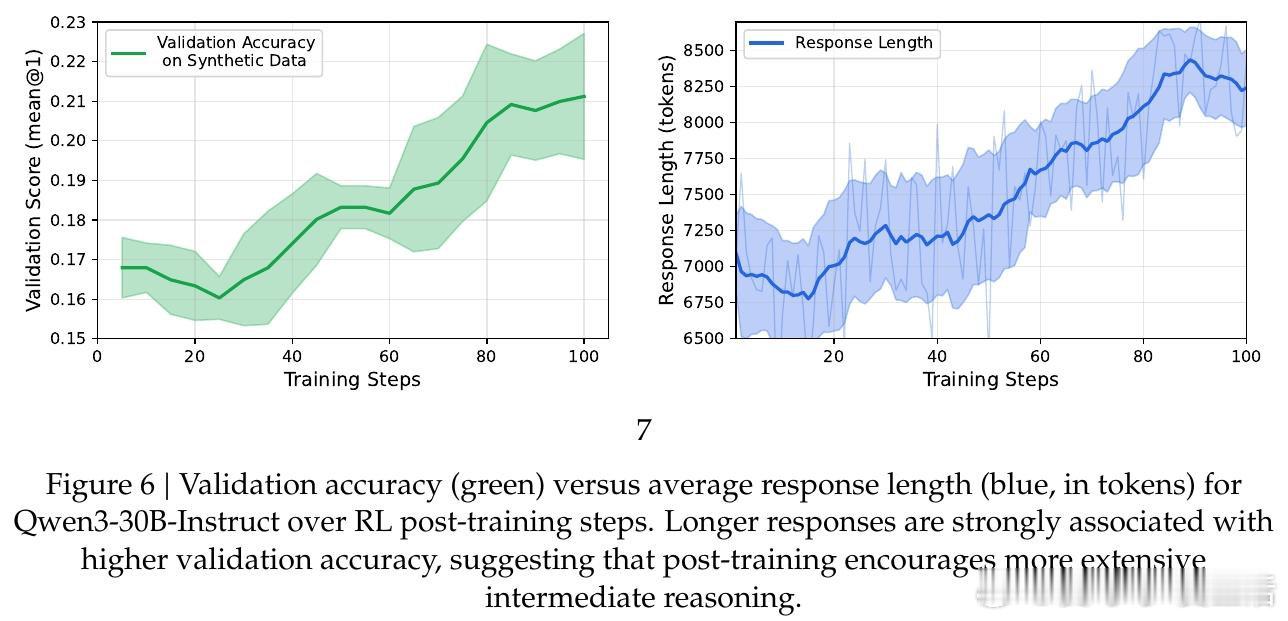
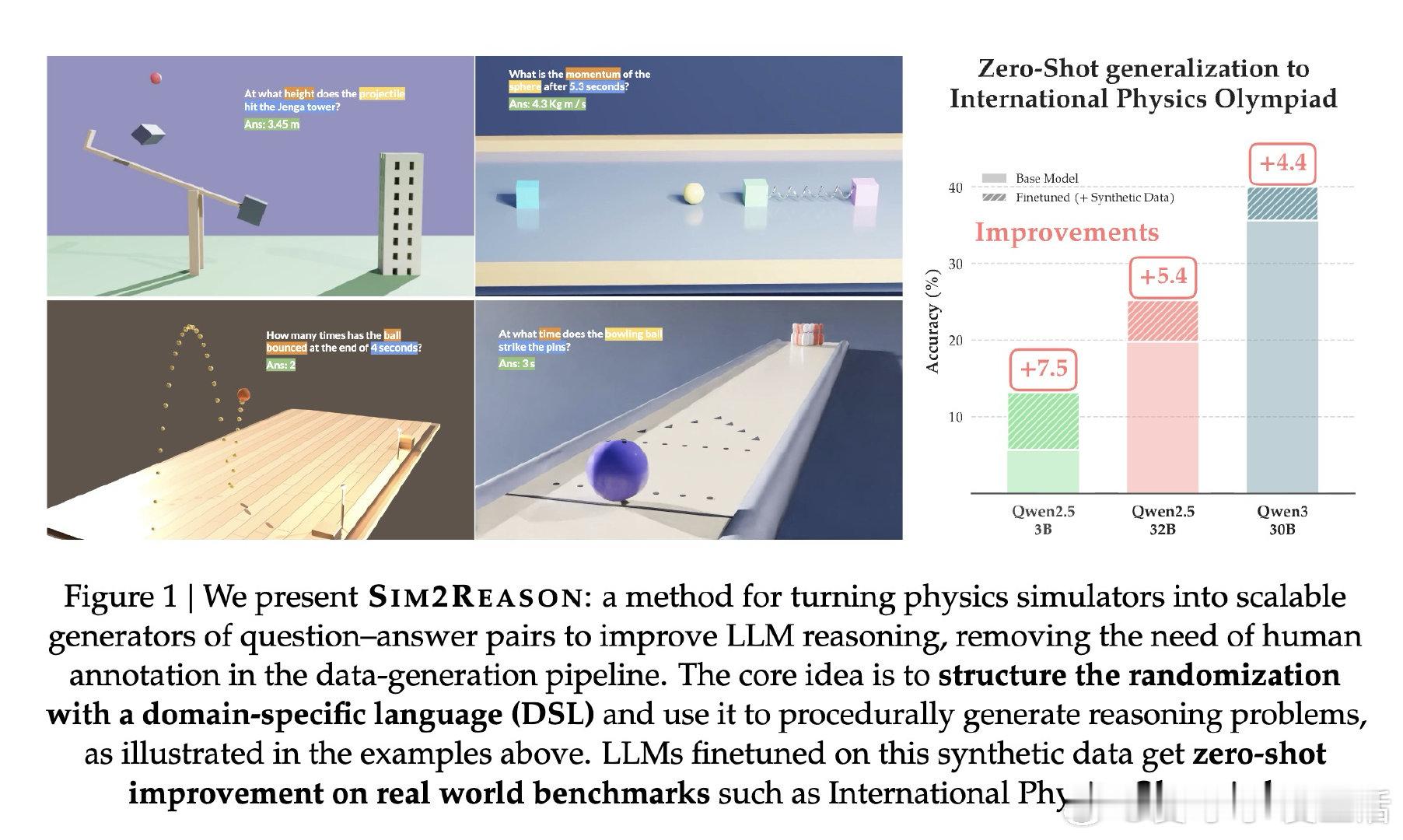
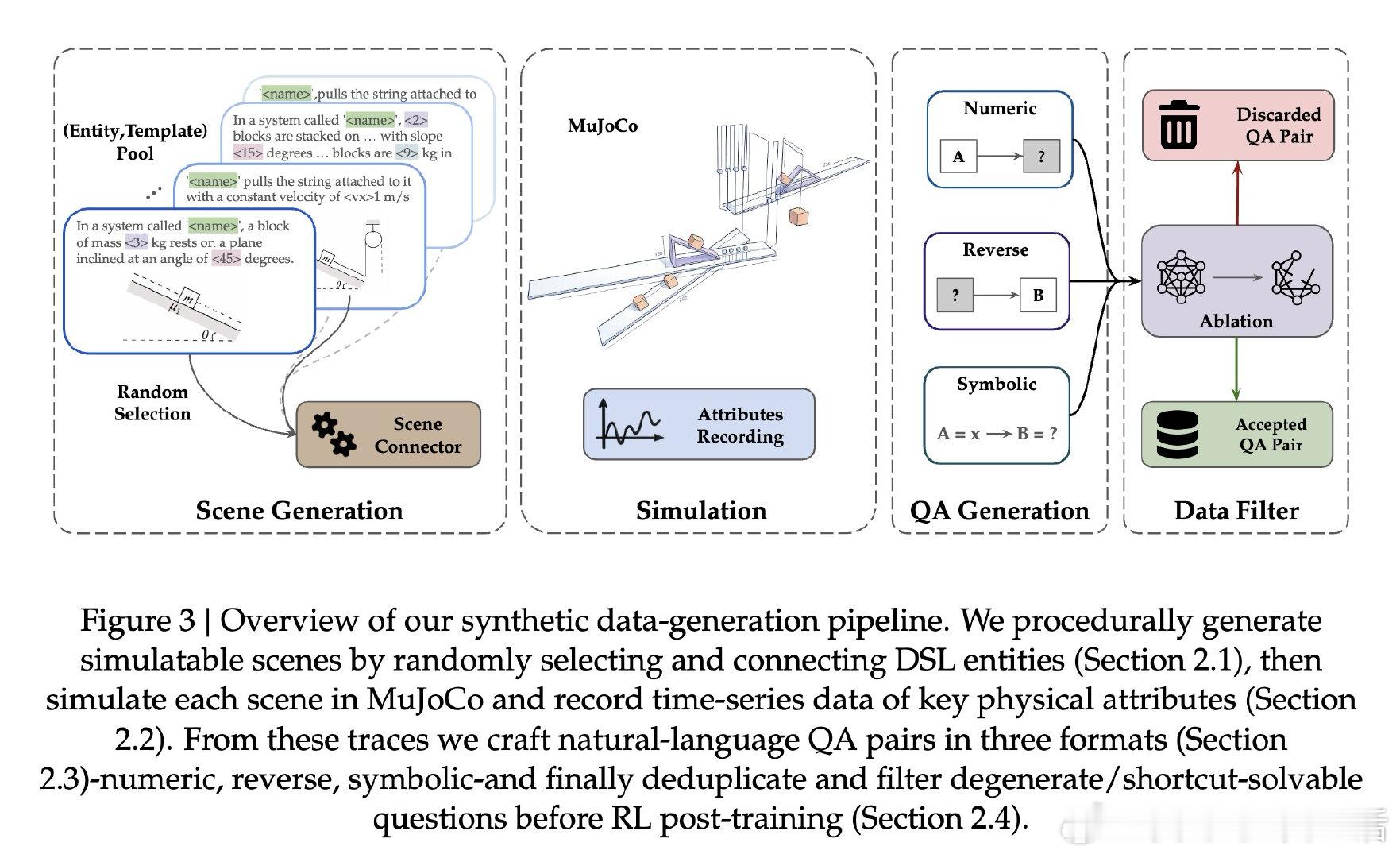
