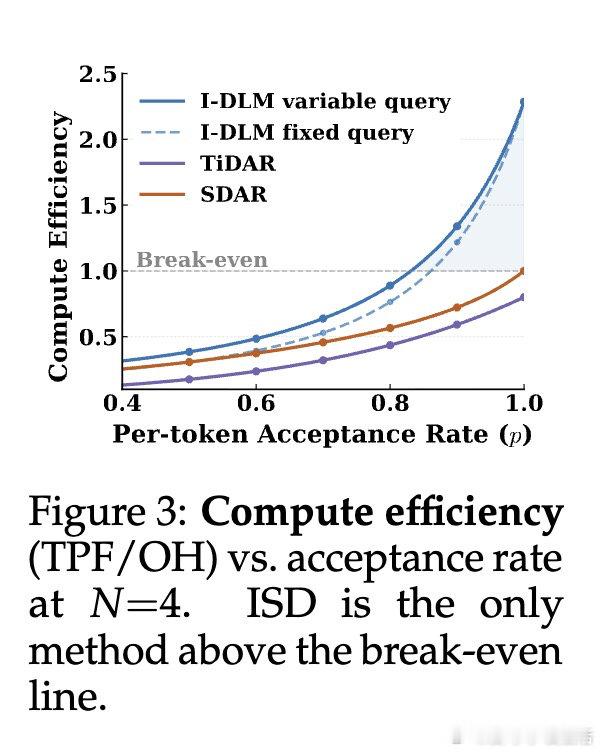
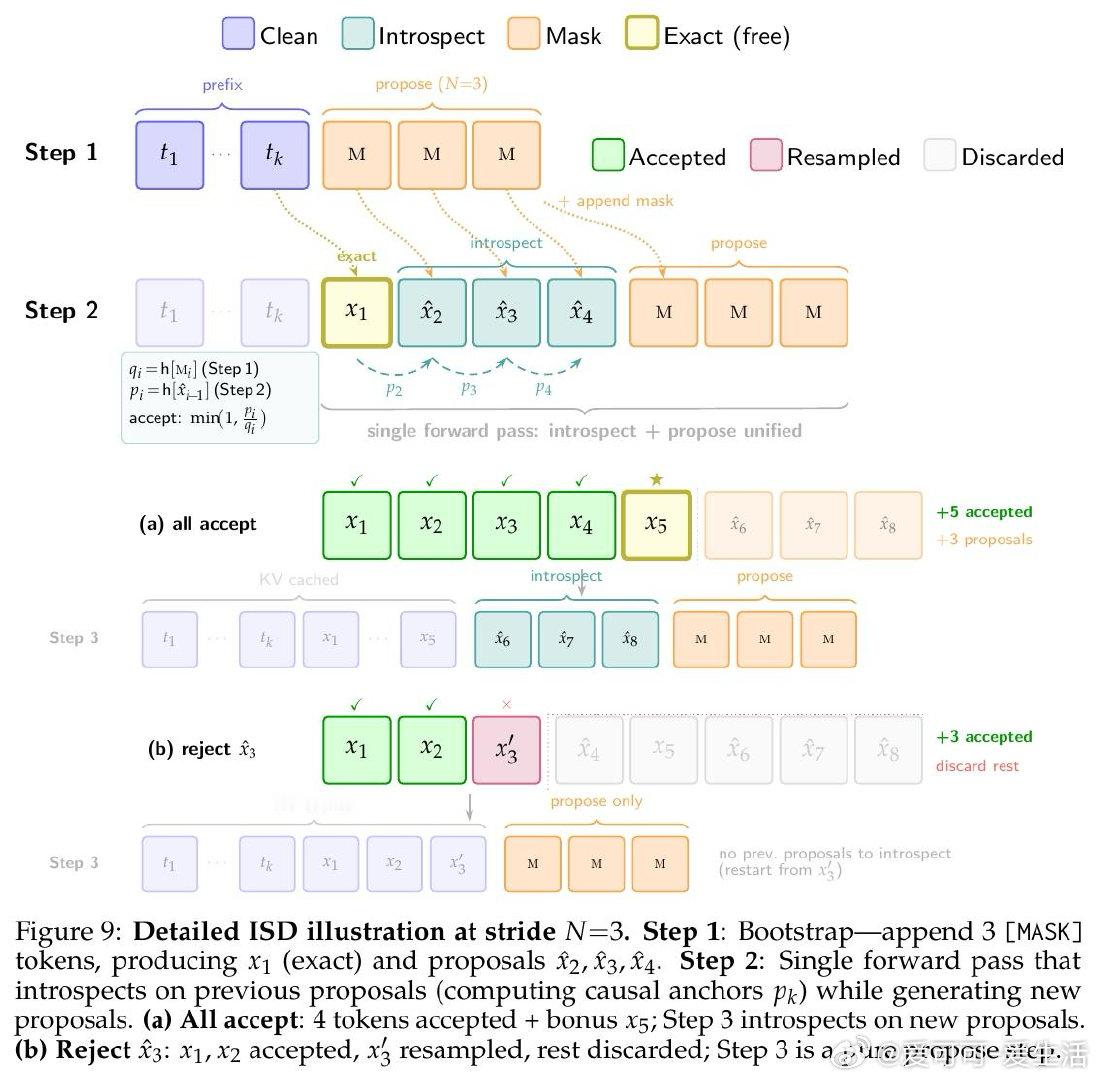
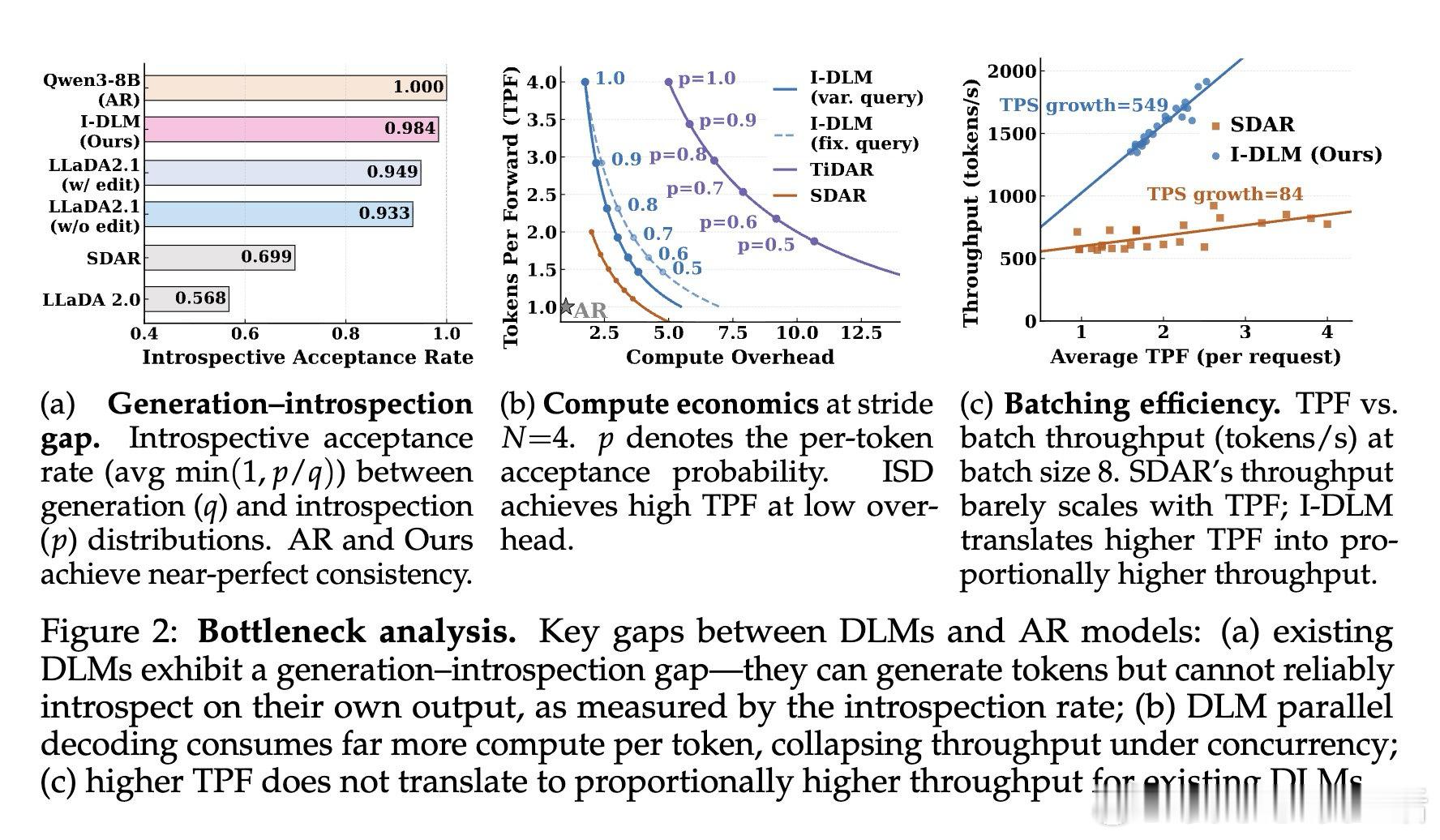
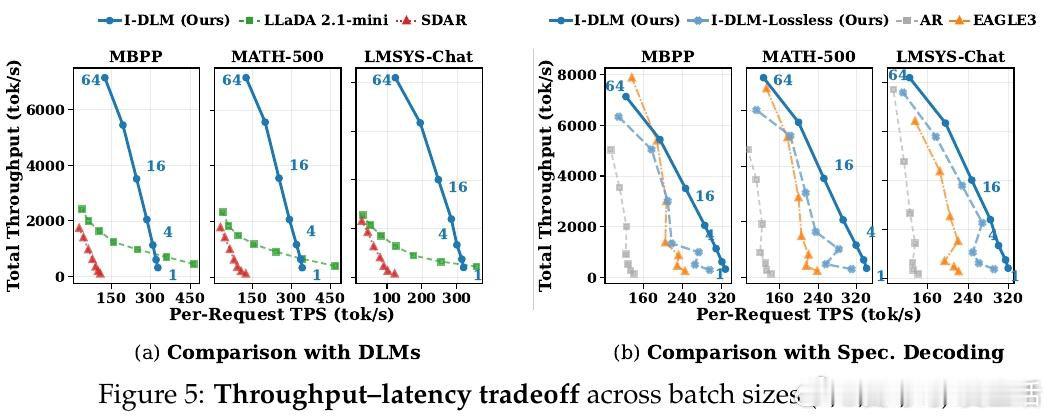
