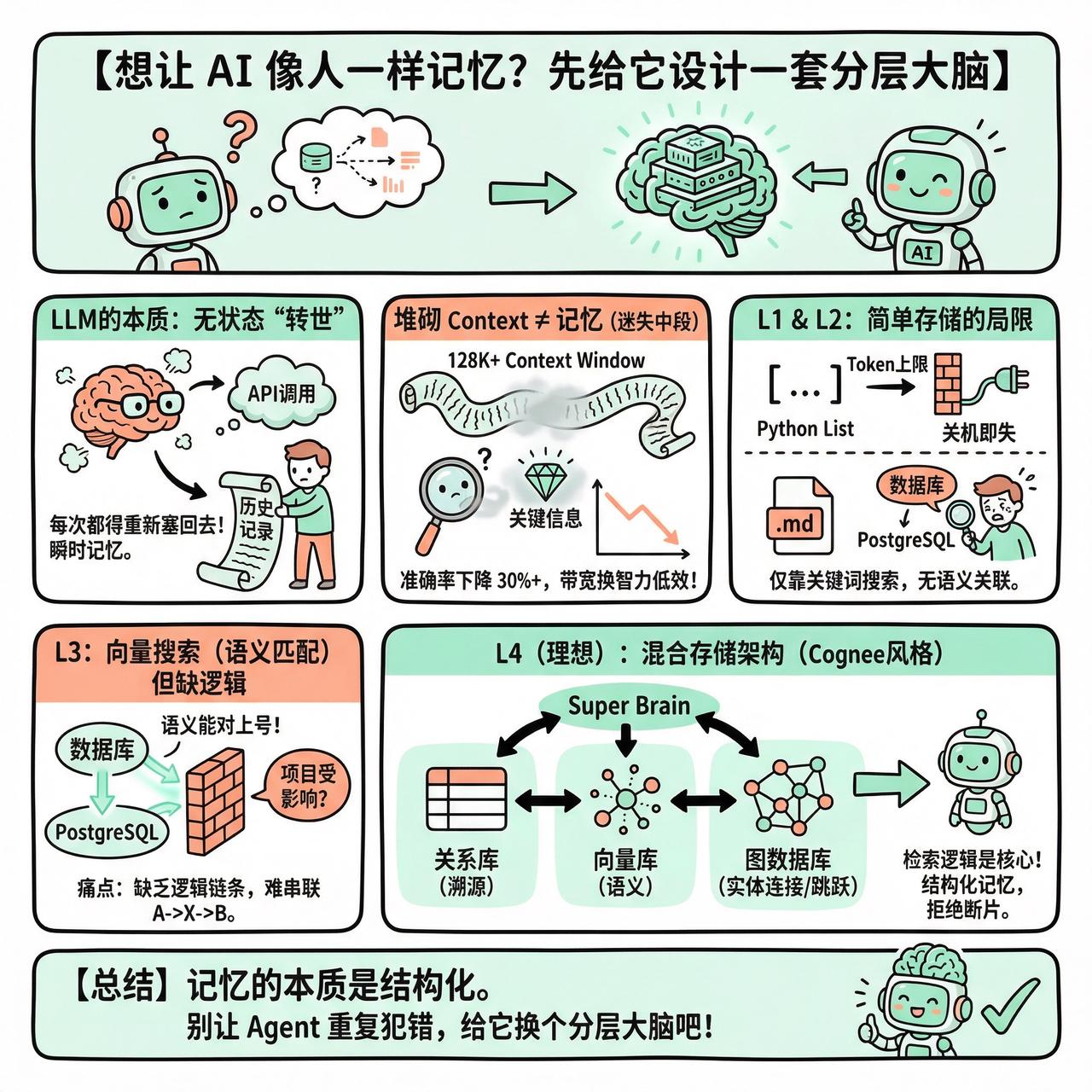
【想让 AI 像人一样记忆?先给它设计一套分层大脑】
快速阅读:LLM 本质是无状态的,所谓的“对话记忆”只是重复发送历史记录。要构建真正的 Agent,不能靠堆砌 Context 长度,而需要建立包含关系、语义和持久化的混合存储架构。
现在的 LLM 就像一个只有瞬时记忆的聪明人,每一次 API 调用都是一次“转世”。你觉得它记得你,其实是因为你在每次请求时都把之前的聊天记录重新塞了回去。这种做法在简单的闲聊里没问题,但一旦进入复杂的任务流,Agent 就会开始频繁“断片”:问它昨天说了什么,它一脸茫然;遇到多步任务,中间状态直接丢失。
很多人觉得增加 Context Window(比如 128K 甚至更高)就能解决问题。这其实是在用带宽换智力,非常低效。研究表明,当关键信息被埋在长文本中间时,模型的准确率会下降 30% 以上,这就是著名的“迷失中段”效应。
要把 Agent 做得像人一样有记忆,得按层级来构建:
最原始的方案是用 Python List 存历史。这能实现多轮对话,但随着列表增长,你会撞上 Token 上限,而且程序一关,记忆全丢。
进阶一点,把记忆写进 Markdown 文件。这样有了持久化,哪怕重启了也能找回上下文。但问题在于,当文件变成几千行时,你只能靠关键词搜索。如果用户问“数据库出故障了吗?”,而你的记录里写的是“PostgreSQL 宕机了”,由于没有语义关联,Agent 就搜不到。
最后是向量搜索(Vector Search)。它解决了语义匹配的问题,让“数据库”和“PostgreSQL”能对上号。但它会遇到一个更隐蔽的墙:缺乏逻辑链条。如果事实 A 是“Alice 负责项目 X”,事实 B 是“项目 X 使用了 PostgreSQL”,当用户问“Alice 的项目受影响了吗?”时,向量搜索往往能找到 A 和 B,却很难把它们通过中间的“项目 X”串联起来。
真正的记忆需要的是一种“混合架构”。有网友提到,单纯靠存储是不够的,检索逻辑才是核心。一个理想的系统应该像 Cognee 这样的架构:用关系型数据库管溯源,用向量库管语义,用图数据库(Graph)管实体间的连接。
这种结构能让 Agent 在检索时既能通过语义“定位”,又能通过图谱“跳跃”。当它发现某个知识点被频繁引用时,还可以通过优化算法强化这条路径。
记忆的本质不是堆积,而是结构化。如果你的 Agent 还在重复犯同样的错误,或许该考虑给它换个“大脑层级”了。
x.com/akshay_pachaar/status/2043745099792953508