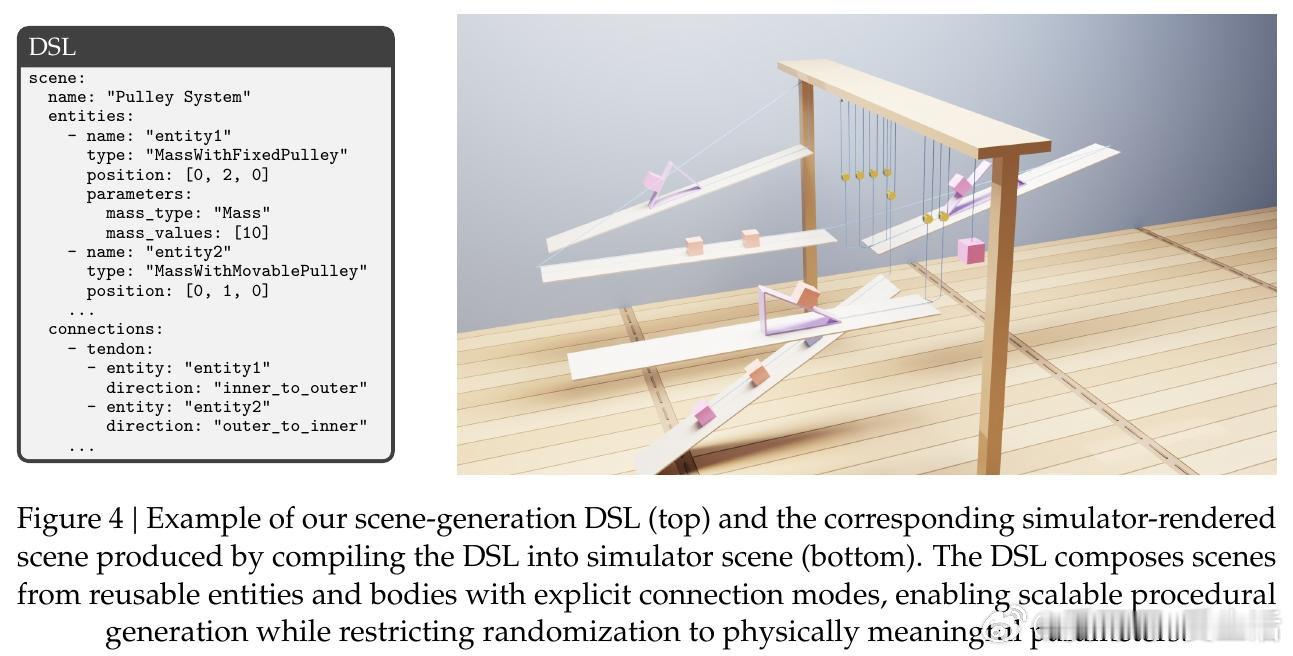
本文的核心洞见是:把物理模拟器重新看作一台可无限运转的出题机,而非外部工具。由此,用领域专用语言(DSL)结构化描述场景、自动提取仿真轨迹生成题目、再用强化学习(RLVR)以"答案误差5%内"为奖励信号训练模型——这一关键操作链使数据稀缺问题得