[CL]《CROP: Token-Efficient Reasoning in Large Language Models via Regularized Prompt Optimization》D Shah, S Badhe, N Kathrotia, P Tiwari [Google LLC & Purdue University] (2026)
在推理型大模型领域,冗余的中间步骤是一个悬而未决的难题。过去的方法受困于"准确率即一切"的单目标优化框架,本质原因是缺乏一个对应于输出长度的文本空间惩罚项——模型越努力推理,就越倾向于堆砌废话。
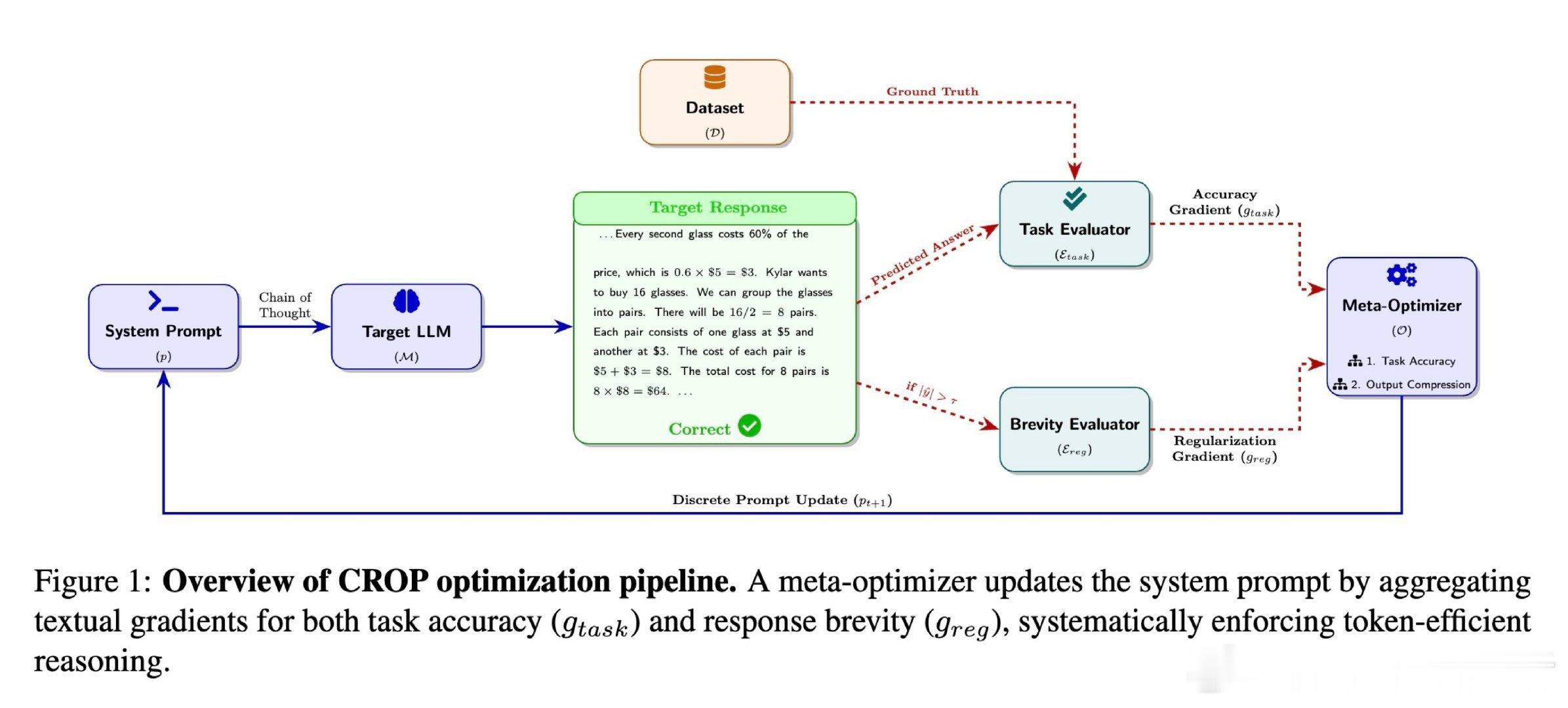
