刚试了下,GPT-5.5 这次真正的变化,不是“更会聊天”,而是“更会干活”。
看几个数据:
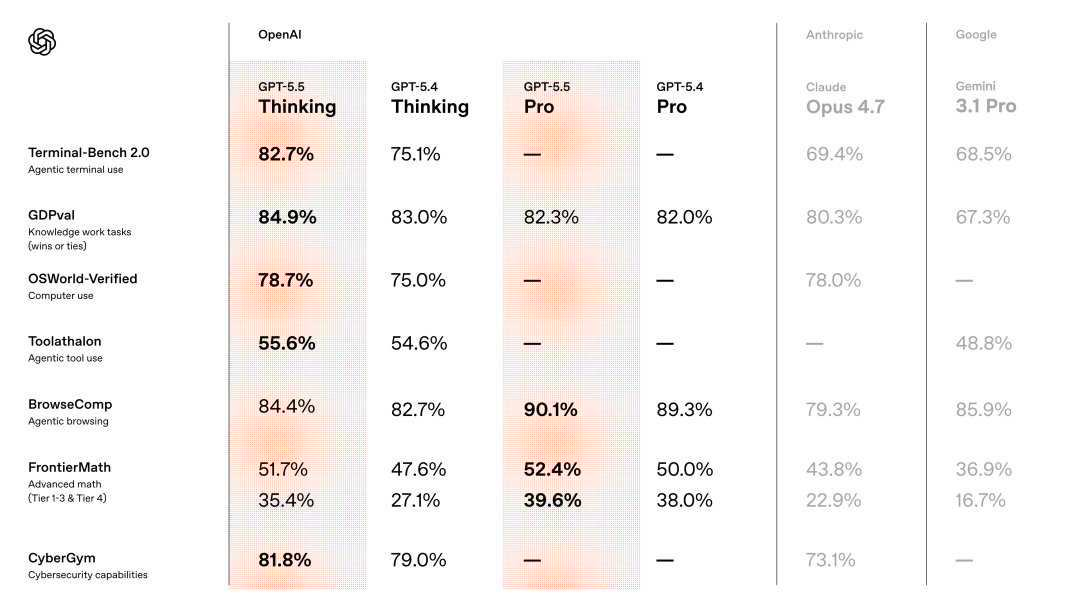
📮Terminal-Bench 2.0,GPT-5.5 是 82.7%,Claude Opus 4.7 是 69.4%。这个测的是命令行、调试、工具调用、多步骤执行,所以 GPT-5.5 在“自己把活推进下去”这件事上很强。 
📮SWE-Bench Pro,GPT-5.5 是 58.6%,Claude Opus 4.7 是 64.3%,智谱 GLM-5.1 是 58.4%。也就是说,纯软件工程修 bug 这个战场,Claude Opus 4.7 依然非常强,GLM-5.1 也已经追到了全球第一梯队。 
📮GDPval,GPT-5.5 是 84.9%;OSWorld-Verified,GPT-5.5 是 78.7%。这两个更接近真实办公和操作电脑,不是答题,而是做事。 
所以我的判断是:
Claude Opus 4.7 还是最强程序员之一,尤其是复杂代码、工程质量、长代码库理解,非常适合严肃开发。
智谱 GLM-5.1 最值得尊重,它不是“国产能用”,而是在 SWE-Bench Pro 这种硬指标上已经和 GPT-5.5 咬住了。
GPT-5.5 的优势是更全能。它不只是写代码,而是把代码、资料、网页、电脑操作、知识工作这些东西串起来,更像一个能连续推进任务的 Agent。
以前大模型比的是“谁更聪明”。
现在开始比“谁更能交付”。
这就像辅助驾驶,不能只看某一个路口过得漂不漂亮,要看它从地库到目的地,中间遇到闸机、施工、绕行、拥堵,还能不能稳稳开完。
GPT-5.5 这次的意义就在这儿:它不是单点能力爆炸,而是长链路稳定性变强了。
但我也不觉得它是碾压式领先。
写代码,Claude Opus 4.7 仍然非常顶。
开源和工程性,智谱 GLM-5.1 已经很有威胁。
综合生产力,GPT-5.5 目前最像“能干活的人”。
所以以后选模型,不应该问“谁最强”,而应该问:
你是要一个程序员,还是要一个全能助理,还是要一个性价比极高、能部署、能改造的工程模型。