以绕过,让模型在从未见过真实物理题目的前提下完成训练。
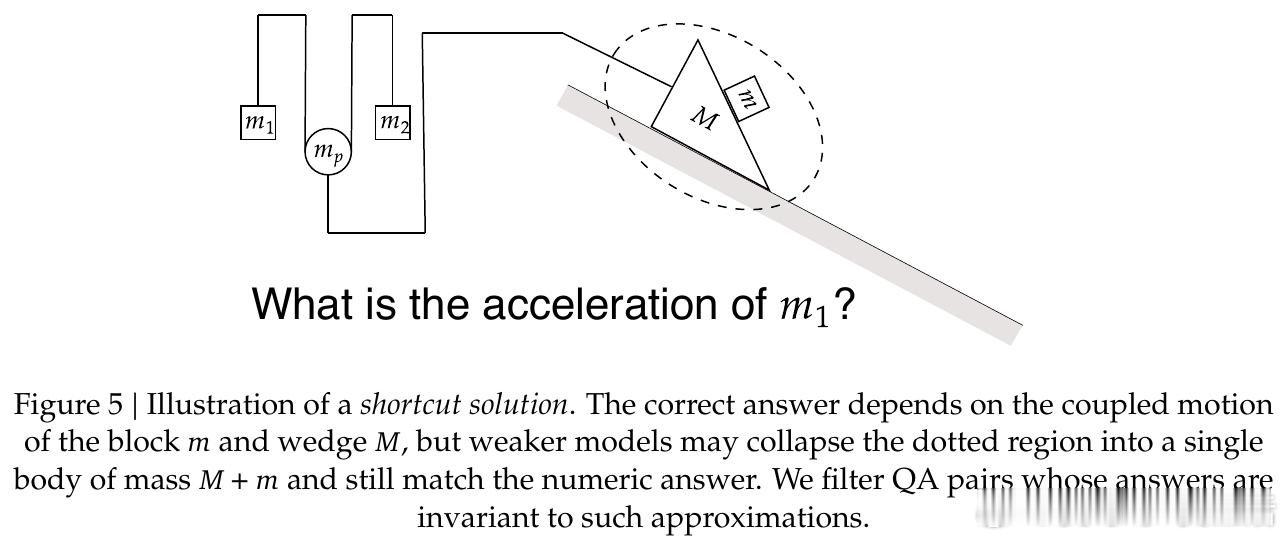
这项工作真正留下的遗产是:证明物理模拟器可以替代人工标注,成为科学推理的可扩展监督信号源——仅凭合成数据便在国际物理奥林匹克上提升5~10个百分点。它为后来者打开的新门是:将这一范式推广到电磁学、热力学乃至其他实验科学。但尚未跨过的门槛是:当前DSL覆盖的场景类型有限,模拟器的物理保真度终究存在边界,模型究竟内化了多少真实的物理直觉,仍难以证伪。
arxiv.org/abs/2604.11805
机器学习 人工智能 论文 AI创造营