[LG]《Introspective Diffusion Language Models》Y Yu, Y Jian, J Wang, Z Zhou… [Together AI] (2026)
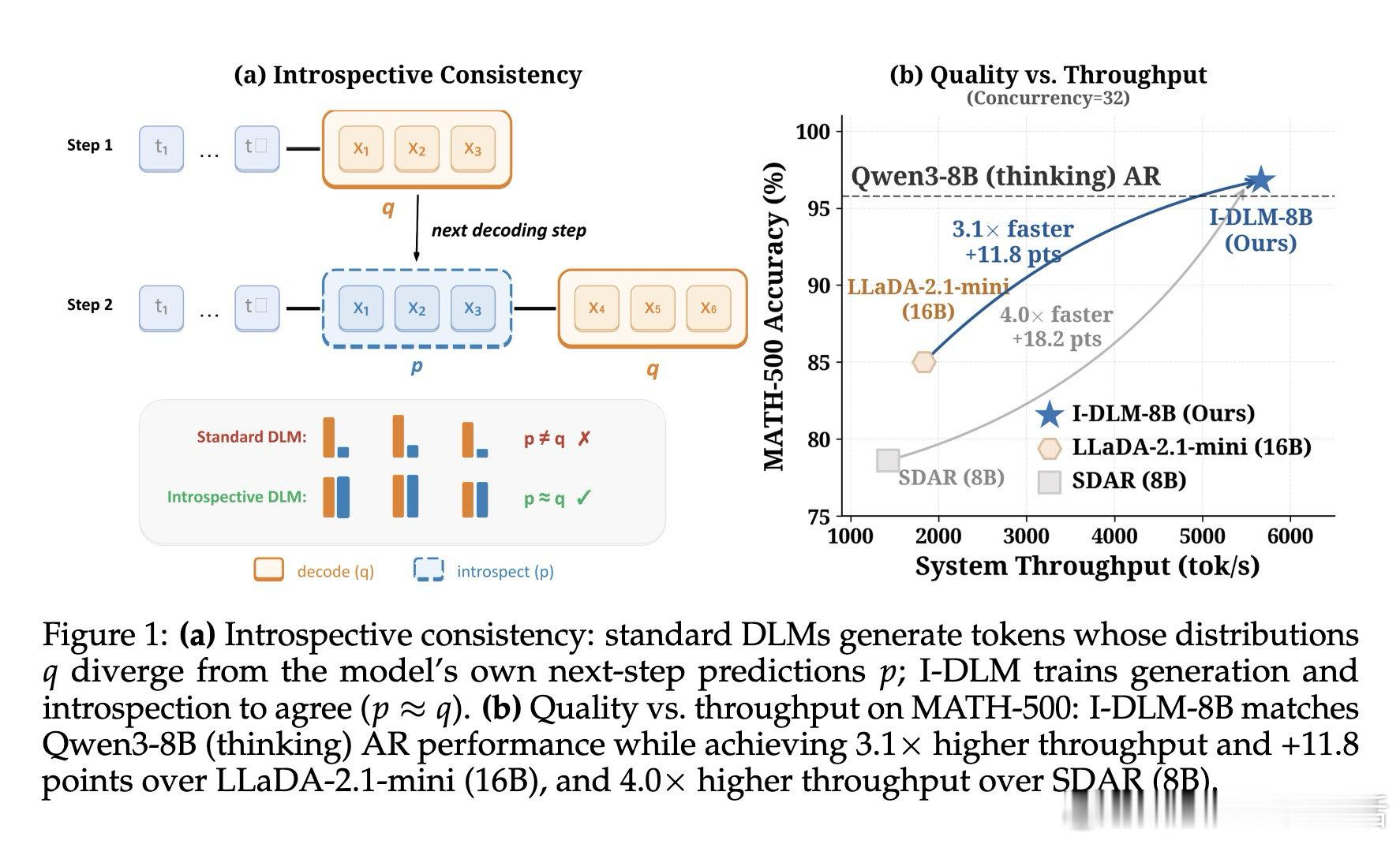