本文的核心洞见是:把"简洁"重新看作一个可以被梯度化的优化目标,而非人工编写的约束。由此,将长度惩罚梯度与准确率梯度拼接后送入元优化器这一关键操作,使提示词自动进化出如"8×5 + 8×3 = 64"这样的符号化推理路径,而非绵延的文字解说。
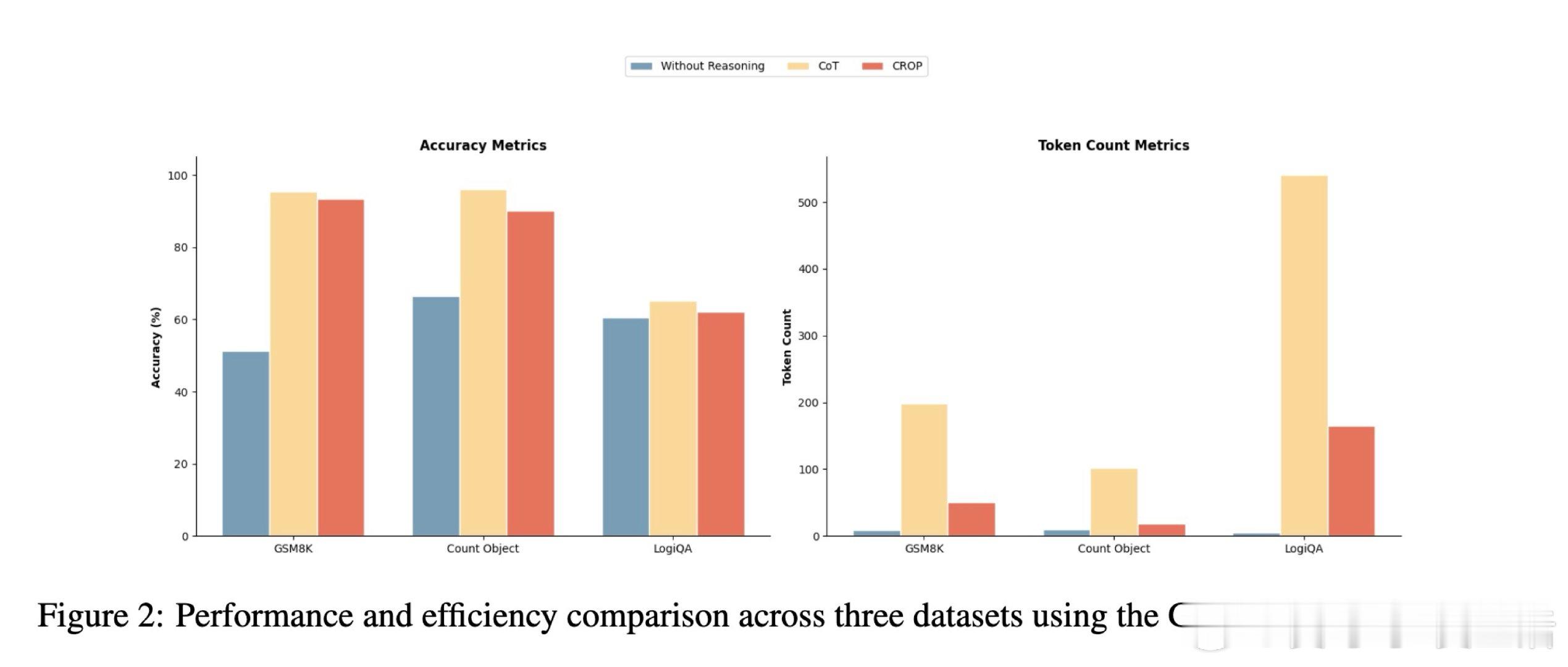
这项工作真正留下的遗产是:证明了推理冗余是可以被系统性蒸馏的,无需改动模型权重,仅在提示层即可实现80.6%的token压缩。它为后来者打开的新门是:自动发现类似"Chain-of-Draft"的高效推理语法,而无需人工设计;但尚未跨过的门槛是:优化阶段仍依赖顶级推理模型(如Gemini 3.1 Pro),中小规模元优化器能否胜任这一双目标任务,尚无定论。
arxiv.org/abs/2604.14214
机器学习 人工智能 论文 AI创造营