在扩散语言模型领域,"并行生成"这一承诺长期落空——即便能并行解码,生成质量始终与自回归模型存在显著差距。过去的方法受困于一个被忽视的根本缺陷:模型生成的token与它自身"反思"时认可的token之间存在分布鸿沟,本质原因是双向去噪训练从未教会模型认可自己的输出。
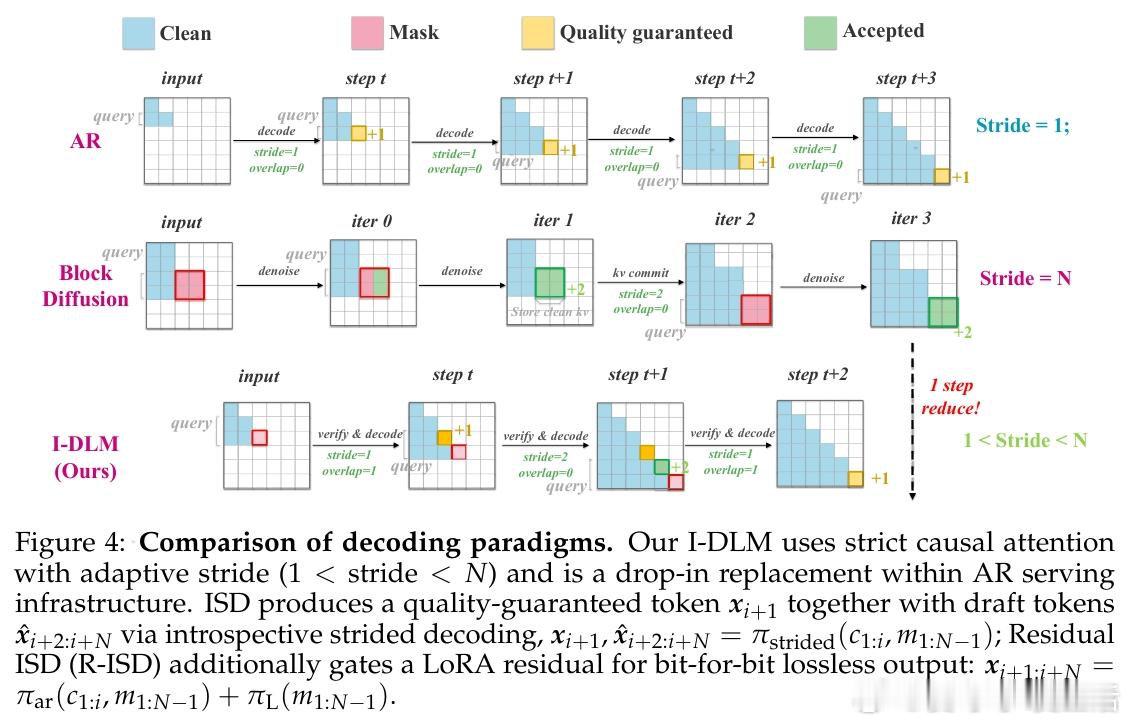
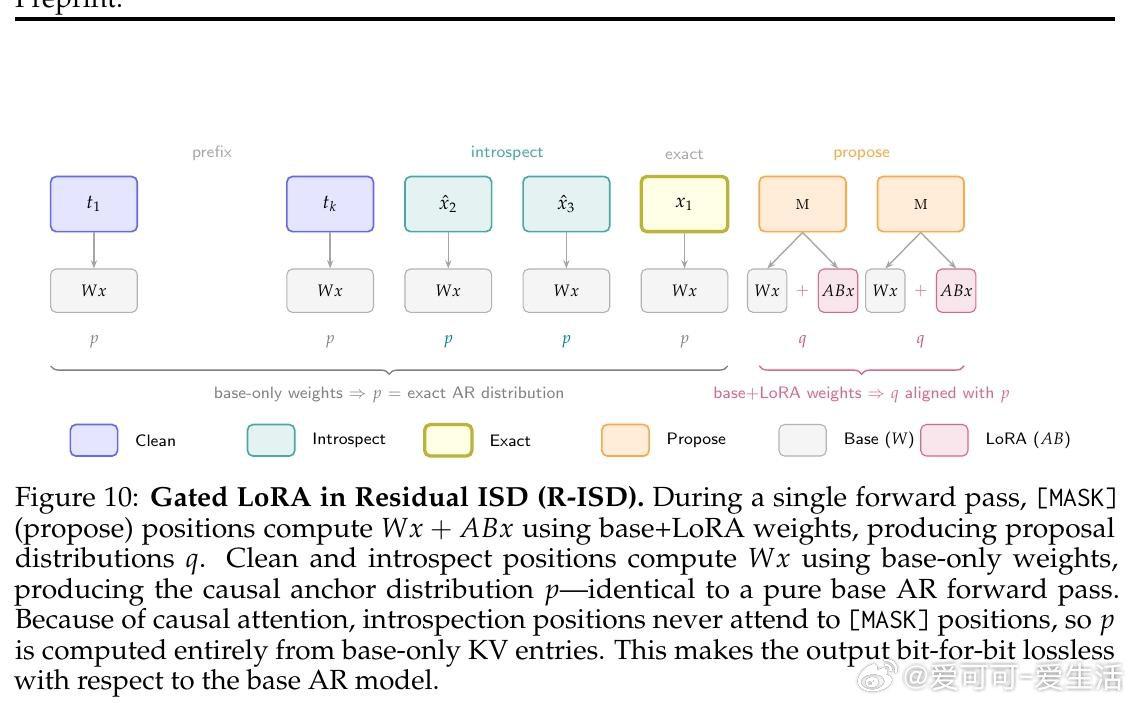
本文的核心洞见是:把"让模型同意自己的生成"重新看作训练目标而非评估指标。由此,将因果掩码+logit偏移+全遮掩训练三者合一这一关键操作,使模型在单次前向传播中同时完成生成与自省——生成位置输出候选token,干净位置输出因果锚点分布用于验证,二者天然对齐。
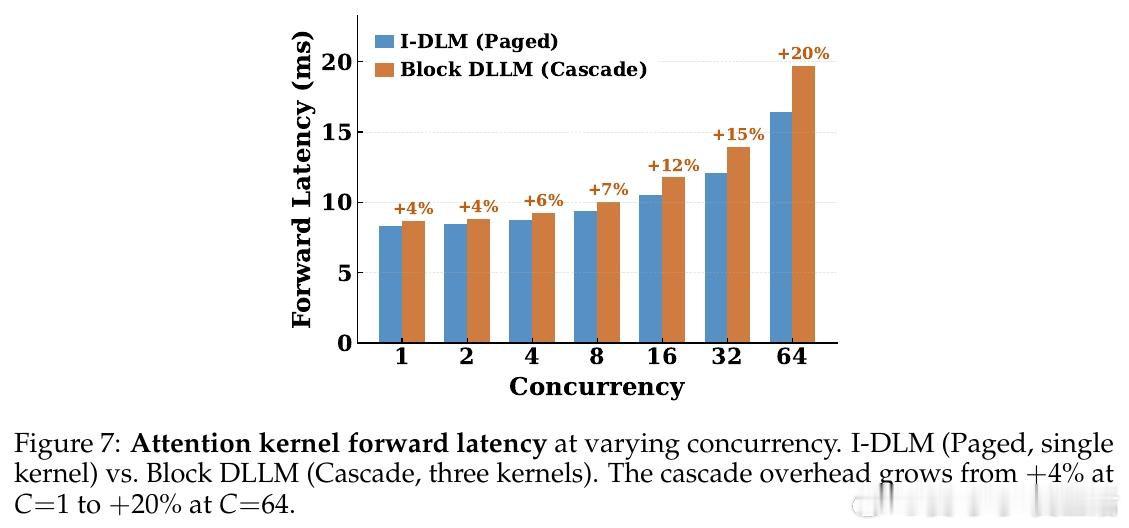
这项工作真正留下的遗产是:证明了扩散模型的质量瓶颈源于"自洽性缺失"而非架构本身,并以4.5B token的极低训练代价填平了与自回归模型的质量鸿沟。它为后来者打开的新门是一条将现有AR模型低成本转化为高质量并行生成模型的可复现路径;但尚未跨过的门槛是:当并发规模进一步扩大时,自适应步长机制的理论加速上界能否稳定兑现,仍有待更大规模的工程验证。
arxiv.org/abs/2604.11035
机器学习 人工智能 论文 AI创造营